







预训练模型(Pretrained model):一般情况下预训练模型都是大型模型,具备复杂的网络结构,众多的参数量,以及在足够大的数据集下进行训练而产生的模型.
在NLP领域,预训练模型往往是语言模型,因为语言模型的训练是无监督的,可以获得大规模语料,同时语言模型又是许多典型NLP任务的基础,如机器翻译,文本生成,阅读理解等,常见的预训练模型有BERT, GPT, roBERTa, transformer-XL等.

一、Electra概述
在 2019 年 11 月份,NLP 大神 Manning 联合谷歌做的 ELECTRA 一经发布,迅速火爆整个 NLP 圈,其中 ELECTRA-small 模型参数量仅为 BERT-base 模型的 1/10,性能却依然能与 BERT、RoBERTa 等模型相媲美,得益于 ELECTRA 模型的巧妙构思 LOSS,在 2020 年 3 月份 Google 对代码做了开源。
BERT 的预训练的过程中使用了 Masked Language Model (MLM),随机选择输入句子中 15% 的单词,然后其中的 80% 的单词用 [mask] 替换,10% 保持不变,10% 随机替换。然后 BERT 会对这 15% 的单词进行预测,还原回真实的单词。例如输入的句子是 “the artist sold the painting”,MLM 将其中的 painting 用 [mask] 替换,变成 “the artist sold the [mask]”,然后 BERT 要预测 [mask] 真实的单词是什么。
MLM 预训练任务存在一些缺点:
- 每一次训练只预测了 15% 的单词, 比较浪费计算力。
- [mask] 只在训练的时候出现,在真实预测的时候是没有的,这导致训练和推断过程的不一致。
ELECTRA 提出了一种新的预训练方法 Replaced Token Detection (RTD),训练过程类似 GAN,利用生成器将句子中的单词进行替换,然后判别器判断句子中哪些单词被替换过。

ELECTRA 比 BERT 和 RoBERTa 效果更好,并且只用了 RoBERTa 1/4 的计算量就达到了类似的效果。
1、Electra论文摘要
虽然诸如BERT之类的掩码语言建模(MLM)预训练方法在下游NLP任务上产生了出色的结果,但它们需要大量的计算才能有效。这些方法通过用[MASK]替换一些词来改变输入,然后训练模型以重建原始词。
作为替代方案,我们提出了一种更加样本有效的预训练任务,称为替换词检测。
我们的方法不是掩盖输入,而是通过使用从小的生成网络采样的词替换一些输入词来改变输入。然后,我们训练一个判别模型,该模型可以预测损坏的输入中的每个词是否被生成器样本替换,而不是训练一个预测损坏的词的原始身份的模型。
实验表明,这种新的预训练任务比MLM更有效,因为该模型从所有输入词中学习,而不仅仅是从被掩盖的小子集中学习。
结果显示,在相同的模型大小、数据和计算条件下,通过我们的方法学习的上下文表示大大优于通过BERT和XLNet等方法学习的上下文表示。
小模型的收益特别大,例如,在GLUE自然语言理解基准上,我们在一个GPU上训练了4天的模型优于GPT(使用30倍的计算能力训练)。
我们的方法在规模上也能很好地发挥作用,我们的 Electra 和 RoBERTa(当前最先进的预训练 Transformer)的性能相当,而使用的计算量不到它的1/4。
2、Electra论文简介
当前最先进的语言表示学习方法可以看作是学习降噪自动编码(Bert的MLM),这类仅选择未标记输入序列的一小部分(通常为15%),掩盖这些标记或注意这些标记,然后训练网络以恢复原始输入的标记。 这些方法可以学习双向表示,因此比语言模型预训练更有效,但是这些掩码语言模型(MLM)方法仅从每个样本15%的词中学习,计算成本非常大。
我们提出了一个新的预训练任务Replaced Token Detection,它的目标是学习区分输入的词。这个方法不采用mask,而是从一个建议分布中采样词来替换输入,这个过程解决了[mask]带来的预训练和fine-tune不一致的问题,然后我们训练一个判别器来预测每个词是原始词还是替换词。判别任务的一个好处是模型从输入的所有词中学习,而不是MLM中那样仅使用掩盖的词,因此计算更加有效。
我们的方法很容易让人想起GAN,但其实Electra并不是对抗学习,我们采用的是最大似然,目前GAN应用在文本领域还是有不少困难。
我们的方法称为 Electra(Efficiently Learning an Encoder that Classifies Token Replacements Accurately),与之前的工作一样,我们用它来训练Transformer的文本编码器,然后在下游任务上进行fine-tune。通过一系列的扩展,我们证明从所有输入序列中学习使得 Electra 比 BERT 训练的更快,并且当完全训练时在下游任务上取得的效果也更好。
我们训练了不同大小的ELECTRA模型并在GLUE上评价它们的效果,发现:在相同的模型大小、数据、计算量的情况下,ELECTRA显著优于MLM类的方法,例如BERT和XLNet,详细对比如下图所示:

