








RNN/Stacked RNN
rnn一般根据输入和输出的数目分为5种
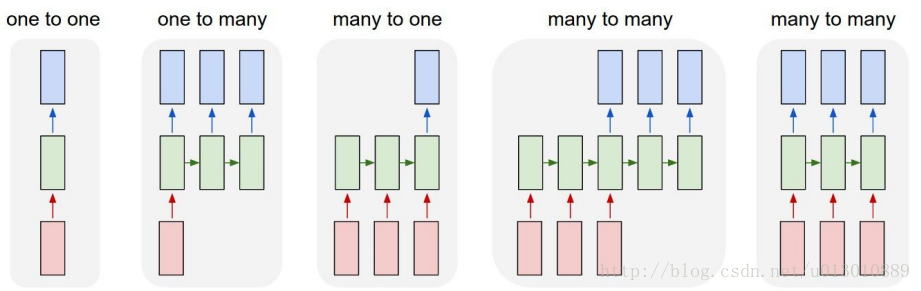
- 一对一 最简单的rnn
- 一对多 Image Captioning(image -> sequence of words)
- 多对一 Sentiment Classification(sequence of words -> sentiment)
- 多对多: 时序不齐 Machine Translation(seq of words -> seq of words)
- 多对多: 时序对齐 Video classification on frame level
每一个时序的计算中W是相同的即
W
h
h
,
W
x
h
W_{hh},W_{xh}
Whh,Wxh,pytorch中貌似没有
W
h
y
W_{hy}
Why,比如在RNNCell()中只返回一个output,在RNN()中返回最后一个时序的hidden和所有时序的output,且最后一个时序的output就等于最后一个时序的hidden,所以pytorch里面好像没有对h乘以变换
W
h
y
W_{hy}
Why
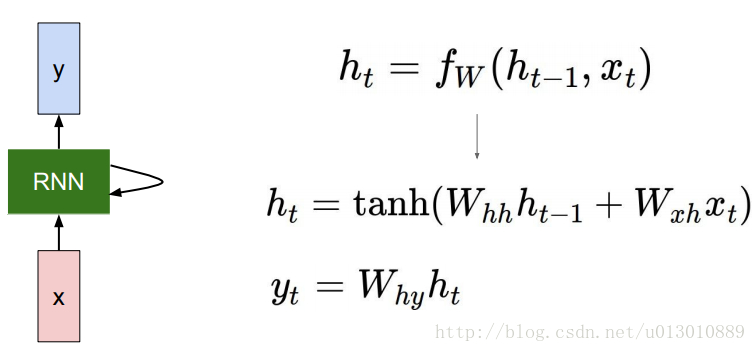
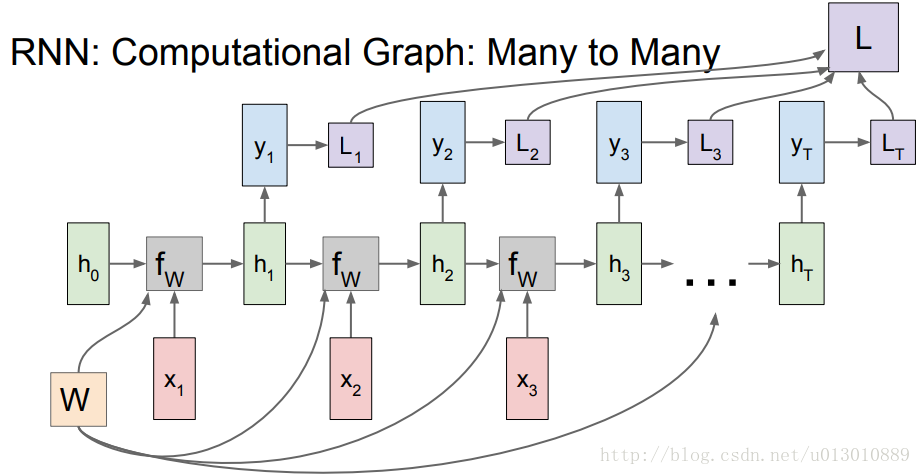
# pytorch代码示例
'''
对于最简单的 RNN,我们可以使用下面两种方式去调用,分别是 torch.nn.RNNCell() 和 torch.nn.RNN(),
这两种方式的区别在于 RNNCell() 只能接受序列中单步的输入,且必须传入隐藏状态,
而 RNN() 可以接受一个序列的输入,默认会传入全 0 的隐藏状态,也可以自己申明隐藏状态传入。
'''
# rnn_single.weight_ih [torch.FloatTensor of size 200x100]
# rnn_single.weight_hh [torch.FloatTensor of size 200x200]
rnn_single = nn.RNNCell(input_size=100, hidden_size=200)
# 构造一个序列,长为 6,batch 是 5, 特征是 100
x = Variable(torch.randn(6, 5, 100)) # 这是 rnn 的输入格式
# 定义初始的记忆状态
h_t = Variable(torch.zeros(5, 200))
# 传入 rnn
out = []
for i in range(6): # 通过循环 6 次作用在整个序列上
h_t = rnn_single(x[i], h_t)
out.append(h_t)
# out.shape: torch.Size([6, 5, 200])
# ------------------------------
rnn_seq = nn.RNN(100, 200)
out, h_t = rnn_seq(x) # 使用默认的全 0 隐藏状态
# 自己定义初始的隐藏状态 [torch.FloatTensor of size 1x5x200]
# number_layer*bidirectional, batch, hidden_size
# 如过h_t的shape中没有number_layer*bidirectional(True:2,False:1)这个维度
# 即h_0 = Variable(torch.randn(5, 200))那么每层每个方向都用一样的隐状态
h_0 = Variable(torch.randn(1, 5, 200))
