






高可用NAS集群技术
目录
高可用NAS集群技术
一、前言
二、集群NAS的介绍
(一)什么是集群NAS
(二)集群NAS的主流架构
(三)集群NAS的分类
三、集群存储高可用技术
(一)什么是集群高可用
(二)常用高可用技术介绍
(三)高可用的分类
四、集群高可用组件CTDB
(一)ctdb介绍
(二)ctdb的运行机制
(三)ctdb主要参数的含义
五、集群文件系统GlusterFS
六、常用的负载均衡技术介绍
(一)RR-DNS
(二)F5负载均衡器
(三)LVS
七、标准协议介绍
(一)NFS
(二)CIFS
(三)FTP
(四)ISCSI
(五)协议之间的对比
八、实践
(一)实践环境
(二)部署glusterfs集群
(三)配置高可用
(三)配置LVS自动负载均衡
(四)实践结果
九、总结
十、参考文档
一、前言
在大数据时代的今天,云计算、云存储高速发展以及物联网的兴起导致数据呈爆炸式增长,其中非结构数据更是占据了全球数据的90%,于是一种基于横向扩展(Scale-out)存储架构的集群NAS诞生了,有别于传统的SAN和NAS,是一种新的存储架构,主要面向文件级别的存储,不但集中了SAN和NAS的优点,还具备它们不具备的一些优点,如容量和性能线性扩展等。集群NAS随着不断的扩容,其性能也会随之提升,理论上,达到一定规模的集群NAS在性能上可以胜过一个SAN系统,并且其成本远远低于SAN系统。现今,集群NAS已经得到了全球市场的广泛认可,成为了主流的存储技术之一。在存储领域中,存储系统的高可用性一直是关注的重点,随着用户对于存储系统的可用性需求不断变化,高可用技术也在不断向前发展,从简单的双机热备到多节点的集群高可用,从底层磁盘的高可用到共享层服务的高可用,无论是从硬件层面还是软件层面都有显著的提升。本文将介绍一种可动态扩展、按需部署、具备透明故障切换的高可用集群NAS存储系统架构,主要基于开源分布式文件系统GlusterFS,高可用组件CTDB, Linux虚拟服务器LVS,以及标准协议(如NFS、CIFS、FTP等)部署搭建。
二、集群NAS的介绍
(一)什么是集群NAS
集群(Cluster)是由多个节点构成的一种松散耦合的计算节点集合,协同起来对外提供服务。集群NAS是指协同多个节点(即通常所称的NAS机头)提供高性能、高可用或高负载均衡的NAS(NFS/CIFS/FTP/)服务。(二)集群NAS的主流架构
从集群NAS的整体架构来看,是由存储子系统、NAS集群(机头)、客户端以及网络组成。存储子系统可以采用存储区域网络SAN、直接连接存储DAS或者面向对象存储设备OSD的存储架构。根据所采用的后端存储子系统的不同,可以把集群NAS分为SAN共享存储架构、集群文件系统架构和pNFS/NFSv4.1架构三种技术架构。1、SAN共享存储架构
其架构如图1所示,后端存储采用SAN,所有NAS集群节点通过光纤连接到SAN,共享所有的存储设备,通常采用SAN并行文件系统管理并输出POSIX接口到NAS集群。SAN并行文件系统通常需要元数据控制服务器,可以是专用的MDC,也可以采用完全分布的方式分布到SAN客户端上。NAS集群上安装SAN文件系统客户端即可实现对SAN共享存储的并发访问,然后运行NFS/CIFS服务为客户端提供服务。这里前端网络采用以太网,后面存储连接则采用SAN网络。
2、集群文件系统架构
其架构如图2所示,后端存储采用DAS,每个存储服务器直连各自的存储系统,通常为一组SATA磁盘,然后由集群文件系统统一管理物理分布的存储空间而形成一个单一命名空间的文件系统。实际上,集群文件系统是将RAID、Volume、File System的功能三者合一了。目前的主流集群文件系统一般都需要专用元数据服务或者分布式的元数据服务集群,提供元数据控制和统一名字空间,当然也有例外,如无元数据服务架构的GlusterFS。NAS集群上安装集群文件系统客户端,实现对全局存储空间的访问,并运行NFS/CIFS/FTP/ISCSI等服务对外提供NAS服务。NAS集群通常与元数据服务集群或者存储节点集群运行在相同的物理节点上,从而减少物理节点部署的规模,当然会对性能产生一定的影响。与SAN架构不同,集群文件系统可能会与NAS服务共享TCP/IP网络,相互之间产生性能影响,导致I/O性能的抖动。如果集群文件系统存储节点之间采用InfiniBand网络互联,可以消除这种影响,保持性能的稳定性,如ISILON、GlusterFS等支持使用InfiniBand网络。
3、pNFS/NFSv4.1架构
其架构如图3所示,实际是并行NAS,即pNFS/NFSv4.1,于2010年1月RFC 5661标准获得批准通过。它的后端存储采用面对对象存储设备OSD,支持FC/NFS/OSD多种数据访问协议,客户端读写数据时直接与OSD设备相互,而不像上述两种架构需要通过NAS集群来进行数据中转。这里的NAS集群仅仅作为元数据服务,I/O数据则由OSD处理,实现了元数据与数据的分离。这种架构更像原生的并行文件系统,不仅系统架构上更加简单,而且性能上得到了极大提升,扩展性非常好。
(三)集群NAS的分类
根据集群NAS的功能侧重点不一样,可以把集群NAS分为高性能集群NAS、高可用集群NAS、高负载均衡集群NAS三种类型。1、高性能集群NAS
高性能计算HPC(High Performance Computing),也称超级计算,高性能计算是一种数据密集型和计算密集型相结合的应用,对计算和I/O的处理能力都有较高的要求,存储系统已经成为决定高性能计算集群效率的重要因素。高性能计算集群NAS,简称HPC集群,致力于提供单个计算机所不能提供的强大的计算能力。高性能集群NAS用来运行一些模拟程序、对 CPU 非常敏感的程序、对时间敏感的并行程序等,这些程序在普通的硬件上运行需要花费大量的时间,使用高性能集群运行能够在很大程度上缩短运行时间,对于科学社区来说具有特殊的意义。2、高可用集群NAS
高可用性HA(High Availability),通常来描述一个系统经过专门的设计,采取一定措施减少系统服务中断时间,从而保持其服务的高度可用性。高可用集群NAS,致力于提供高度可靠的NAS服务。高可用性集群中的节点一般是一主一备,或者一主多备,通过备份提高整个系统可用性。最简单的就是一主一备,即集群有两个节点:一个节点是活动的,另外一个节点是备用的,不过它会一直对活动节点进行监视。一旦活动节点出现故障,备用节点就会接管它的工作,这样就能使得关键的系统能够持续工作。高可用比较关注集群中结点处理请求能力的对等性,因为一单主节点出现问题备用节点需要承受主节点所有的请求压力,一旦处理能力较弱有可能无法正常提供服务,从而失去高可用的作用。3、负载均衡集群NAS
负载均衡集群LBC(Load Balancing Cluster),将高并发的请求数据分发到不同的集群结点,尽量平衡系统所有资源的压力,从而提升整个集群对于请求的处理能力。负载均衡集群通常会在非常繁忙的 Web 站点上采用,它们有多个节点来承担相同站点的工作,每个获取 Web 页面的新请求都被动态路由到一个负载较低的节点上。负载均衡一般不关注集群中各节点对于请求的处理能力,很多时候会根据节点处理能力的不同而使用不同的分发策略,比如轮询,最小连接,最快响应等。三、集群存储高可用技术
(一)什么是集群高可用
集群的高可用性(HA,High Availablity)是指集群在非常规情况(如突发的系统崩溃、节点当掉、硬盘毁坏等)下能够正常提供存储服务,通过尽量缩短系统停机时间,以提高系统和应用的可用性。其工作原理是多台主机一起工作,各自运行一个或几个服务,各为服务定义一个或多个备用主机,当某个主机故障时,运行在其上的服务就可以被其它主机接管。(二)常用高可用技术介绍