此外,ELECTRA小模型仅需要在1块GPU训练4天即可得到,
这个ELECTRA小模型比BERT小模型在GLUE上高5个点,甚至比更大的GPT模型效果还要好。
此外,我们的方法在大规模情况下也取得了与当前最先进模型RoBERTa相当的效果,并且具有更少的参数,训练过程需要的计算不到它的1/4。
我们的方法证明,区分真实数据和有挑战的负样本的判别式任务是一种更加计算有效和参数有效的语言表示学习方法。
3、ELECTRA 的创新点
ELECTRA 的创新点在于:
- 提出了新的模型预训练的框架,采用Generator和Discriminator的结合方式,但又不同于GAN
- 将Masked Language Model的方式改为了replaced token detection
- 因为masked language model 能有效地学习到context的信息,所以能很好地学习embedding,所以使用了weight sharing的方式将Generator的embedding的信息共享给Discriminator
- dicriminator 预测了Generator输出的每个token是不是original的,从而高效地更新transformer的各个参数,使得模型的熟练速度加快
- 该模型采用了小的Generator以及Discriminator的方式共同训练,并且采用了两者loss相加,使得Discriminator的学习难度逐渐地提升,学习到更难的token(plausible tokens)
- 模型在fine-tuning 的时候,丢弃Generator,只使用discrinator
4、ELECTRA的主要作用
ELECTRA的论文指出,自己的模型效果能够达到state-of-the-art,但是在真正的GELU 榜单上,还是敌不过Roberta等模型。但是在小模型的表现上,我们可以发现ELECTRA的效果确实更加地好,所以ELECTRA的目前的作用主要:
- 可以利用这个框架,自己训练一个预训练模型,单个GPU就可以训练得到一个小的语言模型,然后在特定的领域可以得到更优的结果,然后再在这个领域下进行特定任务的finetuning。
- 使用小的ELECTRA模型,在不能使用GPU的场景,或者性能要求高的场景,可以得到好的结果
- ELECTRA的效果在多分类上不如Roberta,可能与预训练时采用的是二分类任务有关。

5、Electra优点
任务难度的提升
- 原始的MLM任务是随机进行mask,样本预测难度是不一样的,比如“夕小瑶的卖[MASK]屋”和“夕[MASK]瑶的卖萌屋”中,卖萌是比较常见的词语,而夕小瑶则是命名实体,没见过的话更难预测出来。生成器相当于对输入进行了筛选,使判别器的任务更难,从而学习到更好的表示
效率的提升
- 运算上,判别器进行2分类而不是V分类,复杂度降低。参数利用上,判别器不需要对完整的数据分布进行建模,作者在实验中也发现越小的模型提升越明显,可见参数被更完整地训练了
Token自身信息的利用
- 做MLM的任务时,都是mask掉token自身,利用上下文对自己进行预测。而ELECTRA是同时利用自身和上下文预测,和NLU任务的Finetune阶段也比较一致
收敛速度加快
6、Electra缺点
显存占用增多
- 之前都是训一个BERT,现在相当于两个,即使共享参数去训练,由于Adam等优化器的关系,需要保存的中间结果数量也是翻倍的。
多任务学习超参数调整
- ELECTRA的loss由生成器和判别器分别构成,原文中给判别器loss的权重是50,因为二分类的loss会比V分类低很多。但这个数值太过绝对,最好是变成可学习的参数动态调整。
7、Electra性能提升原因
ELECTRA 的改进主要两点:解决mask的mismatch的问题,以及计算100%的token都计算loss。哪个占了最大的优势?:
- ELECTRA 15%:让判别器只计算15% token上的损失;
- Replace MLM:两个生成器。一个生成器替换被mask的token,另一个生成器用替换后的输入继续进行15%的MLM训练。这样可以消除这种pretrain-finetune之间的diff;
- All-Tokens MLM:同Replace MLM,只不过BERT的目标函数变为预测所有的token,为了防止信息泄露加入了copy机制,以D的概率直接拷贝输入,以1-D的概率预测新token,相当于ELECTRA和BERT的结合

可以发现,对效果提升最重要的其实是 all-tokens 的 Loss计算,这种方式相比只计算15%的 token,大大增加了模型收敛速度。
8、Electra、BERT区别(两个方面)
Masked(replaced) Tokens的选择
- token的选择BERT是随机的,这意味着什么呢?比如句子“我想吃苹果”,BERT可以mask为“我想吃苹[MASK]”,这样一来实际上去学它就很简单,如果mask为“我[MASK]吃苹果”,那么去学这个“想”就相对困难了。换句话说,BERT的mask可能会有很多简单的token,去学这些token就算是简单的bilstm都可以做的。
- 这样一来,一个简单的想法就是,不随机mask,去专门选那些对模型来说学习困难的token。怎么做呢?这就是ELECTRA非常牛逼的地方了,train一个简单的MLM,当做模型对训练难度的先验,简单的自动过滤(在这里就是sample出来的和原句子一样),复杂的后面再学。还是举“我想吃苹果”这个例子。比如我这里还是mask为“我想吃苹[MASK]”,MLM这个生成器可以以很高的概率sample到“果”,但是对“我[MASK]想吃苹果”,MLM就很难说大概率采样到“想”了,也可能是“不”、“真”等等……总的来说,MLM的作用就是为自动选择masked tokens提供了一种非常有效的方法!
Training Objective
- 既然MLM选择了一些token,那么该怎么去学呢?当然这个地方也可以像BERT那样,如果MLM采样的保持不变,就相当于原BERT中不mask;如果变了,就mask,然后再用BERT的方法去train。
- 然而ELECTRA另辟蹊径,用一个二分类去判断每个token是否已经被换过了。这就把一个DAE(或者LM)任务转换为了一个分类任务(或者序列标注)。这有两个好处:
- 每个token都能contribute to some extent,这是和MLM联系起来的(这也是ELECTRA精妙的地方了)。如果MLM牛逼,那么discriminate的难度就很大,从而就可以看作是hard example;
- 缓解distribution的问题。如果我们像BERT那样去预测真正的token,也即通过一个classifier C ~ ∈ R d × ∣ V ∣ \tilde{C}\in\mathbb{R}^{d\times |V|} C~∈Rd×∣V∣ 的话,那么它相比二分类器 C ∈ R d × 2 C\in\mathbb{R}^{d\times 2} C∈Rd×2 而言就需要更多的计算量,而且还要suffer 由于 ∣ V ∣ |V| ∣V∣ 较大导致的分布问题。
以上两点总结起来就是:

8、Electra历史意义
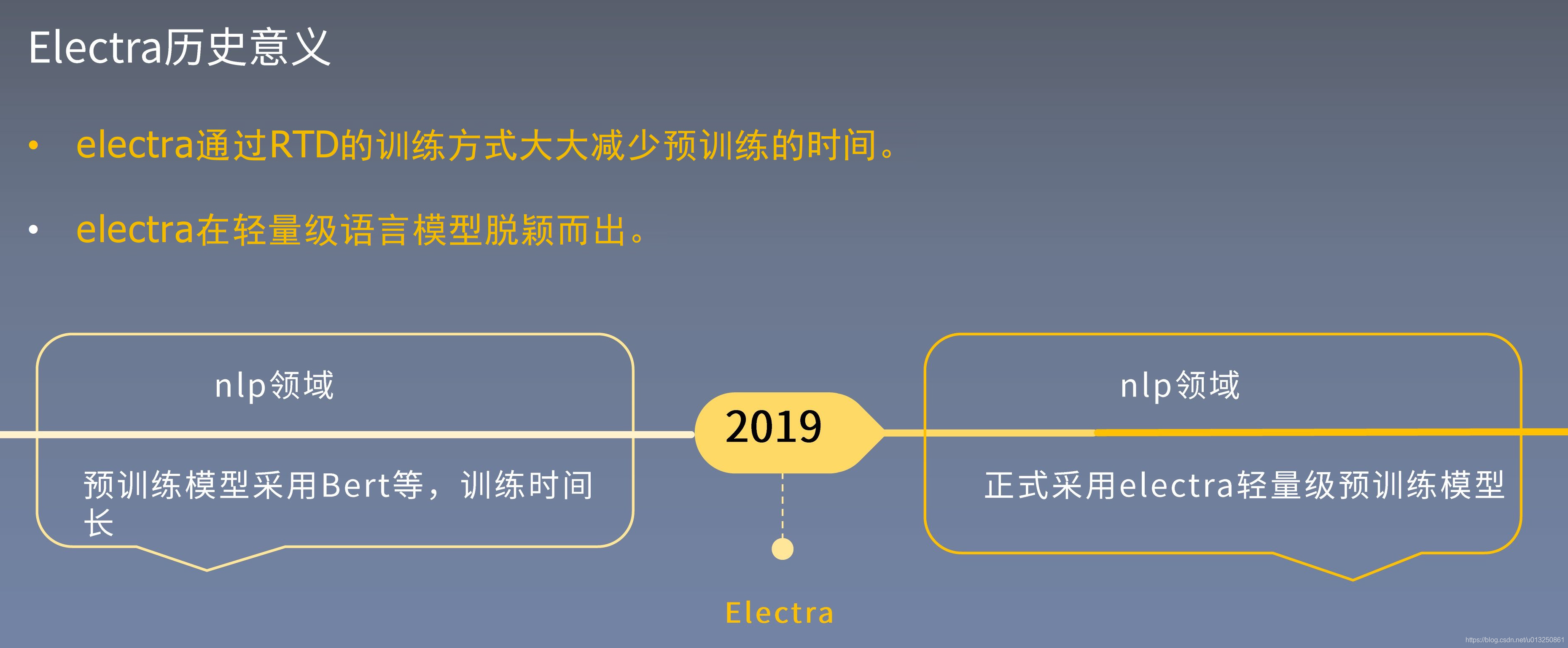
- MLM的预训练方法类似于Bert破坏输入通过用mask标志替换,并且训练模型去重塑最原始的输 入。当它们在下游任务中产生好的结果是需要大量的数据。
- 我们提出一个更有效的预训练任务,方法是从小型生成器里采样的合理的替代品替换一些token 来破坏输入。然后训练一个判别模型,该模型可以预测损坏的输入中的每个token是否被生成器样本
取代。 - 我们的模型取和Bert相同的数据量、模型参数,所取得结果要优于Bert系列模型,并且训练的时间大大的减少。
二、GAN回顾
生成式对抗网络包含两个模块:生 成 模 型 (Generative M o d e l)和判 别 模 型 (Discriminative Model) o 通过两者的互相博弈学习能产生出相当好的输出。
- 生成网络目的:使自己造样本的能力尽可能强,强到判别网络无法判断是真样本还是假样本。
- 判别网络目的:尽可能增强自己的判别能力,能区分到底样本是属于真实样本集还是假样本集。
GAN 的核心思想源于博弈论的纳什均衡。
- 设定参与游戏的双方分别为一个生成器(Generator)和一个判别器(Discriminator),
- 生成器捕捉真实数据样本的潜在分布, 并生成新的数据样本;
- 判别器是一个二分类器, 判别输入是真实数据还是生成的样本。
- 为了取得游戏胜利, 这两个游戏参与者需要不断优化, 各自提高自己的生成能力和判别能力,
- 这个学习优化过程就是寻找二者之间的一个纳什均衡。
- GAN是一种二人零和博弈思想(two-player game),博弈双方的利益之和是一个常数。

