






bert是什么
BERT(Bidirectional Encoder Representations from Transformers)是一种自然语言处理(NLP)中的预训练模型,它是基于Transformer架构的一种深度学习模型。BERT的主要目标是在大规模文本语料库上进行预训练,然后可以通过微调来用于各种NLP任务,例如文本分类、命名实体识别、问答等。
BERT的核心思想是在大规模文本语料库上进行预训练。在大量的文本数据上进行了自我学习,以学习单词、短语和句子之间的语义关系。BERT使用了两个预训练任务来训练模型:
- 掩盖语言建模(Masked Language Modeling,MLM):在输入文本中,随机选择一些单词并将它们替换为特殊的"[MASK]"标记,然后模型的任务是预测这些标记的原始单词。
- 下一句预测(Next Sentence Prediction,NSP):模型接受一对句子作为输入,并预测这两个句子是否是连续的。
BERT在通过大量数据进行预训练后,会生成一个预训练模型。预训练模型包含了在大规模文本语料库上学习到的单词、短语和句子的语义表示。这个模型可以用于各种NLP任务,同时也可以通过微调来进一步优化,以适应特定任务的需求。
bert能干什么
BERT还是比较强大的,可以在多种NLP任务中发挥作用。
-
文本分类:BERT可以用于对文本进行分类,例如情感分析(判断文本是正面还是负面情感)、主题分类等。通过微调BERT模型,可以对不同的文本进行分类。
-
命名实体识别(NER):BERT可以识别文本中的命名实体,如人名、地名、组织名等。可以用于信息提取、文本注释等任务中。
-
问答系统(QA):BERT可以用于构建问答系统,它可以理解问题并在文本中找到相关的答案。在搜索引擎、智能助手和知识图谱等应用中具有重要价值。
-
机器翻译:BERT可以用于机器翻译任务,通过将源语言文本编码为BERT表示,然后将其解码为目标语言文本。
-
文本生成:BERT可以用于生成文本,包括生成摘要、自动化写作、对话生成等任务。结合生成型模型,BERT可以生成自然流畅的文本。
-
信息检索:BERT可以改进搜索引擎的性能,通过更好地理解用户查询来提供相关的搜索结果。
-
语言理解:BERT的预训练表示可以用于许多其他语言理解任务,如自动摘要、文本聚类、句法分析等。
-
语义相似度计算:BERT可以用于计算两个文本之间的语义相似度,这在信息检索和推荐系统中很有用。
-
情感分析:BERT可以分析文本中的情感,用于了解用户对产品、服务或事件的情感倾向。
-
对话系统:BERT可以用于构建智能对话系统,能够理解和生成自然语言对话。
bert如何用
使用BERT模型通常分为两个主要步骤:预训练和微调。
首先,对BERT进行预训练,生成一个预训练模型。预训练模型包含了在大规模文本语料库上学习到的单词、短语和句子的语义表示。
BERT应用分为预训练、微调、推理三个步骤。
预训练:首先要准备数据,需要大规模的文本数据。这些数据需要进行预处理,包括分词、标记化、去除停用词等,以便将其转化为模型可接受的格式。
然后,需要获取经过预训练的BERT模型,通常可以在互联网上或深度学习框架的模型库中找到预训练的BERT模型权重。使用预处理后的文本数据,对BERT模型进行预训练。这一步通常需要大量计算资源和时间,因此常常在大型计算集群或云平台上进行。
训练完成后,将生成预训练的BERT模型,供后续微调和应用。
微调:准备与该任务相关的标记化数据。例如,进行文本分类,那么需要一个包含文本和标签的数据集。加载之前预训练好的BERT模型权重,然后将其嵌入到任务特定模型中。使用任务数据对整个模型进行微调,以适应具体任务。微调的目标是通过反向传播算法来调整模型的权重,以最大程度地提高任务性能。在微调完成后,使用验证数据集来评估模型的性能。
推理:一旦微调完成并选择了最佳模型,就可以将该模型用于推理阶段,用来处理新的文本数据并产生预测或输出。对于新的文本数据,需要进行与预训练数据相同的预处理,包括分词、标记化等。将新数据传递给微调后的BERT模型,以获得模型的输出。
bert具体操作demo
在使用BERT之前,首先需要具备如下环境:
1.python 环境 我用的是3.8.5的
2.相应的引用
pip install bert
pip install bert-tensorflow
pip install bert-serving-server --user
pip install bert-serving-client --user
pip install tensorflow==1.13.13.代码下载
打开该地址后,页面搜索chinese,找到 如下内容。
 点击 BERT-Base, Chinese下载中文的预训练模型,也可以根据自己需要下载对应的模型。下载当前代码,使用pyCharm打开。
点击 BERT-Base, Chinese下载中文的预训练模型,也可以根据自己需要下载对应的模型。下载当前代码,使用pyCharm打开。
找到run_classifier.py文件,配置参数 运行它。
参数配置: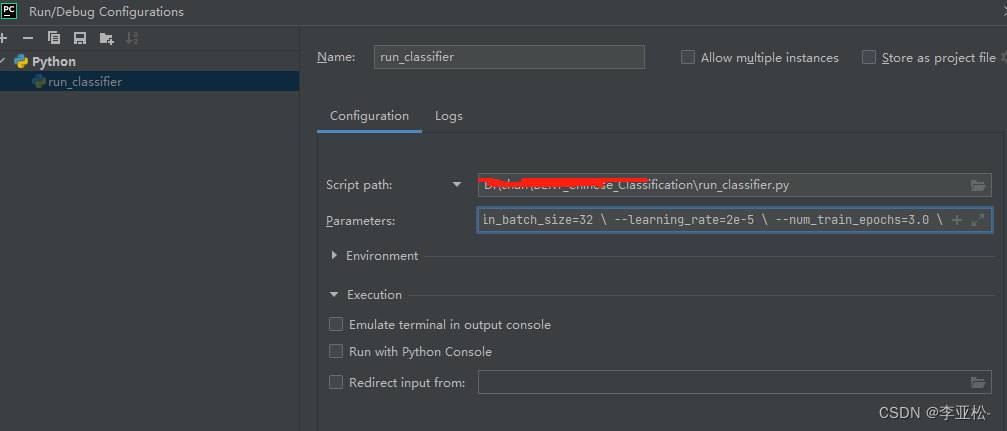 parameters中具体内容:
parameters中具体内容:
--data_dir=data \
--task_name=sim \
--vocab_file=../GLUE/BERT_BASE_DIR/chinese_L-12_H-768_A-12/vocab.txt \
--bert_config_file=../GLUE/BERT_BASE_DIR/chinese_L-12_H-768_A-12/bert_config.json \
--output_dir=sim_model \
--do_train=true \
--do_eval=true \
--init_checkpoint=../GLUE/BERT_BASE_DIR/chinese_L-12_H-768_A-12/bert_model.ckpt \
--max_seq_length=70 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \














 4545
4545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









