




前几章已经讲解了kafka的基本知识,我们已经能较好的用kafka来完成基本的开发任务,接下来了解一下内部的一些细节,便于知道相关的原理。本章主要讲kafka日志存储相关的知识。
1、文件目录布局
回顾之前所学的知识: Kafka 中的消息是以主题为基本单位进行归类的,各个主题在逻辑上相互独立。每个主题又可以分为一个或多个分区,分区的数量可以在主题创建的时候指定,也可以在之后修改 。 每条消息在发送的时候会根据分区规则被迫加到指定的分区中,分区中的每条消息都会被分配一个唯一的序列号,也就是通常所说的偏移量 ( offset )。
如果分区规则设置得合理,那么所有的消息可以均匀地分布到不同的分区中,这样就可以实现水平扩展。不考虑多副本的情况, 一个分区对应一个日志( Log)。为了防止 Log 过大,Kafka 又引入了日志分段( LogSegment )的概念, 将 Log 切分为多个 LogSegment,相当于一个巨型文件被平均分配为多个相对较小的文件,这样也便于消息的维护和清理。事实上, Log 和LogSegment也不是纯粹物理意义上的概念, Log 在物理上只以文件夹的形式存储,而每个LogSegment 对应于磁盘上的一个日志文件和两个索引文件,以及可能的其他文件(比如以“ .txnindex ”为后缀的事务索引文件〉 。
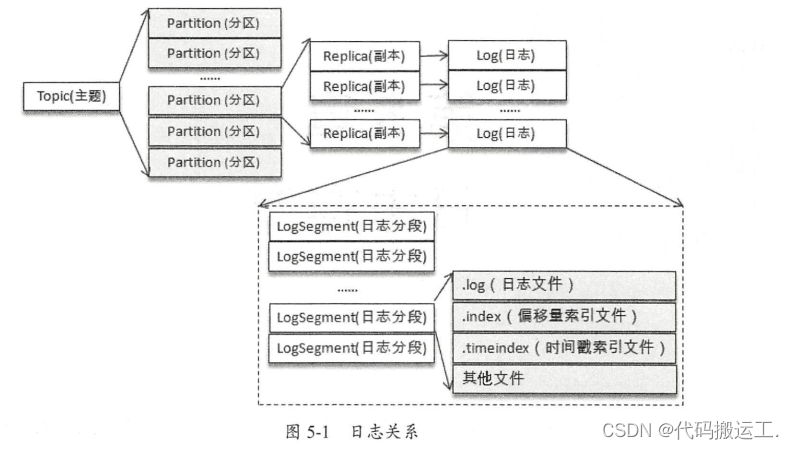
向 Log 中追加消息时是顺序写入的,只有最后一个 LogSegment 才能执行写入操作,在此之前所有的 LogSegment 都不能写入数据。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2446
2446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









