










量化主要有两种方案
- 直接训练量化模型如Deepcompression,Binary-Net,Tenary-Net,Dorefa-Net
- 对训练好的float模型(以float32为例)直接进行量化(以int8为例),这边博客主要讲这个
参考NIVIDIA 量化官方文档
int8量化原理
将已有的float32型的数据改成A = scale_A * QA + bias_A,B类似,NVIDIA实验证明可以去掉bias,即A = scale_A * QA
也即是QA(量化后的A) = A / scale_A

有了对应公式A = scale_A * QA,则可以将float32的数据映射到int8,但是由于float32的数据动态范围比int8要大很多,如果数据分布不均匀,极限情况比如如果float32的原始数据都在127的周围,最后量化后都是127了,精度损失严重,而int8其他的数值完全没有用到,没有完全利用int8的数值范围,所以直接最大最小映射不是一个最优方案。
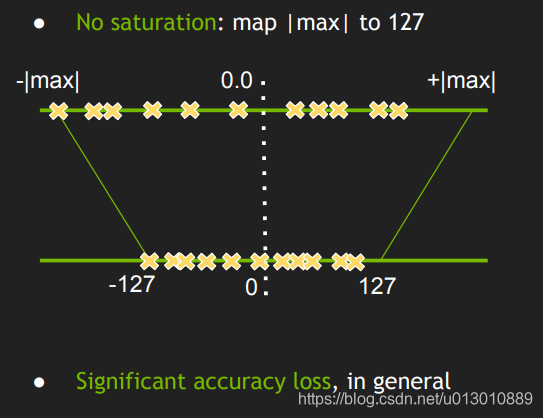
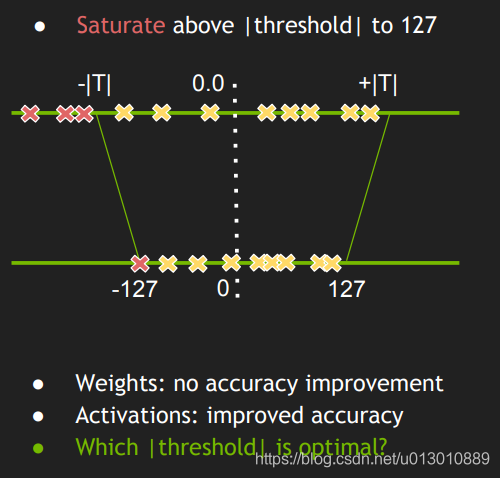
那能不能找到一个threshold,丢掉一部分float32数值,然后能够更加均匀地映射,从而充分地利用到int8的数值范围
在Softmax原理讲解中提到
交叉熵= 熵 + KL散度(相对熵)
1)信息熵:编码方案完美时,最短平均编码长度的是多少。
2)交叉熵:用次优编码方式时平均编码长度是多少,即需要多少个bits来表示
平均编码长度 = 最短平均编码长度 + 一个增量
3)相对熵:编码方案不一定完美时,平均编码长度相对于最小值的增加值。(即上面那个增量)
int8编码时所需编码长度 = float32编码时所需编码长度 + int8多需要的编码长度
因此相对熵就是int8float32(次优编码)比float32(最优编码)多出来的编码长度越小越好,所以需要找到一个合适的threshold,使得两者之间的相对熵最小即KL散度
这个KL距离代表了损失的信息

如何寻找一个合适的threshold呢,需要一个校准集合 Calibration Dataset,在校准数据集上运行FP32推理。收集激活的直方图,并生成一组具有不同阈值的8位表示法,并选择具有最少kl散度的表示;kl-散度是在参考分布(即FP32激活)和量化分布之间(即8位量化激活)之间。

TVM实现int8量化
# 从前端load模型,mxnet、onnx等
sym, _ = relay.frontend.from_mxnet(sym, {'data': data_shape})
# 随机生成test的模型参数,如果有已训练好的模型参数可以忽略
sym, params = tvm.relay.testing.create_workload(sym)
# 模型量化
with relay.quantize.qconfig(skip_k_conv=0, round_for_shift=True):
sym = relay.quantize.quantize(sym, params)
# 模型优化(经过试验,tvm系统默认有一些常用的resnet的卷积优化,注意这个优化是和卷积配置包括输入输出kernel的数量绑定的)
# 如果使用系统已有的卷积优化配置则速度可保证,如果使用一些新奇的卷积结构需要使用auto tuning优化,不然很慢
参考 https://docs.tvm.ai/tutorials/autotvm/tune_relay_cuda.html#auto-tuning-a-convolutional-network-for-nvidia-gpu
# load最优的优化算子,然后编译模型
with autotvm.apply_history_best(log_file):
print("Compile...")
with relay.build_config(opt_level=3):
graph, lib, params = relay.build_module.build(
net, target=target, params=params)
# 加载参数并运行
ctx = tvm.context(str(target), 0)
module = runtime.create(graph, lib, ctx)
data_tvm = tvm.nd.array((np.random.uniform(size=input_shape)).astype(dtype))
module.set_input('data', data_tvm)
module.set_input(**params)
# module.set_input(**{k:tvm.nd.array(v, ctx) for k, v in params.items()})
module.run()
# 测试forward时间
e = module.module.time_evaluator("run", ctx, number=2000, repeat=3)
t = module(data_tvm).results
t = np.array(t) * 1000
print('{} (batch={}): {} ms'.format(name, batch, t.mean()))
tvm的一些代码链接tvm-cuda-int8-benchmark














 1019
1019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