out, h_t = rnn_seq(x, h_0)
# out.shape: torch.Size([6, 5, 200])
还有一个Stacked RNN,上面的代码中有个参数num_layers=2,depth方向上,上一个RNN的输出即最后一个h/out,作为输入送到下一个RNN
# input_size hidden_size
rnn_seq = nn.RNN(50, 100, num_layers=2)
# weight_ih (hidden_size, layer_input_size)
print rnn_seq.weight_ih_l0.shape # (100L, 50L) 第一层的输入是50
print rnn_seq.weight_ih_l1.shape # (100L, 100L) 第二层的输入是100,即上一个RNN的输出h
rnn_input = Variable(torch.randn(10, 3, 50))
out, h = rnn_seq(rnn_input)
# h: number_layer*bidirectional, batch, hidden_size
# h: 2*1,3,100
print h.shape # (2L, 3L, 100L) 时序方向w共享,depth方向w不同
# out: seq_len, batch, num_directions * hidden_size
print out.shape # (10L, 3L, 100L)
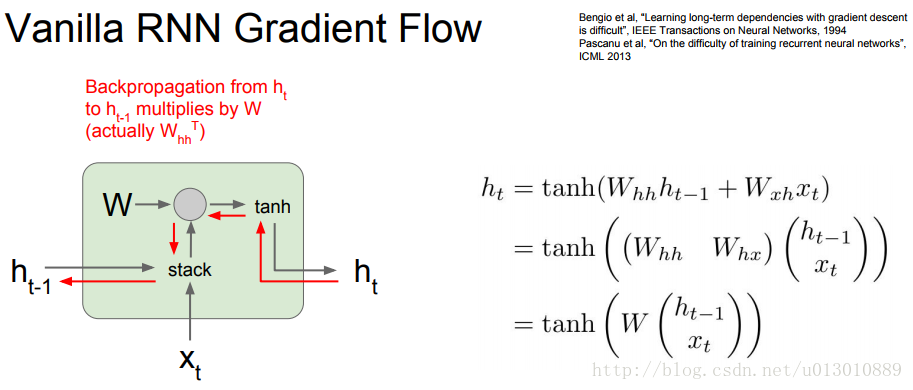
上述的RNN在应用时会出现下图所示的梯度爆炸或者梯度消失(根据求导可知)
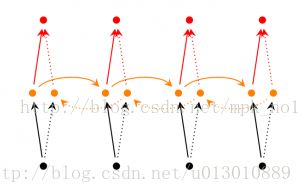
Bidirectional RNN(双向RNN)##
在经典的循环神经网络中,状态的传输是从前往后单向的。然而,在有些问题中,当前时刻的输出不仅和之前的状态有关系,也和之后的状态相关。这时就需要双向RNN(BiRNN)来解决这类问题。例如预测一个语句中缺失的单词不仅需要根据前文来判断,也需要根据后面的内容,这时双向RNN就可以发挥它的作用。
双向RNN是由两个RNN上下叠加在一起组成的。输出由这两个RNN的状态共同决定。
从上图可以看出,双向RNN的主题结构就是两个单向RNN的结合。在每一个时刻t,输入会同时提供给这两个方向相反的RNN,而输出则是由这两个单向RNN共同决定(可以拼接或者求和等)。
# input_size hidden_size
rnn_seq = nn.RNN(50, 100, num_layers=2, bidirectional=True)
# weight_ih (hidden_size, layer_input_size)
# layer_input_size = hidden_size * num_directions
print rnn_seq.weight_ih_l0.shape # (100L, 50L) 第一层的输入是50
print rnn_seq.weight_ih_l1.shape # (100L, 200) 第二层的输入是1200,即上一个RNN的输出h