- GAN的计算流程与结构如上图所示。
- 其中的生成器和判别器可以用任意可微分的函数,这里我们用可微分函数 D D D 和 G G G 来分别表示判别器和生成器,
- 【判别模型】 D D D 的输入为真实数据 x \textbf{x} x
- 【生成模型】 G G G 的输入为随机变量 z \textbf{z} z。
- G ( z ) G(\textbf{z}) G(z) 为由 G G G 生成的尽量服从真实数据分布 p d a t a p_{data} pdata 的样本。
- 如果判别器的输入来自真实数据 x \textbf{x} x,则标注为1;如果输入样本为 G ( z ) G(\textbf{z}) G(z), 标注为0。
- 这里 D D D 的目标是实现对数据来源的二分类判别: 真(来源于真实数据 x \textbf{x} x 的分布)或者伪(来源于生成器的伪数据 G ( z ) G(\textbf{z}) G(z))。
- 而 G G G 的目标是使自己生成的伪数据 G ( z ) G(\textbf{z}) G(z) 在 D D D 上的表现 D ( G ( z ) ) D(G(\textbf{z})) D(G(z)) 和真实数据 x \textbf{x} x 在 D D D 上的表现 D ( x ) D(\textbf{x}) D(x) 一致。
三、Electra模型结构
本文提出的方法包括两个神经网络:一个生成器G和一个判别器D,两者都采用形如transformer的编码网络来获取输入序列x的向量表示h(x)。
- 生成器的目标是训练成掩码语言模型,即给定输入序列x,首先按照一定的比例(通常15%)将输入中的词替换成[MASK]得到,然后通过网络得到向量表示hG(x),接着采用softmax层来为输入序列中掩盖的位置预测一个词,训练的目标函数为最大化掩盖词的似然。
- 判别器的目标是判断输入序列每个位置的词是否被生成器替换过,如果与原始输入序列对应位置的词不相同就认为替换过。
ELECTRA 模型(BASE 版本)本质是换一种方法来训练 BERT 模型的参数;
BERT 模型主要是利用 MLM 的思想来训练参数,直接把需要预测的词给挖掉了,挖了 15%的比例。由于每次训练是一段话中 15%的 token,导致模型收敛更新较慢,需要的语料也比较庞大。同时为了兼顾处理阅读理解这样的任务,模型加入了 NSP,是个二分类任务,判断上下两句是不是互为上下句;
ELECTRA的全称是Efficiently Learning an Encoder that Classifies Token Replacements Accurately,ELECTRA 模型主要借助于图像领域 GAN 的思想,利用生成器和判别器思想,以1/4的算力就达到了RoBERTa的效果。模型如下图所示;ELECTRA 的预训练可以分为生成器、判别器两部分:


Generator和Discriminator可以看作两个BERT,生成器的任务是MLM,判别器的任务是Replaced Token Detection,判断哪个字被替换过。
但上述结构有个问题,输入句子经过生成器,输出改写过的句子,因为句子的字词是离散的,所以梯度在这里就断了,判别器的梯度无法传给生成器,于是生成器的训练目标还是MLM(作者在后文也验证了这种方法更好),判别器的目标是序列标注(判断每个token是真是假),两者同时训练,但判别器的梯度不会传给生成器,目标函数如下:

因为判别器的任务相对来说容易些,RTD loss相对MLM loss会很小,因此加上一个系数,作者训练时使用了50。
另外要注意的一点是,在优化判别器时计算了所有token上的loss,而以往计算BERT的MLM loss时会忽略没被mask的token。作者在后来的实验中也验证了在所有token上进行loss计算会提升效率和效果。
- 生成器 (Generator) 部分仍然是 MLM(一个小的MLM),结构与 BERT 类似,利用这个模型对挖掉的 15%的词进行预测,并将其进行替换,若替换的词不是原词,则打上被替换的标签,语句的其他词则打上没有替换的标签,
- 判别器 (Discriminator) 部分是训练一个判别模型对所有位置的词进行替换识别,此时预测模型转换成了一个二分类模型。
- 判断输入句子中的每个词是否被替换,即使用Replaced Token Detection (RTD)预训练任务,取代了BERT原始的Masked Language Model (MLM)。
- 需要注意的是这里并没有使用Next Sentence Prediction (NSP)任务。
- 这个转换可以带来效率的提升,对所有位置的词进行预测,收敛速度会快的多,损失函数是利用生成器部分的损失和判别器的损失函数以一个比例数(官方代码是 50)相加。
Generator和Discriminator可以看作两个BERT,生成器的任务是MLM,判别器的任务是Replaced Token Detection,判断哪个字被替换过。只是两者的size不同。
在预训练阶段结束之后,只使用Discriminator作为下游任务精调的基模型。
换句话说,作者们把CV领域的GAN运用到了自然语言处理。
值得注意的是,尽管与GAN的训练目标相似,但仍存在一些关键差异:
- 首先,如果生成器碰巧生成了正确的token,则该token被视为“真实”而不是“伪造”;所以模型能够适度改善下游任务的结果。
- 更重要的是,生成器使用最大似然来训练,而不是通过对抗性训练来欺骗判别器。
1、生成器 (Generator)
ELECTRA 中如果使用简单的随机替换,会让判别器 (Discriminator) 很容易判断单词是否被替换过,例如将句子 “the chef cooked the meal” 中的 meal 随机替换成 air,则判别器很容易判断出 “the chef cooked the air” 中的 air 被替换过 。
因此 ELECTRA 使用了 MLM 对生成器进行训练,也是随机 [mask] 部分单词,然后用生成器预测的结果替换该单词,例如 Generator 将 cooked 替换成 [mask],然后预测的时候将该位置预测成 ate。这种 Generator 预测错误的单词具有更强的迷惑性。
生成器预测的时候使用了 softmax,如下公式,公式中 h G h_G hG 表示编码后的向量, e ( x ) e(x) e(x) 表示单词 x x x 的 embedding, t t t 表示位置。