副本(Replication)是将每个原始数据分块都镜像复制到另一存储介质上,从而保证在原始数据失效后,数据仍然可用并能通过副本数据恢复。在副本机制中,数据的可靠性和副本数是呈正相关,副本数越多,数据可用性越好,可靠性也越高,但也意味着更低的空间利用率(为副本数量分之一)、更高的数据管理复杂度以及以及更高的成本。纠删码(Erasure Code)作为一种前向错误纠正技术主要应用在网络传输中避免包的丢失,存储系统利用它来提高存储可靠性。纠删码技术通过冗余编码提高存储可用性,提供了很高的容错性,并且具备较低的空间复杂度和数据冗余度,存储利用率高,但编码方式复杂,需要大量计算并降低业务性能,且适用集群节点数量较多的情形。
高可用(HA,High Availability)集群通过一组计算机系统提供透明的冗余处理能力,从而实现不间断应用的目标。主备(Active/Standby)HA技术同样采用冗余技术获取高可用性,但存储资源浪费严重。全活(Active/Active)HA技术通过监控并将故障节点资源(IP、服务进程、业务数据等)切换至正常节点上,使整个系统连续不间断对外提供服务。这种HA技术不仅能够提高可用性,而且具备负载均衡功能,资源利用率高。HA技术的主要问题是资源切换期间会导致服务中断,通常只接管IP和服务进程资源,而业务数据或物理存储资源需要由外部系统进行管理。
(二)高可用的分类
按照逻辑层面的不同,可分为存储磁盘级的高可用、服务器级别的高可用、以及共享层的高可用。磁盘的高可用即损坏部分磁盘不影响集群的正常使用;服务器级别的高可用即损坏一个节点不会影响系统的正常使用;共享层的高可用,即是通过共享协议(SMB、NFS、FTP、HTTP、ISCSI等)的方式对用户提供具有全局统一存储空间的节点标准共享,当这个节点宕机,共享服务仍然能够正常访问。而本文所要介绍的高可用集群NAS技术则是从这这三个层面来构建高可用的。1、磁盘级的高可用
磁盘的高可用即损坏部分磁盘不影响集群的正常使用,通常使用 raid10 、 raid01 或者 raid5 等 raid 方式来保护磁盘数据,但是整个服务器节点宕机则 raid 就没有用处,这就涉及到了分布式文件系统层的高可用。2、服务器级的高可用
即损坏一个节点不会影响系统的正常使用,就目前来看开源的这些分布式文件系统都使用数据副本的方式来提供文件系统层的高可用,例如 HDFS , MFS 、 GlusterFS 等(Lustre 不提供数据冗余保护),都提供多副本的数据冗余保护。3、共享层的高可用
最后一个就是共享层的高可用。说到共享层的高可用,这就得说到通用集群存储的使用方式,通常 DFS 会提供一个统一命名空间给用户,当然,这也是分布式文件系统的设计最根本的目的,将零散的存储集合起来。但通常最后都是通过共享协议的方式将这个存储提供给用户,例如 SMB 、 NFS 或者 FTP 之类。若提供全局统一存储空间的节点对外提供标准共享,但恰巧这个节点宕机了,这就会导致共享中断,这就涉及到了共享层的高可用。本文中实践所使用的ctdb就是实现共享层高可用的主要组件。四、集群高可用组件CTDB
(一)ctdb介绍
CTDB(Clustere Trivial Database)是一种轻量级的集群数据库实现,在2006年,由Volker Lendecke and Andrew Tridgell等研发人员开始CTDB项目的研发工作,之后Ronnie Sahlberg也加入进来并成为了CTDB项目的维护者和主要研发人员,于2007年4月发布地一个可用版本,正式的CTDB源码可以从Ronnie Sahlberg的CTDB-git-repository中获得。CTDB最开始可以视为Samba的附属软件,主要用于处理Samba的跨节点消息以及在所有集群节点上实现分布式的TDB数据库。最开始CTDB是不支持Samba的,在2008年7月1日发布的Samba 3.2版本才逐渐开始支持,但仍然并不能完全的支持,直到2009年1月发布的Samba 3.3版本中才实现了完全的支持。现今,基于CTDB可以实现很多应用集群,不仅支持管理Samba,而且支持管理NFS、HTTPD、VSFTPD、ISCSI、WINBIND等应用,集群共享数据存储还支持GPFS、GFS(2)、Glusterfs、Luster、OCFS(2)等。
(二)ctdb的运行机制
CTDB 是 Samba、NFS、HTTPD、VSFTPD、ISCSI、WINBIND、LVS等使用TDB 数据库的集群实施,要使用CTDB,则必须有一个可用的集群文件系统,且该文件系统可为该集群中的所有节点共享。CTDB在这个集群的文件系统顶层提供集群的功能。CTDB 管理节点成员、执行恢复/故障切换、IP 重新定位以及监控管理服务的状态。在每个集群节点上都运行了一个CTDB的守护进程ctdbd,以Samba为例,应用服务并不是直接向其TDB数据库写入数据,而是与它的本地ctdbd守护进程进行交互通信。守护进程会通过网络与TDB数据库中的元数据进行交互通信。但是对于具体的数据写和读操作,一般是在本地存储上维护一个本地的副本。
CTDB拥有两种TDB文件,普通的和持久性的。根据不同的需求,CTDB对这两种TDB文件的处理方式完全不同,持久性的TDB文件会实时更新,并在每个节点上存储一个最新的副本,为了读写操作更快,持久性的TDB文件都是保存在在本地存储上而不是共享存储中。当想要写入到持久的TDB时,它会锁定整个CTDB数据库,执行读操作、写操作、事务提交操作最终都会被分发到所有节点,并在每个节点的本地写入。普通TDB文件是临时维护的,其原则是,每个节点不必知道数据库中的所有记录。只需道影响它自己的客户端连接的记录就足够了,所以即使某个节点当掉了,从而丢失了这个节点上所有的普通TDB记录,但对于其他节点是没有影响的。每个节点都有自己的角色,DMASTER (data master) 或者LMASTER (Location Master),但只有一个节点拥有当前权威的记录副本、i.e数据。如图4所示。

1、 Ctdb与Samba在集群中的模块关系

图4 Ctdb与Samba在集群中的模块关系图
CTDB监控Samba服务,可通过 rpcinfo 查看Samba状态,Samba 将用于切换的数据写入CTDB的tdb中,CTDB 同步到其它节点。
2、CTDB进程分析
CTDB 启动ctdb_daemon和ctdb_recoverd两个进程。(1)ctdb_daemon进程
ctdb_daemon进程通过epoll处理事件:定期查看各节点状态,当状态异常时,执行相应的处理。定期检查监控的服务状态,通过运行监控脚本,查询各个服务的运行状态。ctdb_daemon 负责与外部进行通信,提供 tdb 操作及处理来自其它节点的消息,并处理来自本节点ctdb_recoverd 的消息。定期检查检查ctdb_recoverd进程是否在运行,如果未运行,则重建该进程。将其它节点发给 ctdb_recoverd 的消息转给 ctdb_recoverd;当本节点是修复节点时(recmaster),将 rctdb_ecoverd 发出的修复消息转发给其它节点。处理自身消息,包括设置服务状态,TDB操作,IP takeover,来自节点recoverd的消息等。将修复相关的请求转给ctdb_recoverd进程处理,包括选举修复节点,强制重新分配公共IP,以及将修复消息转发给其它节点等。(2)ctdb_recoverd进程
ctdb_recoverd进程定期向ctdb_daemon查询系统状态;当需要修复时,发起选举过程,选出修复节点。在需要修复且被选为修复节点时,启动修复过程:通知所有节点进入修复状态、修复TDB、公共IP重新分配对接管的公共IP,主动触发TCP重连。CTDB本身不是HA解决方案,但与集群文件系统相结合,它可以提供一种简便高效的HA集群解决方案。集群配置两组IP,Private IP用于heartbeat和集群内部通信;Public IP用于对外提供虚拟访问IP,当内部的节点发生宕机故障时,CTDB将调度其他可用节点接管其原先分配的Public IP,故障节点恢复后,漂移的Public IP会重新被接管,保证服务不中断。这个过程对客户端是透明的,保证应用不会中断,也就是我们这里所说的高可用HA。