rnn_input = Variable(torch.randn(10, 3, 50))
out, h = rnn_seq(rnn_input)
# h: number_layer*bidirectional, batch, hidden_size
# h: 2*2,3,100
print h.shape # (4L, 3L, 100L) 时序方向w共享,depth方向w不同
print out.shape # (10L, 3L, 100L)
LSTM/Stacked LSTM
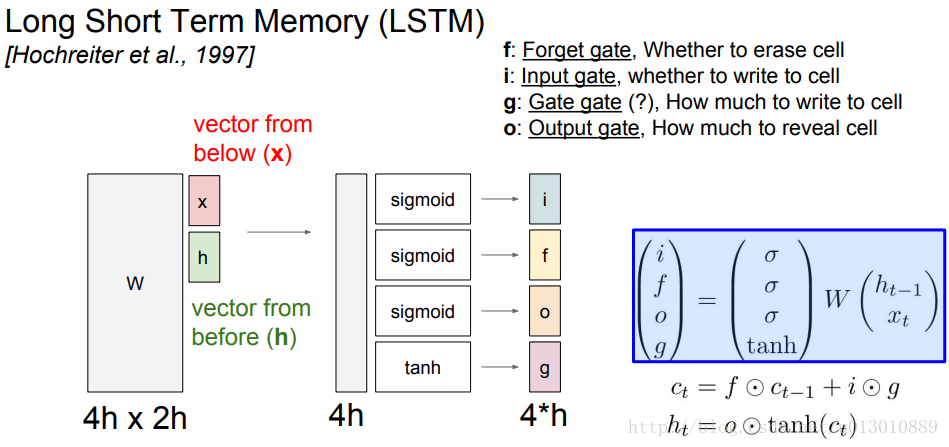
首先介绍一下lstm的内部结构
图中将4个门的权重cat起来成4h,输入x和hiddencat起来成2h
还有一个Stacked LSTM,其实也可以是Stacked RNN,只是RNN那里篇幅太长了,没有配图
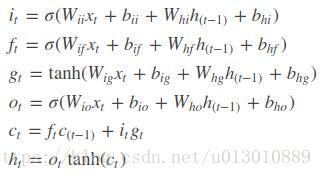
lstm_seq = nn.LSTM(50, 100, num_layers=2) # 输入维度 50,输出 100,两层
# weight_ih (gate_size, layer_input_size)
print lstm_seq.weight_ih_l0.shape # (400L, 50L) 注意是ih
print lstm_seq.weight_ih_l1.shape # (400L, 100L) 输入的维度从50变成100了,即上一层的输出c作为了输入
print lstm_seq.weight_hh_l0 # 第一层的 h_t权重 [400x100] 对应于4个gate的权重 注意是hh
lstm_input = Variable(torch.randn(10, 3, 50))
out, (h, c) = lstm_seq(lstm_input)
print h.shape # (2L, 3L, 100L) 时序方向w共享,depth方向w不同
print c.shape # (2L, 3L, 100L) 时序方向w共享,depth方向w不同
print out.shape # (10L, 3L, 100L)
接着介绍下LSTM是如何解决RNN出现的梯度问题,引用一张知乎上的图
Backpropagation from ct to ct-1 only elementwise multiplication by f, no matrix multiply by W —cs231n_2017_lecture10.pdf, page99

GRU
在 GRU 中,大幅简化了 LSTM 结构:
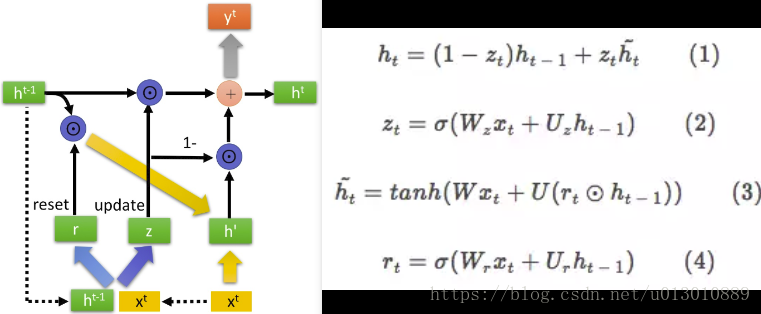
- 新增 reset gate,即图中的 r 开关
- 将输入门和遗忘门合并为“update gate”,即图中的 z 开关
- 将细胞状态 C 和隐藏状态 m 合并为 h
- 省掉了输出门
与LSTM相比,GRU内部少了一个”门控“,参数比LSTM少,但是却也能够达到与LSTM相当的功能。考虑到硬件的计算能力和时间成本,因而很多时候我们也就会选择更加”实用“的GRU啦。
gru_seq = nn.GRU(4, 5, num_layers=1, bidirectional=False) # 输入维度 4,输出 5
