






全文检索:先建立索引,在对索引进行搜索的过程
使用Lucene实现全文检索,其流程包含两个过程,索引创建过程和索引查询过程
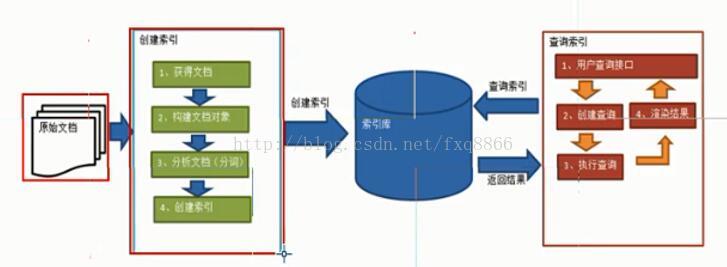
创建索引:
1.获取文档
2.创建文档对象
3.分析文档
4.创建索引
把创建好的索引和原始文档放入到索引库中。
查询索引
1.用户查询接口
2.创建查询
3.执行查询,查询索引库
4.根据索引库返回结果进行渲染
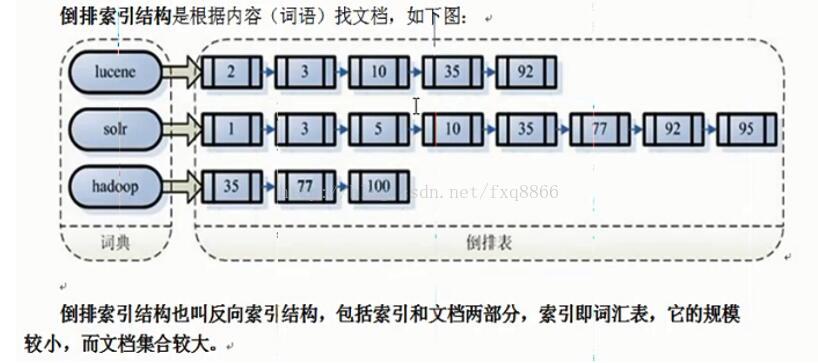
索引的目的是为了搜索,创建索引是对语汇单元索引,通过词语找文档,称为倒排索引结构。
创建索引:
public IndexWriter getIndexWriter() throws Exception
{
//1.保存到内存中
//Directory directory = new RAMDirectory();
//1.指定索引库的存放位置Directory;
Directory directory = FSDirectory.open(new File("E:\\tempLucencsolr\\index"));
//2.指定一个分析器,对文档内容进行分析
Analyzer analyzer = new IKAnalyzer();//StandardAnalyzer();//官方推荐
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST,analyzer);
return new IndexWriter(directory,config);
}
@Test
public void createIndex() throws Exception
{
//创建一个indexWriter对象
IndexWriter indexWriter = getIndexWriter();
//创建filed对象,将filed添加到document对象中
File f = new File("E:\\tempLucencsolr\\searchSource");
File[] listFiles = f.listFiles();
for (File file:listFiles) {
//创建document对象
Document document = new Document();
//文件名称
String file_name = file.getName();
Field fileNameField = new TextField("fileName",file_name, Field.Store.YES);
//文件大小
Long file_size = FileUtils.sizeOf(file);
Field fileSizeField = new LongField("fileSize",file_size, Field.Store.YES);
//文件路径
String file_path = file.getPath();
Field filePathField = new StoredField("filePath",file_path);
//文件内容
String file_content = FileUtils.readFileToString(file);
Field fileContentField = new TextField("fileContent",file_content, Field.Store.NO);
document.add(fileNameField);
document.add(fileSizeField);
document.add(filePathField);
document.add(fileContentField);
//使用indexWriter对象将document对象写入索引库,此过程进行索引创建,并将
//索引和document对象写入索引库
indexWriter.addDocument(document);
}
System.out.println("lucene导入索引创建成功");
//关系IndexWriter对象
indexWriter.close();
}检索索引:
@Test
public void testSearcher() throws Exception
{
//第一步:创建一个Directory对象,索引库存放的位置
Directory directory = FSDirectory.open(new File("E:\\tempLucencsolr\\index"));
//第二步: 创建一个indexReader对象,需要指定Directory对象
IndexReader indexreader = DirectoryReader.open(directory); //流
//第三步:创建一个indexsearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexreader);//搜索对象
//第四步:创建一个TermQuery对象,指定查询的域和查询的关键词
Query query =new TermQuery(new Term("fileContent","jvm"));
//第五步:执行查询
TopDocs topDocs= indexSearcher.search(query,2);
//第六步:返回查询结果,遍历查询结果并输出
ScoreDoc[] scoreDocs= topDocs.scoreDocs; //评分之后的文档。
for (ScoreDoc scoreDoc:scoreDocs)
{
int doc= scoreDoc.doc;
System.out.println("文档编号:"+doc);
Document document = indexSearcher.doc(doc); //根据文档编号查询文档
//文件名称
String fileName = document.get("fileName");
System.out.println(fileName);
//文件内容
String fileContent = document.get("fileContent");
System.out.println(fileContent);
//文件路径
String filePath = document.get("filePath");
System.out.println(filePath);
}
System.out.println("搜索执行结束");
//第七步:关闭IndexReader对象
indexreader.close();
}














 645
645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









