









组织部的项目接手的时候因为需求文档不是特别的齐全,所以对与需求不是特别的了解。开始就是点点页面,输入一些数据,但是总感觉只是了解了一些不是特别的详细。所以就想着,把库里的东西全部清除了,然后自己加数据,看看数据的来龙去脉。
问题1: 怎样清空库里的全部数据?
组织部的项目 数据库中有很多表,总不能一条一条的删除吧!所以就上午查了查有没有简单的办法可以删除整个数据库的内容。还真找到了!
解决方法:
exec sp_msforeachtable "truncate table ?"
原文链接:<http://www.cnblogs.com/kingkoo/archive/2008/02/24/1079157.html>
问题2:数据中的全部数据清楚之后,有的功能不能用了,因为有的方法调的是视图的数据。而视图设计的也比较厉害,是视图连级,视图生成视图生成视图。我去我也是醉了 ! 于是我是我就想着利用备份的数据库,把视图用到的基表中的数据直接还原回去!但是每章基表中的数据有比较多,如果一条一条的添加的话比较麻烦,所以在网上找了一个简单的方法从一个数据库复制数据到另一个数据库。
解决方法:
insert intoA表数据库名.[dbo].A(a,b,c)
(select a,b,c fromB表数据库名.[dbo].B)
原文链接:http://zhidao.baidu.com/question/111313189.html
问题3: 基表中的数据全部还原了,为什么视图中没有数据那?
这个问题还是感谢小崔的帮忙啊! 视图中的数据生成的时候主键与外键要对应 ! 因为基表 中有的ID设置对的是主键,而且是自增长的。假如说数据库中之前有 5条记录,那么id就排到5了 ! 用 delete语句清空表里的数据之后。然后再往表里加数据的时,细心的你会发现,id是默认从6开始的 。所以我的表中的id和 备份数据库 表中的id是不对应的,所以主键和外键也不能保证对应,所以视图中就没有数据。
解决方法:
清空表中数据的时候用:truncate table 表名 语句。
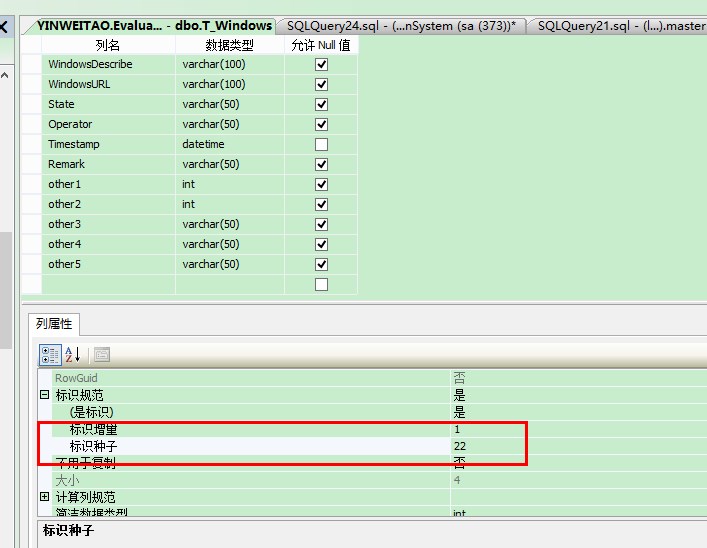
ps:这时再往表中添加数据的时候ID就会从1开始。 但是如果需要ID 从大于1 的数开始(例如22),可以 从表—设计— 选中ID —表示规范—标示种子设置为22 即可。
总结:开始做项目之后,才发现自己是一个名副其实的菜鸟啊! 正是因为这样自己才能有动力,遇到困难耐心解决,去剖析其中的原理,等你解决的困难足够多的时候,就成为高手了!















 7459
7459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