Generator 就是一个小的 masked language model(通常是 1/4 的Discriminator的size),该模块的具体作用是他采用了经典的bert的MLM方式:
- 首先随机选取15%的tokens,替代为[MASK]token,(取消了bert的80%[MASK],10%unchange, 10% random replaced 的操作,具体原因也是因为没必要,因为我们finetuning使用的Discriminator)
- 使用Generator 去训练模型,使得模型预测masked token,得到corrupted tokens
- Generator 的目标函数和bert一样,都是希望被masked的能够被还原成原本的original tokens
如上图, the 和 cooked这2个 token 被随机选为被masked,然后Generator 预测得到corrupted tokens,变成了the和ate
2、判别器 (Discriminator)
判别器 (Discriminator) 接收到生成器 (Generator) 生成的句子,就会分别预测每一个单词(token)是否被替换过。注意:如果Generator生成的token和原始token一致,那么这个token仍然是original的,所以,对于每个token,Discriminator都会进行一个二分类,最后获得loss。
这一个过程会对句子的所有单词都进行预测,因此效率比 BERT 更高。
最后训练得到的判别器将用于下游的任务。Discriminator 的预测公式如下:

3、损失函数
生成器和判别器的损失函数如下:

最终的损失函数为生成器和判别器的加权和:
ELECTRA 总体的损失函数由生成器的损失函数
L
M
L
M
L_{MLM}
LMLM 和判别器的损失函数
L
D
i
s
c
L_{Disc}
LDisc 组成。
- 生成器的训练损失函数仍然是 MLM 损失函数,主要原因是生成器将单词进行替换,而单词是离散的,导致判别器到生成器的梯度中断了;
- 两者同时训练,但判别器的梯度不会传给生成器;
- 因此 ELECTRA 的损失函数由这两个部分相加组成;
- 在 Pre-training之后,我们只使用 Discriminator进行Fine-tuning.
4、Electra与GAN的区别

GAN 的训练是训练一个 Generator 产生结果,去骗过Discriminator。所以Generator的产生结果,在Discriminator的都会认为是假的。
- 在我们的训练过程中,如果Generator 产生的token和original token一样,Discriminator应该认为这个token是real的,那么我们认为是没有替换过;
- Generator的训练目标是最大似然,和Discriminator 并没有交互,这点跟GAN的对抗训练非常不同;
- Generator 不是用来fool Discriminator;
- Generator的输入是真实文本,而GAN的输入是随机噪声;
- Discriminator的梯度不会传到Generator,而GAN的梯度是会从Discriminator传到Generator的;
预训练结束后,我们采用 Discriminator 的来 fine-tune 下游任务。
四、Electra实验
Electra预训练数据集
- BookCorpus数据集:大型文本语料,适用于句子encoder/decoder 的无监督训练,量级3.3Billion tokens。
- Gigaword 数据集:摘要生成数据集。
- ClueWeb 2012-B数据集:新闻数据集,带标注。
- Common Crawl:爬虫数据集。
1、参数共享
如果生成器和判别器采用相同的size,那么它们编码器的权重参数都可以共享。
但是我们发现:采用更小的生成器,并将生成器和判别器的embeddings共享更加有效。
ELECTRA 尝试将生成器和判别器的参数进行共享,使用相同大小的生成器和判别器。
- 实验中不共享任何参数得到的 GLUE 分数为 83.6,
- 只共享单词 embedding 层后的 GLUE 分数为 84.3,
- 共享所有参数的 GLUE 分数为 84.4。
考虑到所有参数共享时提升很少,但是还要求生成器和判别器的size相同,不够灵活,我们选择仅仅共享embeddings。
作者认为生成器对embedding有更好的学习能力,因为在计算MLM时,softmax是建立在所有vocab上的,之后反向传播时会更新所有embedding,而判别器只会更新输入的token embedding。因此作者使用了只共享单词 embedding 的方式。
2、生成器大小
从权重共享的实验中看到,生成器和判别器只需要共享embedding的权重就足矣了,那这样的话是否可以缩小生成器的尺寸进行训练效率提升呢?
如果生成器和判别器采用相同的size,那么总体的训练时间差不多是MLM的两倍,为了提高效率,我们尝试更小的生成器。我们在保持其他参数不变的情况下,减少生成器的layer size进行实验,同时我们还采用简单的unigram生成器作为对比,实验结果如下左图。我们发现,判别器的size越大越好(256 -> 512 -> 768),生成器的size介于判别器size的1/4-1/2时效果最佳。原因大概是太强的生成器对判别器太难了吧。
作者在保持原有hidden size的设置下减少了层数,得到了下图所示的关系图:

- 横坐标为生成器的大小;
- 纵坐标为 GLUE 分数;
可以看到在生成器过大会影响模型的性能,生成器的大小在判别器的1/4到1/2之间效果是最好的。作者认为原因是过强的生成器会增大判别器的难度(判别器:生成器你小一点吧,我太难了)。
3、训练算法
ELECTRA 训练方式在上一节已经说了,主要优化生成器和判别的损失函数。
实际上除了MLM loss,作者也尝试了另外两种训练策略:
-
Two-Stage:交替训练生成器和判别器,例如固定判别器,训练生成器 n 次,然后固定生成器,训练判别器 n 次。这两个步骤交替进行。
-
Adversarial Contrastive Estimation:尝试 GAN 中对抗训练的思想,ELECTRA因为上述一些问题无法使用GAN,但也可以以一种对抗学习的思想来训练。作者将生成器的目标函数由最小化MLM loss换成了最大化判别器在被替换token上的RTD loss。但还有一个问题,就是新的生成器loss无法用梯度下降更新生成器,于是作者用强化学习Policy Gradient的思想,将被替换token的交叉熵作为生成器的reward,然后进行梯度下降。强化方法优化下来生成器在MLM任务上可以达到54%的准确率,而之前MLE优化下可以达到65%。

-
可见Electra的“隔离式”的最大似然的联合训练策略效果还是最好的;
-
Two-Stage 的方法虽然弱一些,作者猜测是生成器太强了导致判别任务难度增大,但最终效果也比BERT本身要强;
-
另外对抗训练的方法优于BERT,但是不如最大似然的联合训练;
4、计算量对比【Electra、BERT、RoBERTa】

