









什么是盒子模型
http://www.imooc.com/video/3225
盒模型–边框(一)
盒子模型的边框就是围绕着内容及补白的线,这条线你可以设置它的粗细、样式和颜色(边框三个属性)。
如下面代码为 div 来设置边框粗细为 2px、样式为实心的、颜色为红色的边框:
div{
border:2px solid red;
}
上面是 border 代码的缩写形式,可以分开写:
div{
border-width:2px;
border-style:solid;
border-color:red;
}
注意:
1、border-style(边框样式)常见样式有:
dashed(虚线)| dotted(点线)| solid(实线)。
2、border-color(边框颜色)中的颜色可设置为十六进制颜色,如:
border-color:#888;//前面的井号不要忘掉。
3、border-width(边框宽度)中的宽度也可以设置为:
thin | medium | thick(但不是很常用),最常还是用象素(px)。
盒模型–边框(二)
现在有一个问题,如果有想为 p 标签单独设置下边框,而其它三边都不设置边框样式怎么办呢?css 样式中允许只为一个方向的边框设置样式:
div{border-bottom:1px solid red;}
同样可以使用下面代码实现其它三边(上、右、左)边框的设置:
border-top:1px solid red;
border-right:1px solid red;
border-left:1px solid red;
盒模型–宽度和高度
http://www.imooc.com/code/2054
盒模型–填充
元素内容与边框之间是可以设置距离的,称之为“填充”。填充也可分为上、右、下、左(顺时针)。如下代码:
div{padding:20px 10px 15px 30px;}
顺序一定不要搞混。可以分开写上面代码:
div{
padding-top:20px;
padding-right:10px;
padding-bottom:15px;
padding-left:30px;
}
如果上、右、下、左的填充都为10px;可以这么写
div{padding:10px;}
如果上下填充一样为10px,左右一样为20px,可以这么写:
div{padding:10px 20px;}
盒模型–边界
元素与其它元素之间的距离可以使用边界(margin)来设置。边界也是可分为上、右、下、左。如下代码:
div{margin:20px 10px 15px 30px;}
也可以分开写:
div{
margin-top:20px;
margin-right:10px;
margin-bottom:15px;
margin-left:30px;
}
如果上右下左的边界都为10px;可以这么写:
div{ margin:10px;}
如果上下边界一样为10px,左右一样为20px,可以这么写:
div{ margin:10px 20px;}
总结一下:padding和margin的区别,padding在边框里,margin在边框外。
盒模型
盒模型概念、width、height、padding、margin(水平居中)、border、border-radius、overflow、box-sizing、box-shadow、outline
盒模型图解
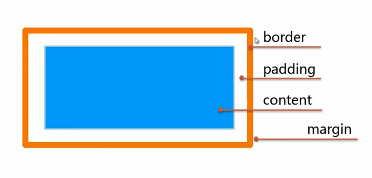
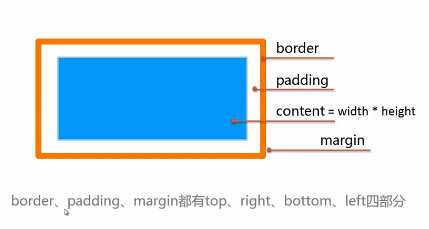
内容区通过width*height设置大小
width
width:<lenght> | <percentage> | auto | inherit
width的默认值为auto,block元素,inline元素 inline-block元素在默认情况下宽度规则不同。
引申:max-width min-widthheight
默认情况下元素高度为内容宽度
引申:max-height min-heightpadding填充
padding:[<lenght>|<percentage>]{1,4}margin
margin:[<length> | <percentage> | auto{1,4} | inherit]margin合并

如上图所示有两种margin合并的情况
1.毗邻元素会产生合并
2.父元素设置margin,并且第一个子元素或者最后一个子元素也设置了margin.如图中的父元素设置了margin-bottom:40px,子元素设置了margin-bottom:20px;将会产生margin合并为40px;
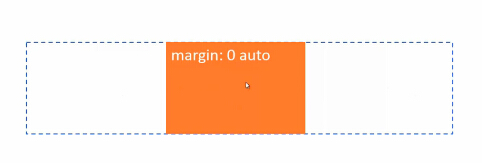
margin妙用-水平居中
border
border:[<border-width> || <border-style> || <border-color>] | inherit
border-style:[solid | dashed | dotted|...]{1,4}| inherit
border-color:[<color> | transparent]{1,4} | inherit
.....圆角
border-radius

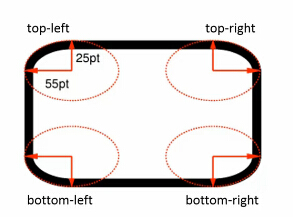
border-radius:[<length> | <percentage>{1,4}[/[<length> | <percentage>]{1,4}]
一个角需要水平半径和垂直半径设置 
border-radius:50%时为圆

盒子内容超出时的显示

overflow:visible | hidden | scroll | atuo超出部分仍然显示在盒子之外
overflow:visible;

超出部分被隐藏
overflow:hidden;

滚动条增加空间
overflow:scroll无论内容是否超出,都会有滚动条

内容超出,自动设置滚动条
overflow:auto当内容超出盒子时,自动设置滚动条增加空间

设定width, height指定的区域
box-sizing
box-sizing:content-box | border-box |inherit默认情况下box-sizing属性值为content-box,那么平常所使用的width 和height 表示的是content-box(内容区)的宽和高
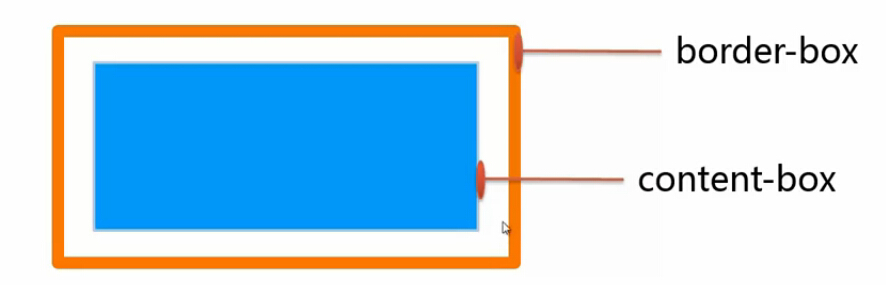
box-sizing:border-box之后,width 和height 将不在表示content-box的宽高,而是border-box(盒子)的宽高。
下图中唯一区别在于设置的box-sizing的属性值不同。

默认情况下设置的宽高是内容区(content-box)
添加效果:阴影
box-shadow
注意:阴影不占空间
box-shadow:none | <shadow>[,<shadow>]*
内外阴影
多个阴影效果可以用逗号分隔。

阴影不占空间
outline描边
不占空间
border之外
CSS属性的浏览器兼容属性查询
关于CSS属性的浏览器兼容性,可以通过 http://caniuse.com/ 查询。
border-radius ie8及以下不支持
box-sizing ie7及以下不支持
box-shadow ie8及以下不支持
outline ie7及以下不支持















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









