







随着业务容器化的推进,经常有客户抱怨应用 QPS 无法和在物理机或者云主机上媲美,并且时常会出现 DNS 查询超时、短连接 TIME_OUT、网络丢包等问题,而在容器中进行调优与诊断的效果因为安装工具的复杂度大打折扣。本文基于网易轻舟中间件业务容器化实践,总结容器场景下的性能调优心得,供读者参考。
1性能调优的“望闻问切”
在讨论容器化场景的性能调优之前,先谈一下性能调优中的“望闻问切”。对于性能问题,大部分人首先想到的是 CPU 利用率高,但这只是个现象,并不是症状。打个比方:感冒看医生时,病人跟大夫描述的是现象,包括头部发热、流鼻涕等;而大夫通过探查、化验,得到的医学症状是病人的白细胞较多、咽喉红肿等,并确诊为细菌性感冒,给开了 999 感冒灵。性能调优流程与此相似,也需要找到现象、症状和解法。回到 CPU 利用率高的例子:已知现象是 CPU 利用率高,我们通过 strace 检查,发现 futex_wait 系统调用占用了 80% 的 CPU 时间——这才是症状;根据这个症状,我们业务逻辑代码降低了线程切换,CPU 利用率随之降低。
大部分的性能调优都可以通过发现现象、探测症状、解决问题这三个步骤来完成,而这在容器的性能调优中就更为重要的,因为在主机的性能调优过程中,我们有很多的经验可以快速找到症状,但是在容器的场景中,很多客户只能描述问题的现象,因为他们并不了解使用的容器引擎的工作原理以及容器化架构的实现方式。
2容器化性能调优的难点
容器化场景中的性能调优主要面临 7 个方面的挑战。
中间件种类多,调优方法又各不相同,如何设计一种好的框架来适配
我们借鉴 redhat tuned 思想,提出一种与业务相关的内核参数配置新框架,它可以把我们对 Linux 系统现有的一些调优手段(包括电源管理工具,CPU、内存、磁盘、网络等内核参数)整合到一个具体的策略 (profile) 中,业务场景不同,profile 不同,以此来快速实现云计算对不同业务进行系统的性能调节的需求。
VM 级别的调优方式在容器中实现难度较大
在 VM 级别我们看到的即是所有,网络栈是完整暴露的,CPU、内存、磁盘等也是完全没有限制的。性能调优老司机的工具箱安个遍,诊断流程走一趟基本问题就查个八九不离十了,但是在容器中,很多时候,都是默认不自带诊断、调优工具的,很多时候连 ping 或者 telnet 等基础命令都没有,这导致大部分情况下我们需要以黑盒的方式看待一个容器,所有的症状只能从物理机或者云主机的链路来看。但是我们知道容器通过 namespace 的隔离,具备完整网络栈,CPU、内存等通过隔离,只能使用 limit 的资源,如果将容器当做黑盒会导致很多时候问题症状难以快速发现,排查问题变难了。
容器化后应用的链路变长导致排查问题成本变大
容器的场景带来很多酷炫的功能和技术,比如故障自动恢复、弹性伸缩、跨主机调度等,但是这一切的代价是需要依赖容器化的架构,比如 Kubernetes 网络中需要 FullNat 的方式完成两层网络的转发等,这会给排查问题带来更复杂的障碍,当你不清楚编排引擎的架构实现原理的时候,很难将问题指向这些平时不会遇到的场景。例如上面这个例子中,FullNat 的好处是降低了网络整体方案的复杂性,但是也引入了一些 NAT 场景下的常见问题,比如短连接场景中的 SNAT 五元组重合导致包重传的问题等等,排查问题的方位变大了。
不完整隔离带来的调优复杂性