print gru_seq.weight_ih_l0.shape # (15L, 4L)
print gru_seq.weight_hh_l0.shape # (15L, 5L) 对应于2个gate和公式(3)中的权重
SRU
为什么我们在训练RNN时会比CNN那么慢呢,因为CNN的计算瓶颈在卷积,而卷积可以并行计算,比如某一层有200个卷积核,他们是互不影响可以并行计算的,每个卷积核的计算转换后是矩阵乘法(1, CKK) x (CKK, HW)。RNN的计算瓶颈在权重和[输入, h_t-1]的矩阵相乘(RNN中ht,LSTM GRU中各种门都是这样计算的),这相当于是全连接,以LSTM中4个门的计算为例,参考上文的LSTM4个门的计算公式,也是矩阵乘法WihXt: (4hidden_size, input_szie)x (input_szie, 1)和WhhHt-1: (4*hidden_size, hidden_size) x (hidden_size, 1) , 这些矩阵相乘计算量比单个卷积核转换后的矩阵乘法计算量要大,尤其是input_size和hidden_size很大时,且必须串行处理,所以导致很慢。
左边是传统的RNN/LSTM/GRU结构,每个时刻灰色的计算部分都要等到上一时刻计算完成,主要体现在计算各个门时需要上一时刻的隐层和权重进行矩阵相乘,这个是很耗时。而GRU在计算门时是可以并行的,即每个时刻计算量较大的矩阵运算可以并行了(训练完成后,甚至可以提前保存所有词向量和训练好的权重W的计算结果,inference时直接查表)。剩下的依赖就是ct,ht的计算了,不过这是时间上的依赖本身就是RNN的特点所在,不能解除,而且这些计算都是element-wise相乘相加,速度很快。
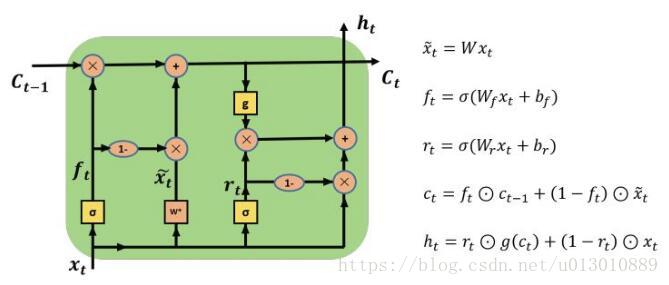

Multi-Dimensional LSTM
上面的RNN、LSTM每个Cell的输入x和隐层h都只有一个,都是一维的,Stacked RNN/LSTM也只是在depth上多加了几层。而Multi-Dimensional RNN/LSTM的cell的输入x是N个,隐层h, m也是N个。例如二维图片,在之前的是把每行当成一个输入,N行就是序列为N的输入,现在当前每个像素(x,y)的cell的输入是两维,即(x-1,y)和(x,y-1)位置cell的输出。公式如下N个输入x得到N个门g,然后当前位置的memory cell m由N个隐层m决定。
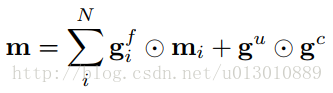
As the number of paths in a grid grows combinatorially with the size of each dimension and the total number of dimensions N, the values in m can grow at the same rate due to the unconstrained summation in Eq. 4(上述公式). This can cause instability for large grids, and adding cells along the depth dimension increases N and exacerbates the problem —Grid LSTM paper
