 HBase数据导入实战
HBase数据导入实战





 本文详细介绍了一种将HDFS上的数据导入HBase数据库的方法。通过自定义Mapper和Reducer,实现从HDFS读取数据并清洗,然后转换为HBase可接受的格式,最终将数据写入HBase表中。文章提供了完整的代码示例,包括Mapper类ReadDataFromHDFSMapper用于数据读取和清洗,Reducer类WriteHBaseReducer负责将数据写入HBase。
本文详细介绍了一种将HDFS上的数据导入HBase数据库的方法。通过自定义Mapper和Reducer,实现从HDFS读取数据并清洗,然后转换为HBase可接受的格式,最终将数据写入HBase表中。文章提供了完整的代码示例,包括Mapper类ReadDataFromHDFSMapper用于数据读取和清洗,Reducer类WriteHBaseReducer负责将数据写入HBase。
楔子
学习了解 HBase
从HDFS读取数据,导入到HBase,
1.1 构建Mapper读取HDFS数据
import java.io.IOException;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @Title: ReadDataFromHDFSMapper.java
* @Package cn.zhuzi.hbase.mr_hdfs
* @Description: TODO(读取文本数据到HBASE)
* @author 作者
* @version 创建时间:2018年11月5日 下午7:02:17
*
*/
public class ReadDataFromHDFSMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, ImmutableBytesWritable, Put>.Context context) throws IOException, InterruptedException {
String line = value.toString();
// 倒数数据的同时清洗数据
String[] values = line.split("\t");
String row = values[0];
String name = values[1];
String infos = values[2];
//初始化rowKey
ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable(row.getBytes());
//初始化put
Put put = new Put(Bytes.toBytes(row));
//参数分别是 列族、列、值
put.add(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(name));
put.add(Bytes.toBytes("info"), Bytes.toBytes("color"), Bytes.toBytes(infos));
context.write(immutableBytesWritable, put);
}
}
1.2 构建Reducer类
import java.io.IOException;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @Title: WriteHBaseReducer.java
* @Package cn.zhuzi.hbase.mr_hdfs
* @Description: TODO(用一句话描述该文件做什么)
* @author 作者
* @version 创建时间:2018年11月5日 下午7:11:47
*
*/
public class WriteHBaseReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
@Override
protected void reduce(ImmutableBytesWritable imm, Iterable<Put> puts, Reducer<ImmutableBytesWritable, Put, NullWritable, Mutation>.Context context) throws IOException, InterruptedException {
// 读出来的每一行写入到 hbase表
for (Put put : puts) {
context.write(NullWritable.get(), put);
}
}
}
1.3 组装JOB并运行
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @Title: HDFSDriver.java
* @Package cn.zhuzi.hbase.mr_hdfs
* @Description: TODO(用一句话描述该文件做什么)
* @author 作者
* @version 创建时间:2018年11月5日 下午7:17:42
*
*/
public class HDFSDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
// 组装 JOB
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(HDFSDriver.class);
// 输入路径
Path inPath = new Path("hdfs://hadoop:9000//input/fruit.tsv");
// 添加输入路径
FileInputFormat.addInputPath(job, inPath);
// 设置mapper
job.setMapperClass(ReadDataFromHDFSMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
// 设置 Reduce
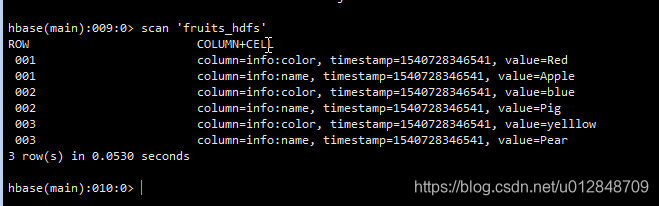
TableMapReduceUtil.initTableReducerJob("fruits_hdfs", WriteHBaseReducer.class, job);
// 设置Reduce数量,最小是1个
job.setNumReduceTasks(1);
boolean completion = job.waitForCompletion(true);
if (!completion) {
throw new IOException(" JOB 运行错误");
}
return completion ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "hadoop");// 单机
// zookeeper地址
conf.set("hbase.zookeeper.property.clientPort", "2181");// zookeeper端口
int run = ToolRunner.run(conf, new HDFSDriver(), args);
System.exit(run);
}
}
pom.xml部分内容
<properties>
<hadoop.verison>2.7.4</hadoop.verison>
<hive.verison>2.3.3</hive.verison>
<hbase.version>0.98.6.1-hadoop2</hbase.version>
<fastjson.version>1.2.46</fastjson.version>
</properties>
<dependencies>
<!-- 工具类 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.3.2</version>
</dependency>
<!-- 工具类/end -->
<!-- hdfs core common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.verison}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.verison}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.verison}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.verison}</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.6</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<!-- zookeeper客户端 -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.2</version>
</dependency>
<!-- HBASE需要 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- HBASE需要 /end -->
</dependencies>

















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









