








锁屏面试题百日百刷,每个工作日坚持更新面试题。锁屏面试题app、小程序现已上线,官网地址:https://www.demosoftware.cn。已收录了每日更新的面试题的所有内容,还包含特色的解锁屏幕复习面试题、每日编程题目邮件推送等功能。让你在面试中先人一步!接下来的是今日的面试题:
1.描述HBase的rowKey的设计原则?
① Rowkey长度原则
Rowkey 是一个二进制码流,Rowkey 的长度被很多开发者建议说设计在10~100 个字节,不过建议是越短越好,不要超过16 个字节。
原因如下:
(1)数据的持久化文件HFile 中是按照KeyValue 存储的,如果Rowkey 过长比如100 个字节,1000 万列数据光Rowkey 就要占用100*1000 万=10 亿个字节,将近1G 数据,这会极大影响HFile 的存储效率;
(2)MemStore 将缓存部分数据到内存,如果Rowkey 字段过长内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。因此Rowkey 的字节长度越短越好。
(3)目前操作系统是都是64 位系统,内存8 字节对齐。控制在16 个字节,8 字节的整数倍利用操作系统的最佳特性。
② Rowkey散列原则
如果Rowkey 是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个Regionserver 实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个 RegionServer 上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别RegionServer,降低查询效率。
③ Rowkey唯一原则
必须在设计上保证其唯一性。
2.描述HBase中scan和get的功能以及实现的异同?
HBase的查询实现只提供两种方式:
1)按指定RowKey 获取唯一一条记录,get方法(org.apache.hadoop.hbase.client.Get)
Get 的方法处理分两种 : 设置了ClosestRowBefore 和没有设置ClosestRowBefore的rowlock。主要是用来保证行的事务性,即每个get 是以一个row 来标记的。一个row中可以有很多family 和column。
2)按指定的条件获取一批记录,scan方法(org.apache.Hadoop.hbase.client.Scan)实现条件查询功能使用的就是scan 方式。
(1)scan 可以通过setCaching 与setBatch 方法提高速度(以空间换时间);
(2)scan 可以通过setStartRow 与setEndRow 来限定范围([start,end)start 是闭区间,end 是开区间)。范围越小,性能越高。
(3)scan 可以通过setFilter 方法添加过滤器,这也是分页、多条件查询的基础。
3.请描述HBase中scan对象的setCache和setBatch方法的使用?
setCache用于设置缓存,即设置一次RPC请求可以获取多行数据。对于缓存操作,如果行的数据量非常大,多行数据有可能超过客户端进程的内存容量,由此引入批量处理这一解决方案。
setBatch 用于设置批量处理,批量可以让用户选择每一次ResultScanner实例的next操作要取回多少列,例如,在扫描中设置setBatch(5),则一次next()返回的Result实例会包括5列。如果一行包括的列数超过了批量中设置的值,则可以将这一行分片,每次next操作返回一片,当一行的列数不能被批量中设置的值整除时,最后一次返回的Result实例会包含比较少的列,如,一行17列,batch设置为5,则一共返回4个Result实例,这4个实例中包括的列数分别为5、5、5、2。
组合使用扫描器缓存和批量大小,可以让用户方便地控制扫描一个范围内的行键所需要的RPC调用次数。
Cache设置了服务器一次返回的行数,而Batch设置了服务器一次返回的列数。
假如我们建立了一张有两个列族的表,添加了10行数据,每个行的每个列族下有10列,这意味着整个表一共有200列(或单元格,因为每个列只有一个版本),其中每行有20列。
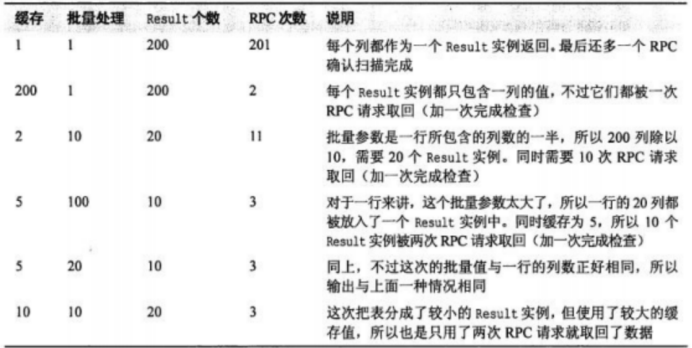
① Batch参数决定了一行数据分为几个Result,它只针对一行数据,Batch再大,也只能将一行的数据放入一个Result中。所以当一行数据有10列,而Batch为100时,也只能将一行的所有列都放入一个Result,不会混合其他行;
② 缓存值决定一次RPC返回几个Result,根据Batch划分的Result个数除以缓存个数可以得到RPC消息个数(之前定义缓存值决定一次返回的行数,这是不准确的,准确来说是决定一次RPC返回的Result个数,由于在引入Batch之前,一行封装为一个Result,因此定义缓存值决定一次返回的行数,但引入Batch后,更准确的说法是缓存值决定了一次RPC返回的Result个数);















 1183
1183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









