







2.1 NVMM
2.2 B+ Tree in NVMM
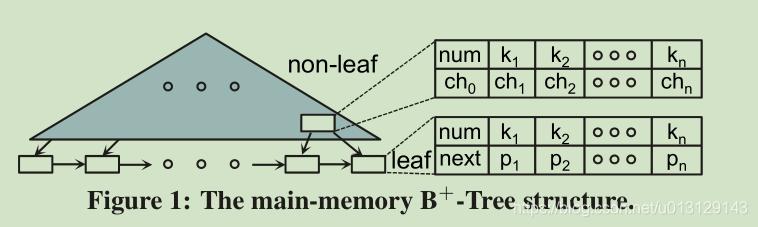
Compared to disk-based B + -Trees, the node size of main-
memory B + -Trees is typically a few cache lines large (e.g., 2–8
64-byte cache lines)
Moreover, nodes store pointers instead of page IDs for
fast accesses
In this paper, we choose prefetching B + -Trees
as our baseline main memory B + -Trees. The basic idea is to is-
sue CPU cache prefetch instructions for all cache lines of a node
before accessing the node. The multiple prefetches will retrieve
multiple lines from main memory in parallel, thereby overlapping
a large portion of the cache miss latencies for all but the first line
in the node
预取指令(CACHE) 来减少开销,大概就是把这个原理应用到他们的B+

A PCM-friendly B + -Tree consists of sorted non-leaf
nodes and unsorted leaf nodes. The former maintains good search
performance, while the latter reduces PCM writes for updates.
非叶子是 sorted 叶子是unsorted
2.3 Data Structure Inconsistency Problem
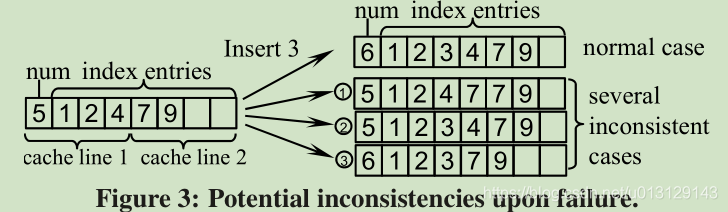
因为数据会从cache乱序输出到memory。
1.VM不会出现这种问题,因为 断电数据都消失了,无所谓乱不乱序了
2. disk-base数据库也不会这种问题,因为不能从CACHE直接到DISK
Compared to the memory buffer pool of disk-based database
systems, we do not have the same level of control for CPU caches
3.NVMM 会出现是因为可以永久保存,如果你flush cache 到NVMM 会永久保存, 例如F3图那样, 你存入的NODE 就是一个乱序的了.那么指针就乱指,就不能指向正确的数据块
2.4Clflush and Mfence Instructions

为了确保每个cache line flush 有序,必须一个clflush 一个mfence
clfush();
mfence();
图F4 不加CLF 就是只读
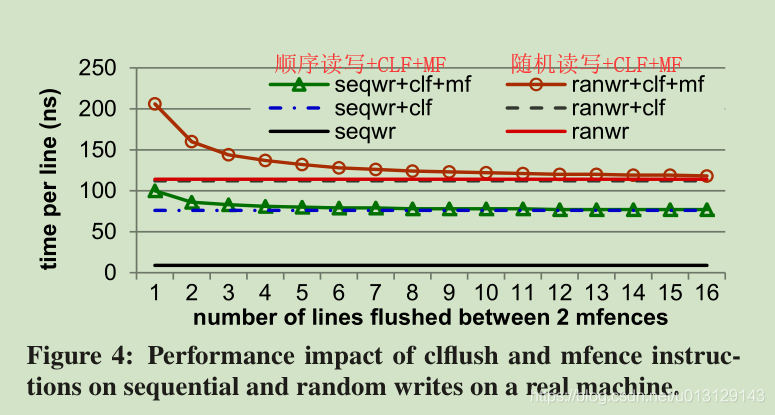
从图中看出,减少MFENCE的使用很重要
From the figure, we see that clflush significantly slows down
sequential writes, because clflush forces dirty cache lines to be
written back. This disrupts the CPU and the memory controller’s
optimizations for sequential memory accesses (e.g., combining mul-
tiple accesses to the same open memory row). In comparison, since
random writes are not amenable to such optimizations, clflush
has neglegible impact on random writes. Moreover, inserting an
mfence after every clflush incurs significant overhead for both
sequential and random writes, because the mfence waits for the
previous clflush to complete. This overhead is reduced as the
number of clflush -ed records between two mfence s increases.
Therefore, it is important to reduce the relative frequency of mfence .














 2863
2863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