(三)ctdb主要参数的含义
CTDB_NODES:指定包含该集群节点列表文件的位置。该参考只列出该集群节点 IP 地址的/etc/ctdb/nodes文件。每个节点中只有一个接口IP可用于集群CTDB沟通并为客户端提供服务。建议每个集群节点都有两个网络接口,这样一个接口设置可专门用于集群CTDB 沟通,而另一个接口设置可专门用于公用客户端访问。在此使用正确的集群网络 IP 地址,并保证在cluster.conf文件中使用同一主机名IP 地址。同样,在public_addresses文件中为客户端访问使用正确的公共网络接口。/etc/ctdb/nodes 文件在所有节点中的一致性至关重要,因为顺序很重要,同时如果 CTDB 在不同节点中找到的信息不同就会失败。CTDB_PUBLIC_ADDRESSES:指定列出用来访问由这个集群导出的 Samba 共享的 IP 地址的文件位置。这些是您要在 DNS 中为集群的 Samba 服务器名称配置的 IP 地址,也是 CIFS 客户端将要连接的地址。将集群 Samba 服务器名称配置为有多个 IP 地址的 DNS 类型A记录,并在该集群的客户端中发布轮询DNS。在这个示例中,我们在所有 /etc/ctdb/public_addresses文件列出的地址中配置轮询 DNS 条目csmb-server。DNS将发布那些在集群中以轮询方式使用这个条目的客户端。注:网卡名必须是节点拥有的网卡名。
CTDB_RECOVERY_LOC:指定 CTDB 内部用来恢复的锁定文件。这个文件必须位于共享存储中,这样所有集群节点都可访问。本小节中的示例使用 GFS2 文件系统,该文件系统会挂载于所有节点的 /mnt/ctdb。这与将要导出 Samba 共享的 GFS2 文件系统不同。这个恢复锁定文件的目的是防止出现裂脑(split-brain)。使用 CTDB 较新的版本(1.0.112 及之后的版本)时,可自选是否指定这个文件,只要有防止裂脑的机制即可。
CTDB_MANAGES_SAMBA:当将其设定为 yes 启用它时,如果需要提供服务迁移/故障切换,则指定允许 CTDB 启动和停止 Samba 服务。启用 CTDB_MANAGES_SAMBA 时,应禁用 smb 和 nmb 守护进程的自动 init 启动。配置的是cifs的集群高可用,则应该在Samba的配置中加上如下配置:
# vi /etc/samba/smb.conf
clustering = yes
idmap backend = tdb2
private dir = /var/ctdb/persistent
CTDB_MANAGES_NFS:当将其设定为 yes 启用它时,如果需要提供服务迁移/故障切换,则指定允许 CTDB 启动和停止nfs服务。启用CTDB_MANAGES_NFS时,应禁用nfs-server守护进程的自动 init 启动,方法为执行以下命令:# systemctl stop nfs-server、# systemctl disable nfs-server。注:这里所指定的NFS是指Linux内核自带的nfs服务,即内核态nfs。CTDB 监控 NFS 服务,可通过调用 rpcinfo 查看 nfs 的运行状态。
如果配置的是内核态nfs的高可用,还应该在nfs的配置中加上如下配置:
vi /etc/sysconfig/nfs
NFS_TICKLE_SHARED_DIRECTORY=/mnt/ctdb/nfs-tickles
NFS_HOSTNAME=yang-nfs
STATD_PORT=874
STATD_OUTGOING_PORT=876
MOUNTD_PORT=892
RQUOTAD_PORT=875
LOCKD_UDPPORT=872
LOCKD_TCPPORT=872
STATD_SHARED_DIRECTORY=/mnt/ctdb/nfs-state
STATD_HOSTNAME="$NFS_HOSTNAME -H /etc/ctdb/statd-callout"
RPCNFSDARGS="-N 4"
CTDB_MANAGES_VSFTPD:当将其设定为 yes 启用它时,如果需要提供服务迁移/故障切换,则指定允许 CTDB 启动和停止ftp服务。启用CTDB_MANAGES_VSFTPD时,应禁用proftpd守护进程的自动 init 启动, #systemctl stop vsftpd.service、#systemctl disable vsftpd.service或者# systemctl stop proftpd、# systemctl disable proftpd。
CTDB_MANAGES_ISCSI:当将其设定为 yes 启用它时,如果需要提供服务迁移/故障切换,则指定允许 CTDB 启动和停止iscsi服务。启用CTDB_MANAGES_ISCSI时,应禁用tgtd守护进程的自动 init 启动,方法为执行以下命令:# systemctl stop tgtd、# systemctl disable tgtd
CTDB_START_ISCSI_SCRIPTS:指定共享存储的目录,目录中包含以公网IP命名的.sh脚本,如192.168.3.93.sh,脚本的主要内容是创建target、attach a lun、设置lun的权限等。
CTDB_MANAGES_WINBIND,当将其设定为 yes 启用它时,则指定 CTDB 可根据需要启动和停止 winbind 守护进程。如果在 Windows 域或在 active directory 安全模式中使用 CTDB 时,应该启用它。启用 CTDB_MANAGES_WINBIND 时,应禁用 winbind 守护进程的自动 init 启动,方法为执行以下命令:# systemctl stop windinbd、# systemctl disable windinbd
CTDB 作为管理共享服务以及对外提供虚拟 IP 连接的组件,其虽然管理SMB、NFS、FTP以及ISCSI服务等的启停,监控服务的状态,但其内部并不集成这个共享服务,只是说将这些共享统一管理,所以服务的单独重启之类的操作不会影响。但是若想单独停止某一个共享服务则无法做到,因为 CTDB 会定时的对各个服务状态进行检测,若检测到服务异常,它会进行服务的重启操作。
五、集群文件系统GlusterFS
GlusterFS(Gluster File System)是一种开源的分布式文件系统,主要由ZRESEARCH 公司开发,在2011年被Red Hat红帽以1.36亿美元收购。GlusterFS具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。借助TCP/IP或InfiniBand RDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据,基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。GlusterFS还采用了无元数据服务器的系统架构,即GlusterFS中不存在元数据服务器,而只将节点分为客户端节点和服务器节点,其中客户端节点负责处理客户端请求,建立数据传输通道,实现对客户端请求的访问控制,而服务器节点则负责实现数据与元数据的存储、复制和一致性等功能。
GlusterFS同时还是模块化堆栈式的架构设计,模块称为Translator,Translators是GlusterFS提供的一种强大文件系统功能扩展机制,这一设计思想借鉴于GNU/Hurd微内核操作系统。GlusterFS中所有的功能都通过Translator机制实现,借助这种良好定义的接口可以高效简便地扩展文件系统的功能。在Glusterfs中,每个translator都有自己的全局命名空间,并且使用自己的机制进行独立的维护和管理。
