









出处: http://hawstein.com/posts/lru-cache-impl.html
声明:本文采用以下协议进行授权: 自由转载-非商用-非衍生-保持署名|Creative Commons BY-NC-ND 3.0 ,转载请注明作者及出处。
什么是LRU Cache
LRU是Least Recently Used的缩写,意思是最近最少使用,它是一种Cache替换算法。 什么是Cache?狭义的Cache指的是位于CPU和主存间的快速RAM, 通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。 广义上的Cache指的是位于速度相差较大的两种硬件之间, 用于协调两者数据传输速度差异的结构。除了CPU与主存之间有Cache, 内存与硬盘之间也有Cache,乃至在硬盘与网络之间也有某种意义上的Cache── 称为Internet临时文件夹或网络内容缓存等。
Cache的容量有限,因此当Cache的容量用完后,而又有新的内容需要添加进来时, 就需要挑选并舍弃原有的部分内容,从而腾出空间来放新内容。LRU Cache 的替换原则就是将最近最少使用的内容替换掉。其实,LRU译成最久未使用会更形象, 因为该算法每次替换掉的就是一段时间内最久没有使用过的内容。
数据结构
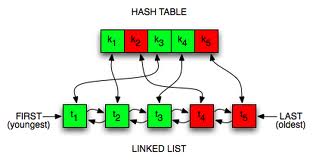
LRU的典型实现是hash map + doubly linked list, 双向链表用于存储数据结点,并且它是按照结点最近被使用的时间来存储的。 如果一个结点被访问了, 我们有理由相信它在接下来的一段时间被访问的概率要大于其它结点。于是, 我们把它放到双向链表的头部。当我们往双向链表里插入一个结点, 我们也有可能很快就会使用到它,同样把它插入到头部。 我们使用这种方式不断地调整着双向链表,链表尾部的结点自然也就是最近一段时间, 最久没有使用到的结点。那么,当我们的Cache满了, 需要替换掉的就是双向链表中最后的那个结点(不是尾结点,头尾结点不存储实际内容)。
如下是双向链表示意图,注意头尾结点不存储实际内容:
头 --> 结 --> 结 --> 结 --> 尾
结 点 点 点 结
点 <-- 1 <-- 2 <-- 3 <-- 点
假如上图Cache已满了,我们要替换的就是结点3。
哈希表的作用是什么呢?如果没有哈希表,我们要访问某个结点,就需要顺序地一个个找, 时间复杂度是O(n)。使用哈希表可以让我们在O(1)的时间找到想要访问的结点, 或者返回未找到。
Cache接口
Cache主要有两个接口:
T Get(K key);
void Put(K key, T data);
当我们通过键值来访问类型为T的数据时,调用Get函数。如果键值为key的数据已经在 Cache中,那就返回该数据,同时将存储该数据的结点移到双向链表头部。 如果我们查询的数据不在Cache中,我们就可以通过Put接口将数据插入双向链表中。 如果此时的Cache还没满,那么我们将新结点插入到链表头部, 同时用哈希表保存结点的键值及结点地址对。如果Cache已经满了, 我们就将链表中的最后一个结点(注意不是尾结点)的内容替换为新内容, 然后移动到头部,更新哈希表。
C++代码
注意,hash map并不是C++标准的一部分,我使用的是Linux下g++ 4.6.1, hash_map放在/usr/include/c++/4.6/ext下,需要使用__gnu_cxx名空间, Linux平台可以切换到c++的include目录:cd /usr/include/c++/版本 然后grep -iR “hash_map” ./ 查看在哪个文件中,一般头文件的最后几行会提示它所在的名空间。 其它平台请自行探索。XD
当然如果你已经很fashion地在使用C++ 11,就不会有这些小困扰了。
// A simple LRU cache written in C++
// Hash map + doubly linked list
#include <iostream>
#include <vector>
#include <ext/hash_map>
using namespace std;
using namespace __gnu_cxx;
template <class K, class T>
struct Node{
K key;
T data;
Node *prev, *next;
};
template <class K, class T>
class LRUCache{
public:
LRUCache(size_t size){
entries_ = new Node<K,T>[size];
for(int i=0; i<size; ++i)// 存储可用结点的地址
free_entries_.push_back(entries_+i);
head_ = new Node<K,T>;
tail_ = new Node<K,T>;
head_->prev = NULL;
head_->next = tail_;
tail_->prev = head_;
tail_->next = NULL;
}
~LRUCache(){
delete head_;
delete tail_;
delete[] entries_;
}
void Put(K key, T data){
Node<K,T> *node = hashmap_[key];
if(node){ // node exists
detach(node);
node->data = data;
attach(node);
}
else{
if(free_entries_.empty()){// 可用结点为空,即cache已满
node = tail_->prev;
detach(node);
hashmap_.erase(node->key);
}
else{
node = free_entries_.back();
free_entries_.pop_back();
}
node->key = key;
node->data = data;
hashmap_[key] = node;
attach(node);
}
}
T Get(K key){
Node<K,T> *node = hashmap_[key];
if(node){
detach(node);
attach(node);
return node->data;
}
else{// 如果cache中没有,返回T的默认值。与hashmap行为一致
return T();
}
}
private:
// 分离结点
void detach(Node<K,T>* node){
node->prev->next = node->next;
node->next->prev = node->prev;
}
// 将结点插入头部
void attach(Node<K,T>* node){
node->prev = head_;
node->next = head_->next;
head_->next = node;
node->next->prev = node;
}
private:
hash_map<K, Node<K,T>* > hashmap_;
vector<Node<K,T>* > free_entries_; // 存储可用结点的地址
Node<K,T> *head_, *tail_;
Node<K,T> *entries_; // 双向链表中的结点
};
int main(){
hash_map<int, int> map;
map[9]= 999;
cout<<map[9]<<endl;
cout<<map[10]<<endl;
LRUCache<int, string> lru_cache(100);
lru_cache.Put(1, "one");
cout<<lru_cache.Get(1)<<endl;
if(lru_cache.Get(2) == "")
lru_cache.Put(2, "two");
cout<<lru_cache.Get(2);
return 0;
}
参考链接
http://www.cs.uml.edu/~jlu1/doc/codes/lruCache.html















 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