上图的横坐标是浮点数计算总量 FLOPs (floating point operations),用于表示计算量,而纵坐标是 GLUE 分数。可以看到
- ELECTRA 在计算量只有 RoBERTa 1/4 的时候就可以达到相近的性能。
- ELECTRA模型能够在训练步长更少的前提下得到了比其他预训练模型更好的效果。
- 同样,在模型大小、数据和计算相同的情况下,ELECTRA的性能明显优于基于MLM的方法,如BERT和XLNet。
所以,ELECTRA 与现有的生成式的语言表示学习方法相比,ELECTRA 具有更高的计算效率和更少的参数(ELECTRA-small的参数量仅为BERT-base的 1/10)。
5、Electra-small模型
基于BERT-base的超参数,我们减少序列长度(512 -> 128),减少batch size(256 -> 128),减少隐层大小(768 -> 256),采用更小的embedding(768 -> 128),在相同算力的情况下进行模型效果对比,如下图。
我们发现:Electra-Small 模型的效果比其他更多参数的模型更好,Electra-Base 模型的效果甚至超越了BERT大模型。

import torch
from transformers import ElectraModel, ElectraTokenizer
# 一、加载 electra 的分词器
tokenizer = ElectraTokenizer.from_pretrained(r'D:\Pretrained_Model\electra-small-discriminator')
# 二、加载 electra 模型,这个路径文件夹下有 electra_config.json配置文件和model.bin模型权重文件
model = ElectraModel.from_pretrained(r'D:\Pretrained_Model\electra-small-discriminator', output_hidden_states=True, output_attentions=True)
# 三、使用tokenizer进行数值映射,将字符串型转为数值型张量
input_text = "i have been through a large number of pc security products over the years ."
indexed_tokens = torch.tensor(tokenizer.encode(input_text)).unsqueeze(0) # 使用tokenizer进行数值映射
print("tokenizer映射后的结果:indexed_tokens = ", indexed_tokens) # tokenizer映射后的结果:indexed_tokens = tensor([[ 101, 1045, 2031, 2042, 2083, 1037, 2312, 2193, 1997, 7473, 3036, 3688, 2058, 1996, 2086, 1012, 102]]) 【 101和102是起止符, 中间的每个数字对应"i have been through a large number of pc security products over the years ."的每个单词和标点】
# 四、将序列化后得数据喂给model,生成bert的输出
electra_outputs = model(indexed_tokens)
electra_outputs_list = list(electra_outputs)
print("\nlen(electra_outputs_list) = {0}".format(len(electra_outputs_list)))
print("electra_outputs_list = {0}".format(electra_outputs_list))
last_hidden_state, hidden_states, attentions = electra_outputs[0], electra_outputs[1], electra_outputs[2]
print("\n\nlast_hidden_state.shape = {0}----last_hidden_state = electra_outputs[0] = \n{1}".format(last_hidden_state.shape, last_hidden_state))
print("\nhidden_states[0].shape = {0}----hidden_states = electra_outputs[2] = \n{1}".format(hidden_states[0].shape, hidden_states))
print("\nlen(attentions) = {0}----attentions[0].shape = {1}".format(len(attentions), attentions[0].shape))
打印结果:
tokenizer映射后的结果:indexed_tokens = tensor([[ 101, 1045, 2031, 2042, 2083, 1037, 2312, 2193, 1997, 7473, 3036, 3688,
2058, 1996, 2086, 1012, 102]])
len(electra_outputs_list) = 3
electra_outputs_list = ['last_hidden_state', 'hidden_states', 'attentions']
last_hidden_state.shape = torch.Size([1, 17, 256])----last_hidden_state = electra_outputs[0] =
tensor([[[-0.0284, 0.6080, -0.3162, ..., 0.8347, -1.1226, -0.6537],
[ 0.1939, -0.5991, -0.8255, ..., 0.3106, 0.6084, -0.1566],
[-0.0481, -0.7381, 0.0554, ..., -0.2334, -1.4381, 0.2947],
...,
[-0.5901, 0.6478, 0.6018, ..., -0.1908, 1.2614, -0.4087],
[-0.7617, -0.8874, -0.3097, ..., 0.2891, -0.1729, -0.3266],
[-0.0286, 0.6098, -0.3161, ..., 0.8349, -1.1219, -0.6530]]],
grad_fn=<NativeLayerNormBackward>)
hidden_states[0].shape = torch.Size([1, 17, 256])----hidden_states = electra_outputs[2] =
(tensor([[[ 0.1217, 0.1541, 0.2605, ..., -0.0515, -0.1326, -0.0366],
[ 0.6159, -0.0814, -0.1319, ..., 0.6205, -0.1866, 0.0121],
[ 0.4126, 0.3767, -0.4125, ..., 1.0027, -0.1816, 0.3072],
...,
[-0.5381, -0.0290, 0.1776, ..., 0.0815, 0.5889, 0.0717],
[-0.0688, 0.1766, 0.4342, ..., 0.0503, 0.1171, -0.0015],
[ 0.0080, 0.6113, 0.3191, ..., 0.5889, 0.2047, 0.3052]]],
grad_fn=<AddBackward0>), tensor([[[ 0.3168, 0.2045, 0.3695, ..., -0.1726, -0.1545, -0.3430],
[ 0.9707, -0.2793, -1.0023, ..., 0.6352, -0.5707, -0.1766],
[ 1.0222, 0.1809, -1.2632, ..., 1.1246, 0.1426, 0.4113],
...,
[-1.2661, -0.2059, -0.5735, ..., 0.0215, 0.9425, 0.2242],
[ 0.0025, 0.3833, 0.5878, ..., -0.0050, 0.2649, -0.0628],
[ 0.0311, 0.3351, -0.0231, ..., 0.7173, 0.0520, -0.1782]]],
grad_fn=<NativeLayerNormBackward>), tensor([[[ 0.2931, 0.1086, 0.4231, ..., -0.0504, 0.2137, -0.3964],
[ 0.5593, -0.4543, -1.5679, ..., 0.2239, -0.6175, -0.1135],
[ 0.0953, -0.0509, -1.4045, ..., 0.0940, 0.1589, 1.0378],
...,
[-1.8564, -0.2108, -0.3596, ..., 0.0630, 0.9074, 0.4079],
[-0.8878, 1.0281, 1.0793, ..., -0.0071, 0.3717, -0.3227],
[ 0.2541, 0.1353, 0.4524, ..., 0.1256, 0.2160, -0.2446]]],
grad_fn=<NativeLayerNormBackward>), tensor([[[ 0.2980, 0.1475, 0.4508, ..., 0.1189, 0.3058, -0.2112],