Gluster存储服务支持NFS、CIFS、HTTP、FTP等标准协议以及Gluster原生协议,完全与POSIX标准兼容。GlusterFS中的客户端节点在确定目标文件所在服务器节点时会采用DHT(DistributedHashTable)分布式哈希算法进行寻址,先将服务器节点的地址空间分区并统一编址映射到DHT环上,再由每个服务器节点管理自己的地址空间和数据,使得对每个文件的读写都能通过一次哈希运算寻址到对应的存储单元分区,实现整个文件系统的寻址和存储。在DHT算法的帮助下,GlusterFS中的客户端节点和服务器节点之间实现了对等的点对点数据访问,所有的客户端节点均可直接寻址到对应服务器进行数据读写,从而避免了传统分布式文件系统中存在的元数据服务器容易成为热点的问题,也提高了整个系统的可靠性。在GlusterFS的服务器上,通过将服务器的本地文件系统目录作为一个虚拟磁盘,再由多个服务器上的虚拟磁盘组成了虚拟卷,以对外提供服务。
六、常用的负载均衡技术介绍
(一)RR-DNS
RR-DNS是一种常用的负载均衡(load balance)最方法,它为同一个主机名配置多个IP地址,在应答DNS查询时根据Round Robin算法返回不同的IP地址,客户端使用返回的IP连接主机,从而实现负载均衡的目的。RR-DNS负载均衡方法的优点是简单、灵活、方便、成本低,客户端和服务端都不要作修改(除配置DNS信息之外),而且集群节点可以跨WAN。RR-DNS的问题是无法感知集群节点负载状态并进行调度,对故障节点也会进行调度,可能造成额外的网络负载,不够均衡,容错反应时间长。(二)F5负载均衡器
负载均衡器是一种采用各种分配算法把网络请求分散到一个服务器集群中的可用服务器上去,通过管理进入的Web数据流量和增加有效的网络带宽,从而使网络访问者获得尽可能最佳的联网体验的硬件设备。F5是负载均衡产品的一个品牌,其地位类似于诺基亚在手机品牌中的位置。F5负载均衡器是F5公司研发的一款产品,用来在数据流量过大的网络中分担网络的流量,实现合理的分配网络中的业务流量,使之不至于出现一台设备过忙,一台不能发挥作用,使俩台设备合理的分担网络流量的负担。除了F5以外,Radware、Array、A10、Cisco、深信服等都是负载均衡的牌子,但由于F5在这类产品中影响最大,所以经常说F5负载均衡。基于F5负载均衡器设备的方式,虽然可以直接通过智能交换机实现,处理能力更强,而且与系统无关,但是缺点更是明显,首先是成本高,体现在设备贵、冗余配置成本高等方面,而且在集群中由于负载均衡设备是单点配置,如果出了问题,集群就不可用了;其次,负载均衡器设备只是从网络层来判断,而不管实际系统与应用的状态,往往就会出现网络带宽没有跑满,但系统处理能力已经不行(如CPU、内存等)。
(三)LVS
1、什么是LVS
LVS(Linux Virtual Server),Linux虚拟服务器,是章文嵩博士在1998年5月成立的一个开源项目,在LINUX平台下实现基于IP负载均衡技术和内容请求分发技术,提供Linux平台下的集群负载平衡功能。LVS是一种高效的Layer-4交换机,可为物理集群构建一个高扩展和高可用的虚拟服务器,以单一IP代表整个集群对外提供服务。相对于RR-DNS,LVS可以有效弥补其不足之外,配置稍显复杂。LVS集群采用IP负载均衡技术。调度器具有很好的吞吐率,将请求均衡地转移到不同的服务器上执行,结合健康检测功能调度器自动屏蔽掉服务器的故障,结合High Availability技术从而将一组服务器构成一个高性能的、高可用的虚拟服务器。整个服务器集群的结构对客户是透明的,而且无需修改客户端和服务器端的程序。为此,在设计时需要考虑系统的透明性、可伸缩性、高可用性和易管理性。目前支持VS/NAT、VS/TUN、VS/DR三种IP负载均衡技术和以及rrr|wrr|lc|wlc|lblc|lblcr|dh|sh|sed|nq等十种调度算法。
2、LVS的组成
LVS主要由负载调度器、服务器池以及共享存储三部分组成。负载调度器(load balancer),它是整个集群对外面的前端机,负责将客户的请求发送到一组服务器上执行,而客户认为服务是来自一个IP地址(我们可称之为虚拟IP地址)上的;服务器池(server pool),是一组真正执行客户请求的服务器,执行的服务有WEB、MAIL、FTP和DNS等;共享存储(shared storage),它为服务器池提供一个共享的存储区,这样很容易使得服务器池拥有相同的内容,提供相同的服务。3、LVS的三种工作模式
LVS主要有三种工作模式,即VS-NAT,VS-TUN,VS-DR。VS-NAT模式,集群中的物理服务器可以使用任何支持TCP/IP操作系统,物理服务器可以分配Internet的保留私有地址,只有负载均衡器需要一个合法的IP地址。缺点是扩展性有限,当服务器节点数据增长到20个以上时,负载均衡器将成为整个系统的瓶颈,因为所有的请求包和应答包都需要经过负载均衡器再生。
VS-TUN模式,负载均衡器只负责将请求包分发给物理服务器,而物理服务器将应答包直接发给用户。所以负载均衡器能处理很巨大的请求量,负载均衡器不再是系统的瓶颈。 这种方式的不足是,需要所有的服务器支持"IP Tunneling"协议。
VS-DR模式,和VS-TUN相同,负载均衡器也只是分发请求,应答包通过单独的路由方法返回给客户端。与VS-TUN相比,VS-DR这种实现方式不需要隧道结构,因此可以使用大多数操作系统做为物理服务器。它的不足是,要求负载均衡器的网卡必须与集群物理网卡在一个物理段上。VS/DR模式下可以极大地提高系统的伸缩性。
七、标准协议介绍
(一)NFS
NFS(Network File System),网络文件系统,是一个用于提供NFS服务的开源软件,1980年由Sun公司开发,于1984年向外公布,用于向Linux用户提供NFS服务。它允许网络中的计算机之间通过TCP/IP网络共享资源。在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样。NFS最初则应用于UNIX操作系统下,他允许Server借助NFS导出一个或多个可供远程客户端共享的目标目录,客户端Mount(挂载) server上的目录,实现对文件资源的共享。 NFS自带Cache,可提高访问效率。
(二)CIFS
SMB(Server Message Block),服务器消息块(Server Message Block,缩写为SMB)协议是网络文件共享协议,它允许应用程序或终端用户从远端的文件服务器访问文件资源。1996年,微软提出将SMB改称为CIFS(Common Internet File System)网络文件共享系统,此外微软还加入了许多新的功能,比如符号链接、硬链接、提高文件的大小。CIFS(Common Internet File System)网络文件共享系统,是基于客户端/服务器模式,面向连接的,基于TCP/IP或IPX/SPX协议,使用通过类似三次握手的三个交互的交互模式。Samba是一个用于提供CIFS(通用Internet文件系统)服务的开源软件,用于向windows用户提供CIFS服务,Samba是对SMB和微软的扩展的重新实施,它是自由软件,包括服务器和命令行客户端。Linux内核包括两个SMB客户端实施,它们使用虚拟文件系统通过标准文件系统应用程序接口提供接触SMB服务器上的文件。
(三)FTP
FTP(File Transfer Protocol),文件传输协议,用于Internet上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的FTP应用程序,而所有这些应用程序都遵守同一种协议以传输文件。FTP提供交互式访问,允许客户致命文件的类型和格式,并允许文件具有存取权限,它屏蔽了计算机系统的细节,因此适用于在异构网络中任意计算机之间,它在工作中,首先要获取一个本地文件的副本,如果对文件进行传输或修改,也都是针对副本操作。(四)ISCSI
