







HBase常用命令
1,查询数据状态(status)
hbase(main):017:0> status //hbase(main):017:0>是命令行
2,查看名字空间以及名字空间下的表(list_namespace 、 list_namespace_tables)
hbase(main):018:0> list_namespace
hbase(main):019:0> list_namespace_tables 'hbase' //列出hbase这个名字空间下的表
3,创建名字空间和删除名字空间(create_namespace、drop_namespace)
hbase(main):021:0> create_namespace 'zxz'
hbase(main):022:0> drop_namespace 'zxz'
4, 查看表信息(list)
hbase(main):022:0>list
5, 创建表(create)
hbase(main):022:0>create '名字空间名:表名','列族'
6, 删除表:(drop disable)
hbase(main):023:0>drop '名字空间:表名' //不指定名字空间使用默认空间
执行他会报错说你如果要删除向禁用,以免保持一致性
hbase(main):024:0>disable '表名' //禁用表
7, 释放表(enable) 只对禁用的表有用
hbase(main):025:0>enable ‘表名’
8, 删除列族(alter,disable)
hbase(main):026:0>disable ‘表名’
hbase(main):027:0>alter ‘表名’,{NAME=>'列族名',METHOD=>'delete'}
9,查询一个表是否存在(exits)
hbase(main):028:0>exits '表名'
10,判断表的状态(is_enabled)
hbase(main):029:0>is_enabled '表名' //如果是true则是未禁用false是禁用
11,插入记录(put)
hbase(main):030:0>put '表名','行键','列族:列','值'
12,获取一个行键的所有数据(get)
hbase(main):031:0>get '表名','行键'
13,获取一个行键,一个列族的所有数据(get)
hbase(main):032:0>get '表名','行键','列族'
14,获取一个列键,一个列族中一个列的所有数据(get)
hbase(main):033:0>get '表名','行键','列族:列'
15,更新一条记录(put)
hbase(main):034:0>put '表名','行键','列族:列','值' //更新其实和正常添加数据一样只不过表名,行键,列族,列要在表里有不然,和插入数据没有区别了,更新数据后,原来的数据会被覆盖,但可以利用时间戳获取到原来的值
16,通过时间戳来获取数据(get)(了解)
hbase(main):035:0>get '表名','行键',(column=>'列族:列','timestamp'=>时间戳的值) //这个很少用
17,全表扫描(scan)
hbase(main):036:0>scan '表名'
18,删除指定行键的字段(delete)
hbase(main):037:0>delete '表名','行键','列族:列'
19,删除整行(deleteall)
hbase(main):038:0>deleteall '表名','行键'
20,查询表中有多少行(count)
hbase(main):039:0>count '表名'
21,清空表(truncate)
hbase(main):040:0>truncate '表名'
22,查看表结构(desc)
hbase(main):041:0>desc '表名'
23,创建表添加版本(create)
版本数,跟列族相关,所有创建时必须指定列族,
versions //最大版本数
min_versions //默认0
TTL //time to live。存活时间,默认'forever' 永不过期,这个属性关系着版本数可以存放多长时间,如果超出指定的时间他会自动减少到最小版本数
hbase(main):>create '表名',{NAME=>'列族',VERSION=>最大版本数,MIN_VERSIONS=>最小版本数,TTL=设置版本存活时间以秒计算}
24,扫描某个列族的全部版本(scan)
hbase(main):>scan '表名',{RAW=>true,VERSION=要查询到那个版本数}
25,create时进行预切割
hbase(main):>create '表名','列族',SPLITS=>['切割区域',''切割区域 ,'切割区域'......]
他是以rowkey切割的所以加了我们的rowkey为 1,2,3,4,5,6,7,8,9,10就可以
SPLITS=>['3','6','9']
26,使用split切割表(分区表,他这个区是区域的意思)
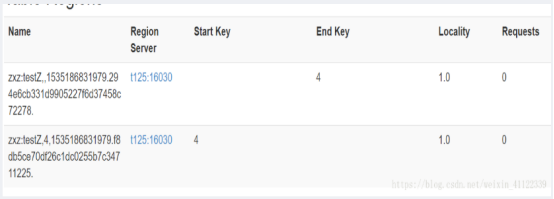
hbase(main):>split '表名','rowkey' //他以rowkey进行切割,你输入rowkey值他会标在分割出来第一个region结尾,到第 二个region的开始
如图:
27,合并表区域(merge_region)
hbase(main):>merge_region '被切割regionname的值','另一个regionname的值'
regionname就是在webui或者hbase名字空间的meta表可以看,下面演示的是webui上的上面那张图可以用一下:
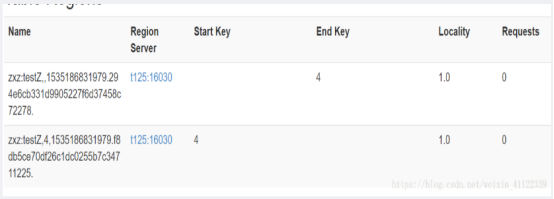
就是name这一列这里面两个点包裹住这一串哈希码294e--------72278,没有点哦
28,移动区域(move)
hbase(main):>move '表中的regionname','器群中的机器名,ip,机器的regionname'
第二个条件查看方式有很多:1,使用zookeeper查看,2,在hbase命令行查看,3,webui
命令的话看下面这个命令
29,查看zk信息(包括上面命令需要的内容)
hbase(main):>zk_dump
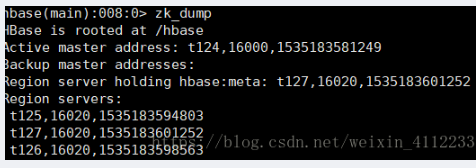
图片中的region servers 就是我们move命令需要的条件内容
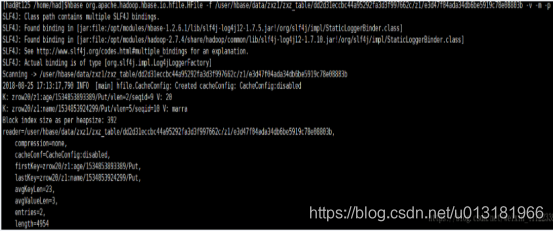
30,查看hdfs上存放的hbase的某个文件的详细详细
hbase(main):>
hbase org.apache.hadoop.hbase.io.hfile.HFile -f hdfs上hbase文件的绝对路径 -v -m -p
31,incr(cell值自动增长)
hbase(main):>incr 't4','row1','f1:name',10 //步长为10
hbase(main):>incr 't4','row1','f1:name',-1 //步长减一
hbase(main):>get_counter 't4','row1','f1:name' //获取cell的总数
32,取消分配类似move
hbase(main):>unassign 'reginname',true //把当前所在regionserver禁掉,给他分配其他的region
33,统计数据(count)
hbase(main):>count '表名'
34,使用压缩模式:
hbase(main):>create 't1',{NAME=>'f1',COMPRESSION=>'gz'}
//它还支持lzo和snappy等压缩格式














 2030
2030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