[ 0.0306, -0.5523, -2.0825, ..., 0.4473, -0.5009, -0.3166],
[ 0.4892, -0.0531, -1.8796, ..., -0.0554, -0.1338, 0.9172],
...,
[-2.1612, 0.1214, -0.3524, ..., 0.0285, 0.9109, -0.2621],
[-1.1541, 0.7751, 1.0130, ..., 0.0452, 0.8786, -0.4638],
[ 0.2844, 0.1637, 0.4775, ..., 0.1786, 0.3281, -0.1439]]],
grad_fn=<NativeLayerNormBackward>), tensor([[[ 0.5522, 0.4879, 0.4719, ..., 0.2343, 0.1676, 0.2375],
[-0.6529, -0.7846, -2.5446, ..., 0.9600, -0.2510, -0.2770],
[ 0.0203, -0.2216, -2.3382, ..., -0.1268, -0.6156, 0.6264],
...,
[-3.2003, 0.1052, -0.1772, ..., 0.0106, 1.2046, -0.0409],
[-1.4811, 0.6161, 0.6195, ..., 0.1904, 0.6988, 0.2856],
[ 0.4861, 0.4603, 0.5425, ..., 0.2068, 0.1848, 0.2631]]],
grad_fn=<NativeLayerNormBackward>), tensor([[[ 0.1747, 0.2768, 0.2823, ..., 0.0846, 0.0694, 0.1084],
[-0.3514, -0.6264, -2.3063, ..., 0.6237, -0.2571, -0.1669],
[-0.0361, -0.6725, -2.0145, ..., 0.1235, -0.9772, 0.4720],
...,
[-2.8363, -0.0554, -0.3821, ..., -0.6344, 1.4551, -0.6457],
[-1.1512, 0.4944, 0.3136, ..., -0.1580, 0.3512, 0.3365],
[ 0.1445, 0.2764, 0.3139, ..., 0.0756, 0.0738, 0.0881]]],
grad_fn=<NativeLayerNormBackward>), tensor([[[ 0.1832, 0.2514, 0.2519, ..., 0.0700, 0.0130, -0.0851],
[-0.0613, -0.4081, -2.1287, ..., 0.5592, -0.1747, -0.5212],
[ 0.0563, -0.0679, -1.7534, ..., 0.2392, -1.5811, -0.3424],
...,
[-2.3719, -0.1254, -0.2160, ..., -0.8909, 1.7298, -1.3734],
[-0.7856, 0.3802, 0.3391, ..., 0.0310, 0.7380, 0.1082],
[ 0.1543, 0.2517, 0.2867, ..., 0.0658, 0.0238, -0.1029]]],
grad_fn=<NativeLayerNormBackward>), tensor([[[ 0.2674, 0.2181, 0.1497, ..., 0.2178, -0.0557, 0.0508],
[ 0.2488, -0.4835, -2.2022, ..., 0.5767, -0.1676, -0.6759],
[ 0.0888, -0.7360, -1.4286, ..., 0.8834, -2.1632, -0.2286],
...,
[-1.5140, -0.4921, -0.2646, ..., 0.6174, 1.6203, -1.4020],
[-0.2092, 0.6156, -0.1144, ..., 0.1969, 0.3564, 0.0373],
[ 0.2520, 0.2195, 0.1656, ..., 0.2151, -0.0537, 0.0519]]],
grad_fn=<NativeLayerNormBackward>), tensor([[[ 0.1552, 0.1778, 0.1830, ..., 0.3474, -0.0476, 0.2841],
[ 0.0066, -0.4555, -2.1064, ..., 1.1454, -0.0022, -0.5271],
[-0.2642, -0.3778, -1.1165, ..., 0.7250, -1.7303, -0.7821],
...,
[-1.8436, -0.8521, -0.0307, ..., 1.1140, 1.6022, -0.9188],
[-0.3023, 0.1880, 0.2279, ..., 0.2450, 0.2042, 0.4530],
[ 0.1426, 0.1747, 0.1955, ..., 0.3504, -0.0437, 0.2863]]],
grad_fn=<NativeLayerNormBackward>), tensor([[[ 0.4141, 0.0934, 0.5100, ..., 0.3883, 0.0821, 0.2232],
[ 0.5547, -0.5087, -2.2518, ..., 1.3454, 0.6750, -0.2165],
[ 0.7640, -0.3922, -0.2254, ..., 0.8264, -1.8400, -0.6662],
...,
[-1.8125, -1.0534, 0.1865, ..., 1.0400, 2.1046, -1.5668],
[ 0.0491, 0.2340, 0.5510, ..., 0.1808, 0.2895, 0.1396],
[ 0.4022, 0.0871, 0.5160, ..., 0.3908, 0.0799, 0.2271]]],
grad_fn=<NativeLayerNormBackward>), tensor([[[ 0.0583, -0.0108, 0.1823, ..., 0.4587, -0.1592, 0.1159],
[ 0.1803, -0.7322, -1.7027, ..., 0.7322, 0.2937, -0.2824],
[ 0.5499, -0.4834, -0.3928, ..., 0.4018, -1.8514, 0.0181],
...,
[-0.7759, -0.8445, 0.3104, ..., -0.2674, 1.3699, -0.5807],
[-0.2337, -0.0620, 0.6698, ..., 0.4967, -0.2132, 0.0656],
[ 0.0554, -0.0104, 0.1826, ..., 0.4599, -0.1589, 0.1161]]],
grad_fn=<NativeLayerNormBackward>), tensor([[[ 2.6505e-01, 1.3650e-01, -4.1608e-02, ..., 4.4625e-01,
-1.4649e-01, 2.0617e-01],
[ 1.1774e-01, -8.9302e-01, -2.0036e+00, ..., 8.3905e-01,
3.7385e-01, -5.7158e-01],
[ 6.7349e-01, -1.1910e+00, -2.2275e-01, ..., 1.9958e-01,
-2.2192e+00, 3.5418e-02],
...,
[-6.2819e-01, 1.0023e-01, 5.6160e-01, ..., -1.8172e-01,
1.5018e+00, -4.7533e-01],
[ 2.4413e-01, -1.2029e-01, 7.3009e-01, ..., 8.2602e-01,
4.0095e-04, -1.0599e-02],
[ 2.6374e-01, 1.3726e-01, -4.1540e-02, ..., 4.4620e-01,
-1.4529e-01, 2.0718e-01]]], grad_fn=<NativeLayerNormBackward>), tensor([[[-0.0284, 0.6080, -0.3162, ..., 0.8347, -1.1226, -0.6537],
[ 0.1939, -0.5991, -0.8255, ..., 0.3106, 0.6084, -0.1566],
[-0.0481, -0.7381, 0.0554, ..., -0.2334, -1.4381, 0.2947],
...,
[-0.5901, 0.6478, 0.6018, ..., -0.1908, 1.2614, -0.4087],
[-0.7617, -0.8874, -0.3097, ..., 0.2891, -0.1729, -0.3266],
[-0.0286, 0.6098, -0.3161, ..., 0.8349, -1.1219, -0.6530]]],
grad_fn=<NativeLayerNormBackward>))
len(attentions) = 12----attentions[0].shape = torch.Size([1, 4, 17, 17])
Process finished with exit code 0
6、Electra-Large 模型
我们的 Electra-Large 模型采用BERT大模型相同的size,实验结果如下图,我们发现:ELECTRA达到了当前最先进模型RoBERTa的效果,但是训练的计算量不到它的1/4,简直是厉害!我们相信ELECTRA训练更久会有更好的结果。

