









一、简介
相信大家都使用过like进行模糊匹配查询,在oracle中,instr()方法可以用来代替like进行模糊查询,大数据量的时候效率更高。本文将对instr()的基本使用方法进行详解以及通过示例讲解与like的效率对比。
二、使用说明
instr(sourceString,destString,start,appearPosition)
对应参数描述: instr('源字符串' , '目标字符串' ,'开始位置','第几次出现'),第一个字符下标为1,返回目标字符串在源字符串中的位置。后面两个参数可要可不要。
instr()与like比较
instr函数也有三种情况:
a. instr(字段,'关键字') > 0 相当于 字段like '%关键字%': 表示在字符串中包含‘关键字’
b. instr(字段,'关键字') = 1 相当于 字段like '关键字%' 表示以‘关键字’开头的字符串
c. instr(字段,'关键字') = 0 相当于 字段not like '%关键字%' 表示在字符串中不包含‘关键字’
下面,我们以一些示例讲解使用方法:
【a】从开头开始查找第一个‘h’出现的位置
--从开头开始查找第一个‘h’出现的位置
select instr('zhangsan', 'h') as idx from dual; --2查询结果:

【b】从开头开始查找‘an’在字符串中的位置
--从开头开始查找‘an’在字符串中的位置
select instr('zhangsan','an') idx from dual; --3查询结果:

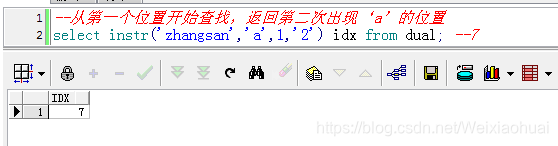
【c】从第一个位置开始查找,返回第二次出现‘a’的位置
--从第一个位置开始查找,返回第二次出现‘a’的位置
select instr('zhangsan','a',1,'2') idx from dual; --7查询结果:
【d】从倒数第一个位置开始,查找第一次出现‘a’的位置
--从倒数第一个位置开始,查找第一次出现‘a’的位置
select instr('zhangsan','a',-1,1) idx from dual; --7查询结果:

【e】从倒数第一个位置开始,返回第二次出现‘a’的位置
--从倒数第一个位置开始,返回第二次出现‘a’的位置
select instr('zhangsan','a',-1,2) idx from dual; --3查询结果:

三、instr()与like比较
instr函数也有三种情况:
a. instr(字段,'关键字') > 0 相当于 字段like '%关键字%': 表示在字符串中包含‘关键字’
b. instr(字段,'关键字') = 1 相当于 字段like '关键字%' 表示以‘关键字’开头的字符串
c. instr(字段,'关键字') = 0 相当于 字段not like '%关键字%' 表示在字符串中不包含‘关键字’
下面通过一个示例说明like 与 instr()的使用比较:
【a】使用like进行模糊查询
WITH temp1 AS ( SELECT 'zhangsan' AS NAME FROM DUAL ),
temp2 AS ( SELECT 'zhangsi' AS NAME FROM DUAL ),
temp3 AS ( SELECT 'xiaoming' AS NAME FROM DUAL ),
temp4 AS ( SELECT 'xiaohong' AS NAME FROM DUAL ),
temp5 AS ( SELECT 'zhaoliu' AS NAME FROM DUAL ) SELECT
*
FROM
( SELECT * FROM temp1
UNION all
select * FROM temp2
union all
select * FROM temp3
union all
select * FROM temp4
union ALL SELECT * FROM temp5 ) res
WHERE
res.NAME LIKE '%zhang%'查询字符串中包含‘zhang’的结果:

【b】使用instr()进行模糊查询
(1) 查询字符串中包含‘zhang’的结果:
WITH temp1 AS ( SELECT 'zhangsan' AS NAME FROM DUAL ),
temp2 AS ( SELECT 'zhangsi' AS NAME FROM DUAL ),
temp3 AS ( SELECT 'xiaoming' AS NAME FROM DUAL ),
temp4 AS ( SELECT 'xiaohong' AS NAME FROM DUAL ),
temp5 AS ( SELECT 'zhaoliu' AS NAME FROM DUAL ) SELECT
*
FROM
( SELECT * FROM temp1 UNION allselect * FROM temp2union allselect * FROM temp3union allselect * FROM temp4union ALL SELECT * FROM temp5 ) res
WHERE
instr( res.NAME, 'zhang' ) > 0;
(2) 查询字符串中不包含‘zhang’的结果: instr( name, 'zhang' ) = 0
WITH temp1 AS ( SELECT 'zhangsan' AS NAME FROM DUAL ),
temp2 AS ( SELECT 'zhangsi' AS NAME FROM DUAL ),
temp3 AS ( SELECT 'xiaoming' AS NAME FROM DUAL ),
temp4 AS ( SELECT 'xiaohong' AS NAME FROM DUAL ),
temp5 AS ( SELECT 'zhaoliu' AS NAME FROM DUAL ) SELECT
*
FROM
( SELECT * FROM temp1 UNION allselect * FROM temp2union allselect * FROM temp3union allselect * FROM temp4union ALL SELECT * FROM temp5 ) res
WHERE
instr( res.NAME, 'zhang' ) = 0;
(3) 查询以‘zhang’开头的字符串:instr( name, 'zhang' ) = 1
WITH temp1 AS ( SELECT 'zhangsan' AS NAME FROM DUAL ),
temp2 AS ( SELECT 'zhangsi' AS NAME FROM DUAL ),
temp3 AS ( SELECT 'sizhangsan' AS NAME FROM DUAL ),
temp4 AS ( SELECT 'xiaohong' AS NAME FROM DUAL ),
temp5 AS ( SELECT 'zhaoliu' AS NAME FROM DUAL ) SELECT
*
FROM
( SELECT * FROM temp1 UNION allselect * FROM temp2union allselect * FROM temp3union allselect * FROM temp4union ALL SELECT * FROM temp5 ) res
WHERE
instr( res.NAME, 'zhang' ) = 1;
(4)instr与like特殊用法: 或查询 instr('a, b', id)
select id, name from users where instr('a, b', id) > 0;
--等价于
select id, name from users where id = a or id = b;
--等价于
select id, name from users where id in (a, b);四、效率对比
【a】使用plsql创建一张十万条数据测试数据表,同时为需要进行模糊查询的列增加索引
--创建 10万条测试数据
CREATE TABLE test_instr_like AS
SELECT
rownum AS id,
'zhangsan' AS NAME
FROM
dualconnect BY LEVEL <= 100000;
--n ame列建立索引
CREATE INDEX idx_tb_name ON test_instr_like ( NAME );【b】使用like进行模糊查询
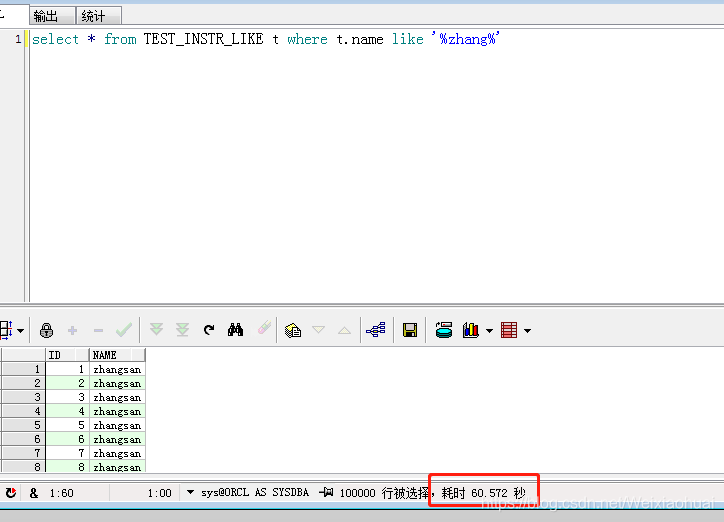
select *
from TEST_INSTR_LIKE t
where t.name like '%zhang%'
总耗时: 60秒
【c】使用instr进行模糊查询
select * from TEST_INSTR_LIKE t where instr(t.name, 'zhang') > 0;
总耗时:50秒

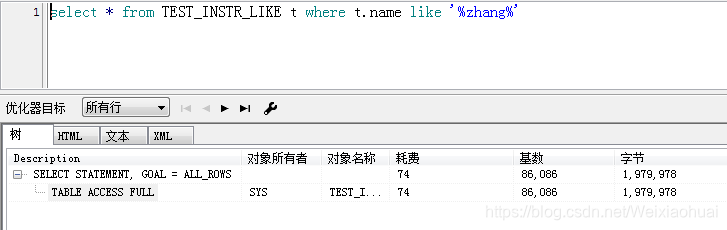
由图可见,instr查询的速度确实比like快一些,但是,看执行计划的话,instr却比like耗时一点。如下图:

五、总结
以上是对instr基本使用方法的讲解以及通过示例对比了like与instr的效率,在进行模糊查询的时候,能用instr的话就尽量用instr,毕竟数据量大的时候还是有一点优势的,本文是笔者对like以及instr的一些总结和见解,仅供大家学习参考,共同学习,共同进步!
---------------------
作者:人丑就该多读书呀
原文:https://blog.csdn.net/Weixiaohuai/article/details/83513957?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