iSCSI(Internet SCSI),Internet小型计算机系统接口,是一种基于 TCP/IP的协议,用来建立和管理 IP 存储设备、主机和客户机等之间的相互连接,并创建存储区域网络(SAN),由IBM公司研究开发。SAN 使得 SCSI 协议应用于高速数据传输网络成为可能,这种传输以数据块级别(block-level)在多个数据存储网络间进行。SCSI 结构基于客户/服务器模式,其通常应用环境是:设备互相靠近,并且这些设备由 SCSI 总线连接。iSCSI 的主要功能是在 TCP/IP 网络上的主机系统(启动器 initiator)和存储设备(目标器 target)之间进行大量数据的封装和可靠传输过程。此外,iSCSI 提供了在 IP 网络封装 SCSI 命令,且运行在 TCP 上。
(五)协议之间的对比
NFS独立于传输层,可使用TCP或UDP协议,适用于文件存储,操作的对象是源文件。主要在Unix、Linux下使用,需要专门的客户端,允许Server借助NFS导出一个或多个可供远程客户端共享的目标目录,客户端Mount(挂载)server上的目录,实现对文件资源的共享。NFS自带Cache,可提高访问效率。从V4开始有连接状态协议,可自行恢复连接过程。FTP是一种基于传输层的应用层协议,为用户提供了一种交互式的访问服务,不限制文件的类型和格式,允许文件具有存取权限。适用于文件存储,操作的对象是源文件的副本,无论是对文件进行传输还是修改,都需要先获取一个源文件的副本。其客户端是集成在操作系统内部的,搭建服务后直接访问就行。有连接状态,可恢复连接过程(副本)。FTP服务器工具数量多,功能强大,可以针对客户的操作可以提供强大方便的管理功能。
CIFS是基于客户端/服务器模式,面向连接的,基于TCP/IP或IPX/SPX协议,使用通过类似三次握手的三个交互的交互模式。适用于文件存储,操作的对象是源文件,其客户端集成在操作系统内部,无连接状态,不可自行恢复连接过程。
ISCSI是SCSI协议中的一种传输协议,把SCSI命令和块数据封装在TCP中,然后在IP网络中传输,主要是利用成熟的IP网络技术来实现和延伸SAN。适用于块存储,其客户端,也是集成在系统内部,Linux下需要安装。
八、实践
(一)实践环境

(二)部署glusterfs集群
1、安装gluster
安装gluster通常有三种方式,编译安装、RPM安装、yum安装。(1)编译安装
从网站https://download.gluster.org/pub/gluster/glusterfs/3.10/3.10.3/下载glusterfs-3.10.3.tar.gz,然后编译安装。首先配置编译环境,安装常用的软件包、工具包,命令如下:#yum -y install autoconf libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel zip unzip ncurses ncurses-devel curl curl-devel e2fsprogs e2fsprogs-devel krb5-devel libidn libidn-devel openssl openssh openssl-devel nss_ldap openldap openldap-devel openldap-clients openldap-servers libxslt-devel libevent-devel ntp libtool-ltdl bison libtool vim-enhanced python wget lsof iptraf strace lrzsz kernel-devel kernel-headers pam-devel Tcl/Tk cmake ncurses-devel bison setuptool popt-devel net-snmp screen perl-devel pcre-devel net-snmp screen tcpdump rsync sysstat man iptables sudo idconfig git system-config-network-tui bind-utils update arpscan tmux elinks numactl iftop bwm-ng flex
然后解压glusterfs包,使用命令#./configure;#make;#make install进行安装。
(2)使用RPM包安装
从网站https://buildlogs.centos.org/centos/7/storage/x86_64/gluster-3.10/下载glusterfs相应的rpm安装包以及依赖包,使用命令:#rpm -ivh 进行安装。(3)yum安装
首先,搜索gluster的软件源# yum search centos-release-gluster
然后,安装相应gluster版本的软件源
# yum install centos-release-gluster10
最后安装需要的gluster软件包
# yum install -y glusterfs glusterfs-server glusterfs-fuse glusterfs-cli glusterfs-geo-replication
(4)安装好后,启动和设置开机自动启动glusterd服务
#systemctl glusterd start \\启动glusterd服务#systemct enable glusterd \\设置开机启动
2、部署gluster集群准备工作
(1)编辑每个节点的/etc/hosts文件
#vi /etc/hosts添加集群中每个节点的主机名和主机的IP地址的对应关系,如下:
192.168.2.93 node93
192.168.2.94 node94
(2)配置节点间ssh无密码访问
集群中每个节点相互配置ssh无密码访问,使用命令#ssh-keygen,#ssh-copy-id hostname/ip。
注:配置ssh无密码访问不是必要的。
(3)对每个节点进行时间同步
A.手动设置时间# date //查看系统时间是否正确,正确的话则忽略下面两步
# date -s "2017-09-2419:05:05" //设置系统时间
# hwclock -w //写入硬件时间
B.使用ntp服务同步时间(推荐)
# yum install -y ntp //安装ntp
# systemctl status ntpd //查看ntpd服务是否运行
# systemctl stop ntpd //如果ntpd服务正在运行,则停止服务
# ntpdate time.nist.gov //同步国际时间
(4)关闭防火墙
Centos 7.2 minimal安装时,默认不会安装防火墙,如果安装了防火墙,则需要关闭它,命令如下:# systemctl stop firewalld.service //停止firewall
# systemctl disable firewalld.service //禁止firewall开机启动
(5)关掉selinux
命令查看出selinux的状态,命令# sestatus -v或者# getenforce目前 SELinux 支持三种模式,分别如下:
•enforcing:强制模式,代表 SELinux 运作中,且已经正确的开始限制 domain/type 了;
•permissive:宽容模式:代表 SELinux 运作中,不过仅会有警告讯息并不会实际限制 domain/type 的存取。这种模式可以运来作为 SELinux 的 debug 之用;