7、效率分析
为了更好地理解ELECTRA效果提升的原因在哪里,作者对比了一系列预训练方法:
- ELECTRA 15%:判别器在计算损失时仅考虑那些被掩盖的词(15%),除此之外都与标准的ELECTRA相同;
- Replace MLM:不同于MLM中用[MASK]替换掩盖的词,它用一个生成器模型预测的词来替换掩盖的词,其他的都与MLM保持一致,这是为了分析解决[MASK]在预训练和fine-tune过程不一致问题的收益有多大。
- All-Token MLM:与Replace MLM一样,采用生成器模型预测的词来替换掩盖的词,并且,该模型预测所有输入对应的输出,而不仅仅是掩盖的词。我们发现采用一个显式的拷贝机制,对每个词输出一个拷贝概率D,最终预测概率为拷贝概率D乘以输入,再加上 (1-D) 乘以MLM的softmax输出。这个模型结合了BERT和ELECTRA。
实验结果如下表所示,我们发现:
- ELECTRA 15%的效果相比ELECTRA差很多,说明ELECTRA对输入的所有词计算损失这一点收益非常大;
- Replace MLM效果略好于BERT,说明BERT采用[MASK]替换掩盖词会略微降低模型效果;
- All-Token MLM的几乎快弥补了BERT和ELECTRA之间的gap,是最接近ELECTRA效果的模型。
总的来说,ELECTRA的提升一大部分来自于从所有词中学习,一小部分来自于解决[MASK]在预训练和fine-tune过程的不一致。
我们进一步对比了BERT和ELECTRA在不同模型大小的效果,如下图所示。我们发现:
- ELECTRA模型越小,相比BERT的提升就越明显(下图左边和中间);
- 模型收敛后ELECTRA效果明显优于BERT(下图右图)。

五、总结
本文提出的ELECTRA在取得当前最先进模型RoBerta相当效果的同时,计算量仅不到原来的1/4,非常有效。
有效的原因一大部分来自于从所有词中学习,一小部分来自于解决[MASK]在预训练和fine-tune过程的不一致。
个人觉得,NLP预训练模型目前已经发展到了爆发期,新模型出来的节奏越来越快,非常期待更多的工作出来,对于我辈NLPer,这是一个最美好的时代,一定要跟紧节奏。
参考资料:
More Efficient NLP Model Pre-training with ELECTRA
ELECTRA - 比BERT更快更好的预训练模型
ELECTRA模型精讲
ELECTRA 详解
超越 BERT 模型的 ELECTRA 代码解读
ELECTRA:比 BERT 更好的生成判别模型
ELECTRA中文预训练模型开源,仅1/10参数量,性能依旧媲美BERT
ELECTRA: NLP预训练模型
180G!中文ELECTRA预训练模型再升级
如何评价NLP算法ELECTRA的表现?














 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