容器本质是一种操作系统级虚拟化技术,不可避免涉及隔离性,虽然平时并不需要考虑隔离的安全性问题,但是当遇到性能调优的时候,内核的共享使我们不得不面对一个更复杂的场景。举个例子,由于内核的共享,系统的 proc 是以只读的方式进行挂载的,这就意味着系统内核参数的调整会带来的宿主机级别的变更。在性能调优领域经常有人提到 C10K 或者 C100K 等类似的问题,这些问题难免涉及到内核参数的调整,但是越特定的场景调优的参数越不同,有时会有“彼之蜜糖,我之毒药”的效果。因此同一个节点上的不同容器会出现非常离奇的现象。
不同语言对 cgroup 的支持
这个问题在大多数场景下无需考虑,列在第四位是期望能够引起大家重视。网易轻舟在一次排查“ES 容器(使用 java 11)将 CPU requests 都配置成 8 时,其性能低于将 request CPU 都配置成 1”的问题时,发现是 Java 的标准库中对 cgroup 的支持不完全导致的,好在这点在大多数场景中没有任何影响。
网络方案不同带来的特定场景的先天缺欠
提到容器架构避不开网络、存储和调度,网络是评判容器架构好坏的一个核心标准,不同的网络方案也会有不同的实现方式与问题。比如网易轻舟 Kubernetes 中使用了 Flannel 的 CNI 插件实现的网络方案,标准 Flannel 支持的 Vxlan 的网络方案,Docker 的 Overlay 的 macVlan,ipvlan 的方案,或者 OpenShift SDN 网路方案,还有网易轻舟自研的云内普通 VPC 和 SRIOV+VPC 方案等等。这些不同的网络方案无一例外都是跨宿主机的二层网络很多都会通过一些 vxlan 封包解包的方式来进行数据传输,这种方式难免会增加额外的 CPU 损耗,这是一种先天的缺欠,并不是调优能够解决的问题。有的时候排查出问题也只能绕过而不是调优。
镜像化的系统环境、语言版本的差异
应用容器化是一个需要特别注意的问题,很多公司并没有严格的配管流程,比如系统依赖的内核版本、语言的小版本等等,很多时候都是选择一个大概的版本,这会带来很多语言层级的 BUG,比如 Java 应用程序运行在容器中可能会遇到更长的应用程序暂停问题、Java 7 无法感知 CPU 个数导致 GC 线程过多问题和 PHP7.0 中 php-fpm 的诡异行为。环境的问题本就需要严格管控,但是当遇到了容器,很多时候我们会分不清哪些不经意的行为会带来严重的问题,警惕性因为容器镜像能够正常启动而降低了。
3性能优化步骤和调优管理变更流程
性能优化通常可以通过如表五个步骤完成:
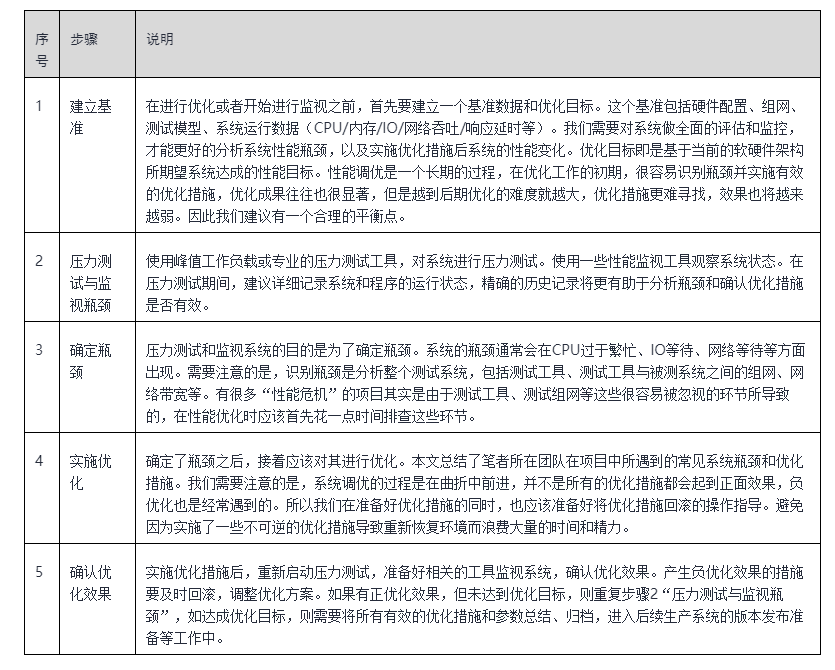
调优管理变更和性能优化并不直接相关,但可能是性能调优成功最重要的因素。以下总结来源于网易轻舟团队的实践和经验:
-
在调优之前,实施合理的调优管理流程变更
-
永远不要在生产系统上调优
-
压测的环境要相对独立,不能受其他压力的影响,这里说的不仅是压测的服务器端,而且包括压测客户端
-
在调优过程中,每次只修改一个变量
-
反复测试提升性能的参数,有时候,统计来的结果更加可靠
-
把成功的参数调整整理成文档,和社区分享,即使你觉得它们微不足道
-
生产环境中获得的任何结果对 Linux 性能都有很大用处
4调优手段
1. 通用调优
对于容器业务来说,尽量让 CPU 访问本地内存,不要访问远端内存。