•disabled:关闭,SELinux 并没有实际运作。
A.永久方法 – 需要重启服务器(推荐)
编辑# vi /etc/selinux/config,改为SELINUX=disabled,然后重启服务器# reboot。
B.临时方法 – 设置系统参数,服务器重启后失效
使用命令# setenforce 0
附:
# setenforce 1 设置SELinux 成为enforcing模式
# setenforce 0 设置SELinux 成为permissive搜索模式
3、创建GlusterFS集群,创建卷
(1)创建集群
[root@node93 ~]# gluster peer probe node94(2)创建卷,启动卷
[root@node93 ~]# gluster volume create vol-rep replica 2 node93:/data/ebdbbd28-b7b1-4095-b124-c8d7b2d0103d/brick/ node94:/data/ec16b3ce-b304-4c4a-8fd8-372e4587e629/brick[root@nodoe93 ~]# gluster volume start vol-rep
(3)初始化卷,对卷设置相应的参数值
[root@node93 ~]# gluster volume set vol-rep user.cifs disable[root@node93 ~]# gluster volume set vol-rep nfs.disable true
[root@node93 ~]# gluster volume set vol-rep network.ping-timeout 5
[root@node93 ~]# gluster volume set vol-rep network.frame-timeout 5
(4)在两个节点上分别mount以上创建的卷
[root@node93 ~]# mount -t glusterfs node93:vol-rep /mnt/data[root@node94 ~]# mount -t glusterfs node94:vol-rep /mnt/data
(三)配置高可用
1、安装相应的软件包
#yum -y install ctdb samba samba-common samba-winbind-clients nfs-utils2、配置ctdb
(1)在每个节点上备份原配置文件:
[root@node93 ~]# mv /etc/sysconfig/ctdb{,.old}[root@node94 ~]# mv /etc/sysconfig/ctdb{,.old}
(2)CTDB需要一个共享区域在创建lock,还需要创建共享目录:
[root@node93 ~]# mkdir /mnt/data/lock /mnt/data/share /mnt/data/nfs-share(3)然后编辑ctdb配置文件:
[root@node93 ~]# vi /mnt/data/lock/ctdbCTDB_RECOVERY_LOCK=/mnt/data/lock/ctdb.lock
CTDB_SET_RecoveryBanPeriod=5
CTDB_SET_MonitorInterval=5
CTDB_NOTIFY_SCRIPT=/etc/ctdb/notify.sh
CTDB_LOGFILE=/var/log/ctdb.log
CTDB_SAMBA_SKIP_SHARE_CHECK=no
CTDB_FTP_SKIP_SHARE_CHECK=no
CTDB_NFS_SKIP_SHARE_CHECK=no
CTDB_MANAGES_WINBIND=no
CTDB_MANAGES_SAMBA=no
CTDB_MANAGES_VSFTPD=no
CTDB_MANAGES_NFS=no
CTDB_MANAGES_ISCSI=no
CTDB_MANAGES_LDAP=no
CTDB_DEBUGLEVEL=ERR
CTDB_PUBLIC_ADDRESSES=/etc/ctdb/public_addresses
CTDB_NODES=/etc/ctdb/nodes
(4)然后在两个节点上把配置文件链接到原来ctdb配置文件的位置:
# ln -s /mnt/data/lock/ctdb /etc/sysconfig/ctdb(5)配置public_addresses文件
创建提供对外访问的/etc/ctdb/public_addresses文件,里面是VIP地址列表,如下:# vi /mnt/data/lock/public_addresses
192.168.3.93/24 eth0
192.168.3.94/24 eth0
最后将配置文件分别在两个节点上链接到相应位置
# ln -s /mnt/data/lock/public_addresses /etc/ctdb/public_addresses
注意:public IP所指定的网卡名必须是本机拥有的网卡名。这是由于Centos7中,对于网卡名提供了不同的命名规则,默认是基于固件、拓扑、位置信息来分配命名。虽然命名全自动的、可预知的,但是是比eth0、wlan0更难读,还容易造成不同主机中网卡名完不一样。
(6)配置nodes
创建提供服务的实际服务器IP列表/etc/ctdb/nodes文件,里面是实际服务器的IP地址列表,如下:# vi /mnt/data/lock/nodes
192.168.2.93
192.168.2.94
注意:ctdb 的nodes和public IP最好是不同网段。
最后将配置文件分别在两个节点上链接到相应位置。
# ln -s /mnt/data/lock/nodes /etc/ctdb/nodes(7)在每个节点上,设置ctdb服务为开机自启动,然后启动ctdb服务;
# systemctl enable ctdb.service# systemctl start ctdb.service
(8)使用下列命令来确定服务是否已经正常运行起来;
[root@nodoe93 ~]# ctdb status[root@nodoe93 ~]# ctdb ip
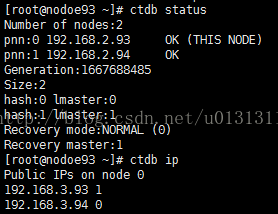
这时候集群间节点的高可用就配置完成了,当node93或node94中任意一个节点当掉时,VIP都会飘到另一节点上,如下所示:
[root@nodoe93 ~]# ctdb disable

3、配置NFS的高可用
由于集群NAS中所使用的集群文件系统是GlusterFS,所以关于nfs存在两种形态,即内核态nfs以及用户态nfs。其中内核态nfs指Linux,内核自带的nfs,用户态nfs指是GlusterFS自带的nfs服务。注:两种形态的nfs服务是互斥的。(1)配置内核态nfs服务的高可用
a.修改修改ctdb配置文件,把关于ctdb配置中关于nfs的配置参数值改为yes。[root@node93 ~]# vi /mnt/data/lock/ctdb
CTDB_NFS_SKIP_SHARE_CHECK=yes
CTDB_MANAGES_NFS=yes
b.在每个节点上备份原配置文件:
# mv /etc/sysconfig/nfs{,.old}
# mv /etc/exports{,.old}
nfs的配置如下:
# vi /mnt/data/lock/nfs
NFS_TICKLE_SHARED_DIRECTORY=/mnt/data/lock/nfs-tickles
NFS_HOSTNAME=nfs-server
STATD_PORT=874
STATD_OUTGOING_PORT=876
MOUNTD_PORT=892
RQUOTAD_PORT=875