注意,Multi-Dimensional LSTM的cell虽有多个输入和隐层,但是它只输出一个m(有些称c)和h,当前cell在各个维度上与其他cell相连时是通过上述公式,但是由于N个求和可能随着N的增大会不稳定
Grid LSTM
上面的RNN、LSTM、Stack RNN/LSTM、 Multi-Dimensional LSTM都是只是在时序一个方向加了RNNCell和LSTMCell,尽管 Multi-Dimensional LSTM增加了多维,但是当前cell在各个维度上与其他cell相连时不是通过lstm cell的公式相连,而是由上文的公式决定,存在不稳定性。
而Grid LSTM和Multi-Dimensional LSTM一样接受N个h和N个m(第一层还会有N个重复的x),但是每个cell都会输出N个h’和N个m’,在与其他维度的cell联系时不是Multi-Dimensional LSTM那样只有输出一个h’和m’然后通过那个公式,而是每个维度都对应它输出的N个h’和m’中的一个然后通过LSTM cell的公式相连。
具体相连如下所示,左下角第一个cell,h有两个
h
t
−
1
h_{t-1}
ht−1和
b
l
−
1
b_{l-1}
bl−1,c(即m)有两个
c
t
−
1
c_{t-1}
ct−1和
a
l
−
1
a_{l-1}
al−1,然后后输出2对h’和m’,即一对h’和m’:
a
l
,
b
l
a_l, b_l
al,bl与垂直维度的cell相连,另一对h’和m’:
c
t
,
h
t
c_t, h_t
ct,ht与水平维度的cell相连。(橙色的对应都是c,蓝色的对应都是h)
相连时的内部计算,就是计算2个LSTM cell
即以下公式,不过论文还有一段介绍PRIORITY DIMENSIONS,不具体展开了
3D的也一样,3对h’和m’
Graph LSTM##
上述的LSTM的拓扑结构大多是事先定义的,都是固定或者平分的,Graph LSTM中的拓扑结构是图,这里作者主要是把它应用到了semantic segmentation,因为之前的拓扑结构都是固定的,但是图片中每个物体都有天然的边界和纹理,这些先验不一定是固定的,如果按照之前的结构,需要每个像素都要按部就班费时费力(因为很多相邻像素都很像,都属于同一个语义标签),而我们可以通过现有方法得到一些不规则的语义像素块,然后在这些块上做lstm,减少了很多无用功。
引用:
- GRID LONG SHORT-TERM MEMORY
- Semantic Object Parsing with Graph LSTM
- GRID-LSTM.pptx_.pdf
- Highway Network & Grid LSTM
- Multi-Dimensional Recurrent Neural Networks
- 为什么相比于RNN,LSTM在梯度消失上表现更好?
- SherlockLiao/code-of-learn-deep-learning-with-pytorch
- 深度学习笔记——RNN(LSTM、GRU、双向RNN)学习总结
- 人人都能看懂的GRU
- 从 RNN, LSTM, GRU 到 SRU
- XXYY、Trio、Tao Lei的回答: 如何评价新提出的RNN变种SRU?














 2706
2706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