CPU 访问不同类型节点内存的速度是不相同的,访问本地节点的速度最快,访问远端节点的速度最慢,即访问速度与节点的距离有关,距离越远访问速度越慢,此距离称作 Node Distance。正是因为有这个特点,容器应用程序要尽量的减少不同 Node 模块之间的交互,也就是说,我们根据容器内存 Node 亲和性,选择容器使用的 CPU 固定在一个 Node 模块里,因此其性能将会有很大的提升。有一种特殊场景除外,如果一个容器申请的 request 大于单个 Node 上预留的 CPU 后,这种亲和性的绑定就会失效,此时回归到原始的跨 Node 范围绑定,对于之前已经做了亲和性的容器(申请的 request 小于单个 Node 上预留的 CPU)我们的策略是继续维持不变。
2. 针对不同的场景的参数调优
针对不同的场景,可以考虑以下参数着手进行调优。
与CPU相关的配置

与内存相关的配置

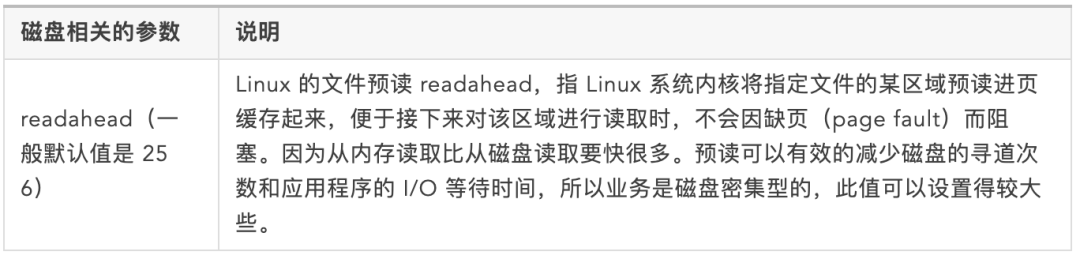
磁盘相关的参数
与sysctl相关的配置
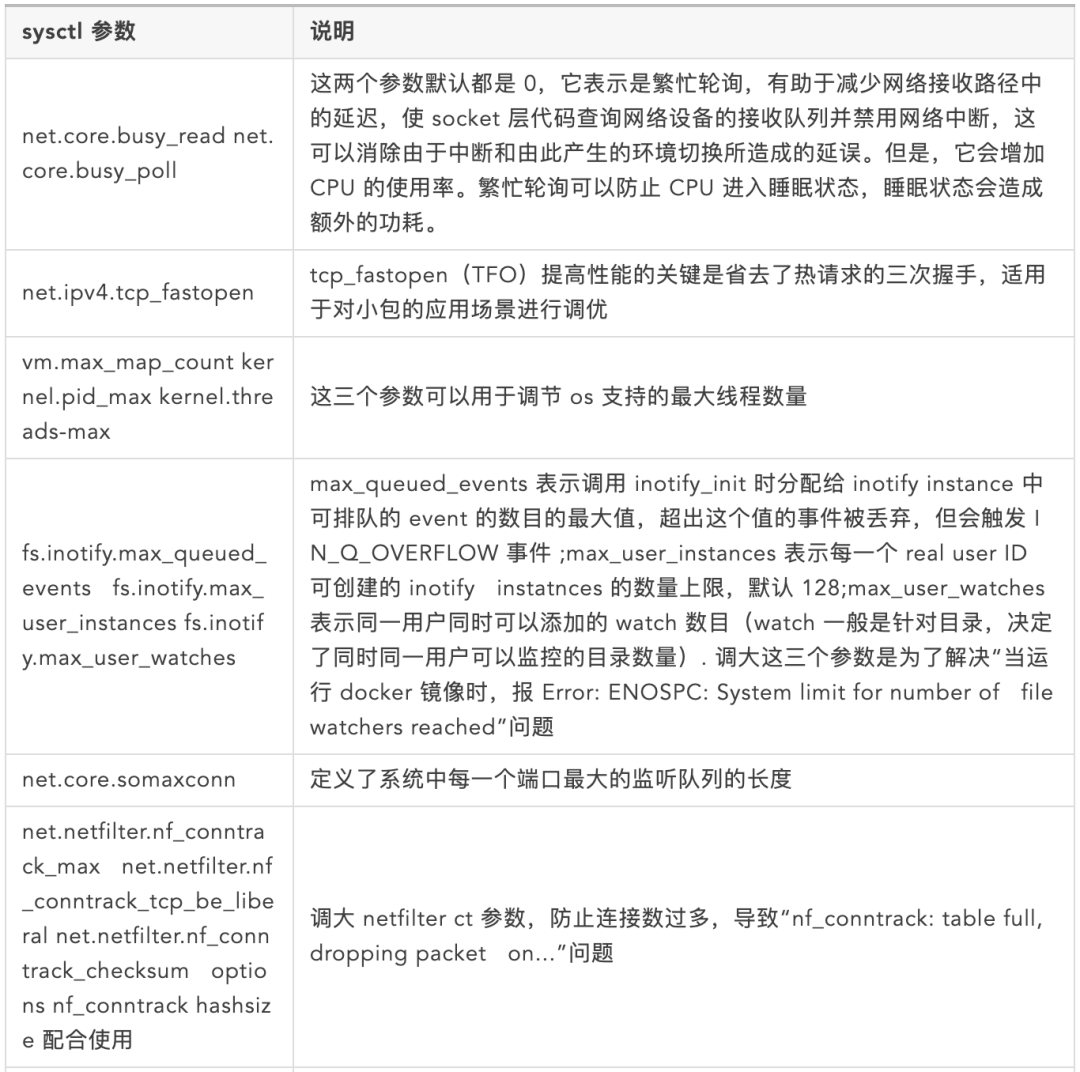