LOCKD_UDPPORT=872
LOCKD_TCPPORT=872
STATD_SHARED_DIRECTORY=/mnt/data/lock/nfs-state
STATD_HOSTNAME="$NFS_HOSTNAME -H /etc/ctdb/statd-callout"
RPCNFSDARGS="-N 4"
exports的配置如下:
# vi /mnt/data/lock/exports
/mnt/data/nfs-share *(rw,fsid=1235)
最后将配置文件分别在两个节点上链接到相应位置。
# ln -s /mnt/data/lock/nfs /etc/sysconfig/nfs
# ln -s /mnt/data/lock/exports /etc/exports
c.在每个节点上,停止nfs的服务,并关闭服务在操作系统启动时的自动启动,使用ctdb服务来控制nfs服务的启停,重启ctdb服务,命令如下;
# systemctl stop nfs-server.service
# systemctl disable nfs-server.service
# systemctl restart nfs-server.service
d.这样一个高可用的内核态nfs共享服务就配置完成了,可在Linux系统下挂载访问,如下:

(2)配置用户态nfs服务的高可用(推荐)
a.修改修改ctdb配置文件,把关于ctdb配置中关于nfs的配置参数值改为no。[root@node93 ~]# vi /mnt/data/lock/ctdb
CTDB_NFS_SKIP_SHARE_CHECK=no
CTDB_MANAGES_NFS=no
b.在每个节点上,停止内核态nfs服务,并关闭nfs服务的开机自动启动,最后重启ctdb服务,命令如下;
# systemctl stop nfs-server.service
# systemctl disable nfs-server.service
# systemctl restart nfs-server.service
c.开启gluster卷的nfs服务,即用户态的nfs
[root@node93 ~]# gluster volume set vol-rep nfs.disable false
使用命令# gluster v info vol-rep 查看卷vol-rep的详细信息如下:



4、配置samba的高可用
(1)在每个节点上把原来的Samba配置文件备份,然后编写Samba配置:
# mv /etc/samba/smb.conf /etc/samba/smb.conf.old# vi /mnt/data/lock/smb.conf
[global]
netbios workgroup = MYGROUP
name = MYSERVER
security = user
encrypt passwords = yes
passdb backend = tdbsam
server string = Samba Server Version %v
log file = /var/log/samba/log.%m
max log size = 50
guest account = nobody
map to guest = bad password
posix locking = no
max protocol = SMB3
dos charset = cp936
unix charset = cp936
clustering = yes
#idmap backend = tdb2
idmap config * : backend = tdb2
private dir = /var/ctdb/persistent
#reset on zero vc = yes
kernel share modes = no
kernel oplocks = no
stat cache = no
[public]
comment = public share
path = /mnt/data/share
read only = No
browseable = yes
guest ok = yes
(2)然后将配置文件分别在两个节点上链接到相应位置:
#ln -s /mnt/data/lock/smb.conf /etc/samba/smb.conf修改完成后,用下面的命令测试 smb.conf是否有误:
#testparm
显示的结果里注意Loaded services file OK,说明配置文件没有错。
(3)修改ctdb配置文件,把关于ctdb关于Samba的配置参数值改为yes。
[root@node93 ~]# vi /mnt/data/lock/ctdbCTDB_SAMBA_SKIP_SHARE_CHECK=yes
CTDB_MANAGES_SAMBA= yes
(4)在每个节点上,停止samba的smb和nmb服务,并关闭服务在操作系统启动时的自动启动,使用ctdb服务来控制Samba服务的启停,重启ctdb服务,命令如下;
# systemctl stop smb.service nmb.service# systemctl disable smb.service nmb.service
# systemctl restart ctdb.service
(5)这样一个高可用的CIFS共享服务就配置完成了,可以在Windows操作系统的电脑或者任何支持SMB/CIFS协议的电脑上通过访问\\192.168.3.93\public 或者\\192.168.3.94\public 使用该存储了,如下:

(三)配置LVS自动负载均衡
已经成功构建了高可用集群NAS,所有NAS机头均可对外提供NAS服务,并且相互之间具备高可用的特性,那么接下来就是配置自动负载均衡(load balance)的功能,负载均衡最为常用的一种方法是RR-DNS,它为同一个主机名配置多个IP地址,在应答DNS查询时根据Round Robin算法返回不同的IP地址,客户端使用返回的IP连接主机,从而实现负载均衡的目的。1、安装软件
[root@node94~]# yum install ipvsadmvip和rip必须在同一个网段。VS/DR通过改写请求报文的MAC地址,将请求的包发送到realserver上,不改变包的源和目标的IP地址,然后realserver直接回复客户端,不再经过LVS调度器,这样大大的减轻了LVS的负担。
2、配置LVS master
编写shell脚本lvsmaster.sh,并在master节点(node93)上运行,其配置内容如下:[root@node93 ~]# vi /mnt/data/lock/lvsmaster.sh
#!/bin/sh
VIP=192.168.3.95
RIP1=192.168.3.93
RIP2=192.168..3.94
PORT=0
. /etc/rc.d/init.d/functions
case "$1" in
start)
#!/bin/sh
VIP=192.168.3.95
RIP1=192.168.3.93
RIP2=192.168.3.94
PORT=0
. /etc/rc.d/init.d/functions
case "$1" in
start)
echo "start LVS of DirectorServer"
#Set the Virtual IP Address
/sbin/ifconfig eno16777736:1 $VIP broadcast $VIP netmask 255.255.255.255 up
/sbin/route add -host $VIP dev eno16777736:1
#Clear IPVS Table
/sbin/ipvsadm -C
#Set Lvs
