









最近在研究多目标跟踪算法,虽然理论知识和相关概念还没能全部熟悉,但是还是来记录一下最近配置运行的MDP Tracking算法。开始是在MOT Challenge比赛(2D比赛,其数据地址:https://motchallenge.net/data/2D_MOT_2015/)上发现的这个算法,后来在GitHub上看到了开源的代码,说明也比较仔细。在windows上运行测试。
MDP Tracking算法的主页:http://cvgl.stanford.edu/projects/MDP_tracking/
代码地址:https://github.com/yuxng/MDP_Tracking
1、按照说明下载代码,并下载 2D MOT数据并解压;global.m文件中配置数据的路径,运行;
2、compile.m文件中配置opencv的路径和库目录;
如compile.m文件中:
include = ' -Id:\opencv2.4.10\opencv\build\include\ -Id:\opencv2.4.10\opencv\build\include\opencv\ -Id:\opencv2.4.10\opencv\build\include\opencv2';
lib = ' D:\opencv2.4.10\opencv\build\x64\vc12\lib\*d.lib'
运行编译配置opencv环境,这里可能会因为这句话报错:eval(['mex lk.cpp -O' include lib]); 提示mex文件错误,是由于lk.cpp文件中宏定义方面问题。
3、修改lk.cpp文件;
将lk.cpp中开头部分以下地方注释:
// #ifdef _CHAR16T
// #define CHAR16_T
// #endif
修改后compile.m编译通过。
4、运行代码。
运行MOT_cross_validation.m与MOT_test.m分别进行验证和测试。这里会出现svmtrain函数的问题,报错如下:

原因是代码中的svmtrain函数主要使用的是libsvm文件夹下的svmtrain.mexa64文件,但是MATLAB自带了svmtrain函数,在MATLAB中自带函数的优先级高于mex文件,因此没有使用此函数提高的svmtrain函数。

如上,svmtrain函数优先使用了MATLAB自带的函数。一般情况下不推荐自己的函数命名与MATLAB自带函数同名,因此,应该修改重新编译。
5、重新编译svmtrain.c。
1)在./MDP_Tracking-master/3rd_party/libsvm-3.20/matlab/文件夹中找到svmtrain.c文件,打开,将其中所有svmtrain修改成svmtrain1,并修改函数名为svmtrain1.c。
2)打开同一文件夹下的make.m文件,将其中所有svmtrain替换成svmtrain1,编译,获得新的mex文件(我在windows中运行,因此获得svmtrain1.mexw64文件)
3)替换MDP_Tracking代码中所有的svmtrain成svmtrain1,完成。
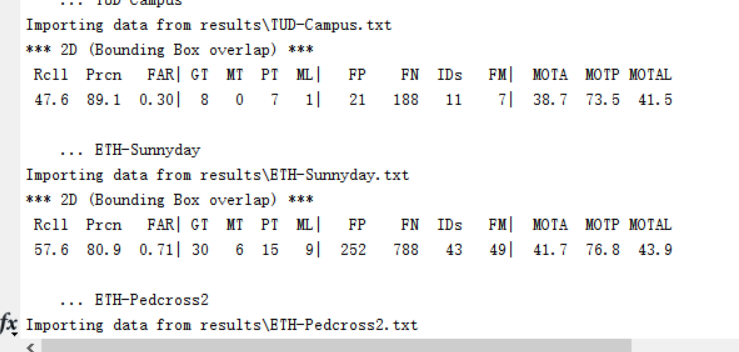
在此运行,通过,成功看到结果:














 297
297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