注:了解以上网络参数的具体含义,需学习 Linux 内核收发包原理,强烈推荐《Monitoring and Tuning the Linux Networking Stack》系列文章。详见文末参考文献 4-7。与 sysctl 相关的配置
3. 网络调优
软中断隔离:将容器网卡的软中断绑定到某几个专用 CPU 上,而容器业务进程绑定到其他 CPU 上,这样可以减少业务和网卡软中断之间的影响,避免频繁的上下文切换,特别适用于对网络性能要求极高的服务例如 Redis。对于云内普通 VPC 和云内 SR-IOV VPC 都适用:
-
云内普通 VPC:需要把容器使用的虚拟网卡 veth 的软中断绑定到预留的某几个专用 CPU 上
-
云内 SR-IOV VPC:需要把容器使用的 VF 网卡的软中断绑定到预留的某几个专用 CPU 上
-
SR-IOV 直通网卡:优化后端 DPDK PMD 线程配比,一般由 1 个调大至 2 个或者 4 个。
5调优效果
Redis
调优后 SR-IOV 下 QPS 接近 BGP 物理网络,99.99% 时延从 BGP 物理网络的 990ms 下降到 140ms。

Flink
调优后简单 ETL 任务 QPS 比 YARN 上高 20%,复杂 ETL 任务 QPS 比在 YARN 上高 30%。
RDS
对于 RDS MGR 集群,K8S 容器部署相比 RDS2.0 云主机 VM 部署,同等规格下性能提升可以达到 30%~170%;
经过优化后,与物理机部署相比,常规模式下,只写场景、只读场景和读写混合场景的性能差距保持在 5~10% 之间。
RocketMQ
异步复制集群:普通容器单分片相比物理机性能有 40% 差距,增加生产消费者数量,集群整体性能有所提升,但依然与标准物理机有 25% 左右差距;增加生产消费者数量,容器调优后的性能基本持平标准物理机,差距 5% 以内。
同步复制集群:普通容器性能略差于标准物理机,差距在 10% 左右,容器调优后的性能基本持平标准物理机,差距缩小到 5%。















 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