/sbin/ipvsadm -A -t $VIP:$PORT -s rr -p 60
/sbin/ipvsadm -A -u $VIP:$PORT -s rr -p 60
/sbin/ipvsadm -a -t $VIP:$PORT -r $RIP1:$PORT -g
/sbin/ipvsadm -a -t $VIP:$PORT -r $RIP2:$PORT -g
/sbin/ipvsadm -a -u $VIP:$PORT -r $RIP1:$PORT -g
/sbin/ipvsadm -a -u $VIP:$PORT -r $RIP2:$PORT -g
#Run Lvs
/sbin/ipvsadm
;;
stop)
echo "close LVS Directorserver"
/sbin/ipvsadm -C
/sbin/ifconfig eno16777736:1 down
;;
*)
echo "Usage: $0 {start|stop}"
exit 1
esac
[root@node93 ~]# chmod +x /mnt/data/lock/lvsmaster.sh
[root@node93 ~]# cd /mnt/data/lock/
[root@nodoe93 lock]# ./lvsmaster.sh start
start LVS of DirectorServer
SIOCADDRT: File exists
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.3.95:0 rr persistent 60
-> 192.168.3.93:0 Route 1 0 0
-> 192.168.3.94:0 Route 1 0 0
UDP 192.168.3.95:0 rr persistent 60
-> 192.168.3.93:0 Route 1 0 0
-> 192.168.3.94:0 Route 1 0 0
3、编写LVS realserver
编写shell脚本lvsrealserver.sh,并在所有集群节点上运行,这里master节点同时也是real server节点。其配置内容如下:[root@node93 lock]# vi lvsrealserver.sh
#!/bin/bash
VIP=192.168.3.95
BROADCAST=192.168.3.255 #vip's broadcast
. /etc/rc.d/init.d/functions
case "$1" in
start)
echo "reparing for Real Server"
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce
ifconfig lo:0 $VIP netmask 255.255.255.255 broadcast $BROADCAST up
/sbin/route add -host $VIP dev lo:0
;;
stop)
ifconfig lo:0 down
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "0" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/all/arp_announce
;;
*)
echo "Usage: lvs {start|stop}"
exit 1
esac
将脚本文件设置成执行文件,直接在提示符下调用。
[root@node93 lock]# chmod +x lvsrealserver.sh
[root@nodoe93 lock]# ./lvsrealserver.sh start
reparing for Real Server
[root@node94 lock]# ./lvsrealserver.sh start
reparing for Real Server
(四)实践结果
1、ctdb的高可用测试
(1)查看ctdb状态:[root@nodoe93 ~]# ctdb status



(3)在Linux下访问nfs共享,发现无论是3网段的公网还是2网段的私网都能够正常访问,如下图中所示;


(3)disable掉node93的ctdb服务、把node93关机、关闭网络等,使用# ctdb ip查看,发现192.168.3.93 IP已经飘到了node94上。再次在Windows下访问cifs共享,Linux下访问nfs共享,发现只有3网段的公网能够正常访问,而2网段的私网却不能正常访问了,说明在访问192.168.3.93虚拟IP的共享时,是把访问的IP切换到了192.168.3.94虚拟IP上的,如下图中所示;




2、LVS测试
(1)使用命令测试lvs是否配置成功[root@nodoe93 lock]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.3.95:0 rr persistent 60
-> 192.168.3.93:0 Route 1 0 0
-> 192.168.3.94:0 Route 1 0 0
UDP 192.168.3.95:0 rr persistent 60
-> 192.168.3.93:0 Route 1 0 0
-> 192.168.3.94:0 Route 1 0 0
[root@nodoe93 lock]# ipvsadm -l --stats
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Conns InPkts OutPkts InBytes OutBytes
-> RemoteAddress:Port
TCP 192.168.3.95:0 0 0 0 0 0
-> 192.168.3.93:0 0 0 0 0 0
-> 192.168.3.94:0 0 0 0 0 0
UDP 192.168.3.95:0 0 0 0 0 0
-> 192.168.3.93:0 0 0 0 0 0
-> 192.168.3.94:0 0 0 0 0 0
(2)访问Samba共享,简单测试负载是否均衡到不同集群节点上。
[root@node91 ~]# mount -t cifs //192.168.3.95/public /mnt/data/
Password for root@//192.168.3.95/public: ******
[root@node91 ~]# df -Th /mnt/data
Filesystem Type Size Used Avail Use% Mounted on
//192.168.3.95/public cifs 10G 33M 10G 1% /mnt/data
(3)访问nfs共享,简单测试负载是否均衡到不同集群节点上。

九、总结
整个集群NAS主要由集群文件系统、高可用NAS集群、LVS负载集群三个逻辑部分组成,如图5所示:

十、参考文档
1、刘爱贵. 基于开源软件构建高性能集群NAS系统
2、刘爱贵. 集群存储高可用方法
3、刘爱贵. 集群NAS技术架构
4、Etsuji Nakai.GlusterFS / CTDB Integration
5、吴凡. 集群NAS系统CLNASFS的关键技术研究
8、黄崇远. 分布式高可用CTDB方案
9、LVS
10、高性能的Linux集群
11、Michael Adam. Clustered NAS For Everyone ClusteringSamba With CTDB
12、Introduction to CTDBCluster














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









