







文章目录
最近在做hdfs小文件合并的项目,涉及了一些文件格式的读写,比如avro、orc、parquet等。期间阅读了一些资料,因此打算写篇文章做个记录。
这篇文章不会介绍如何对这些格式的文件进行读写,只会介绍一下它们各自的特点以及底层存储的编码格式。
一、SequenceFile

- 相比于text格式的文件,SequenceFile可以存储key-value格式的消息,方便mapreduce引擎处理数据
- 支持record级别的压缩和block级别的压缩
- 文件是分块的,因此是可分割的。支持mapreduce的split输入
使用sequencefile还可以将多个小文件合并到一个大文件中,通过key-value的形式组织起来,此时该sequencefile可以看做是一个小文件容器。
二、Avro
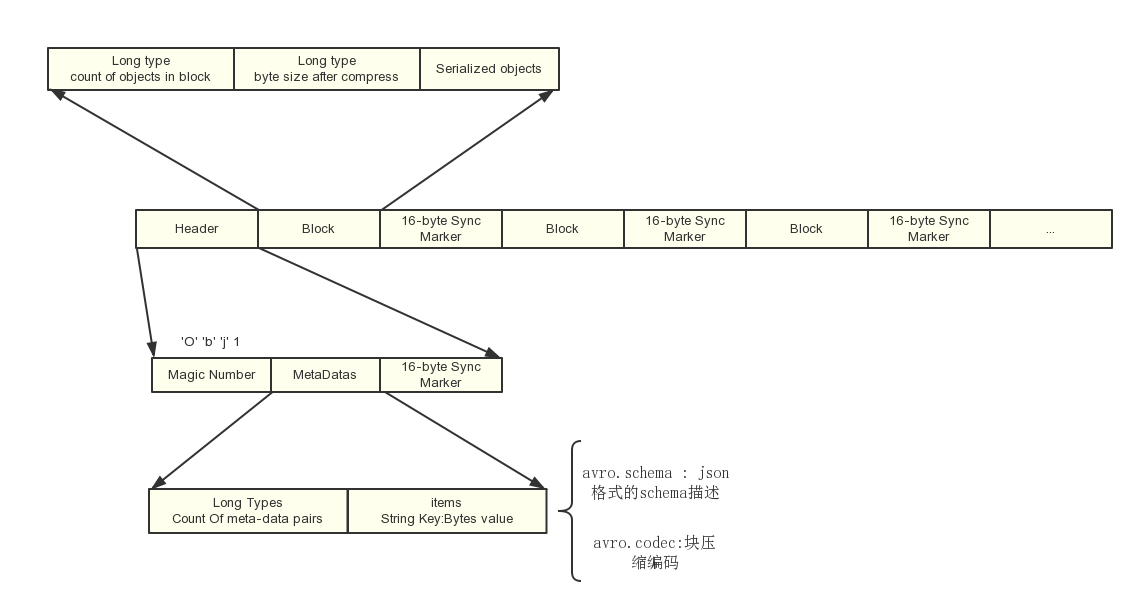
- 相比SequenceFile,avro支持更丰富的数据结构
- 文件是分块的,因此是可分割的。支持mapreduce的split输入
- 目前SequenceFile只有java实现,因此没办法通过其他的语言来读写SequenceFile文件,所以avro的一个优势就是多种语言实现
- avro的schema是存储在文件中的,因为拿到avro文件就可以直接进行读写。并且avro的schema是可以动态增删改的,保证向前兼容和向后兼容
三、parquet
Parquet是一个基于列式存储的文件格式,它将数据按列划分进行存储。Parquet官网上的文件格式介绍图:
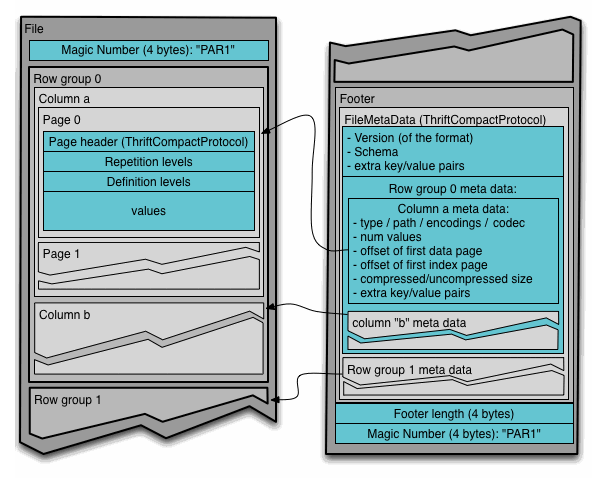
我们可以看出,parquet由几个部分构成:
- Magic Number
- 若干个 Row Group
- Footer 信息,即一些元数据
- Footer length,固定4个bytes,指出元数据的长度
- Magic Number
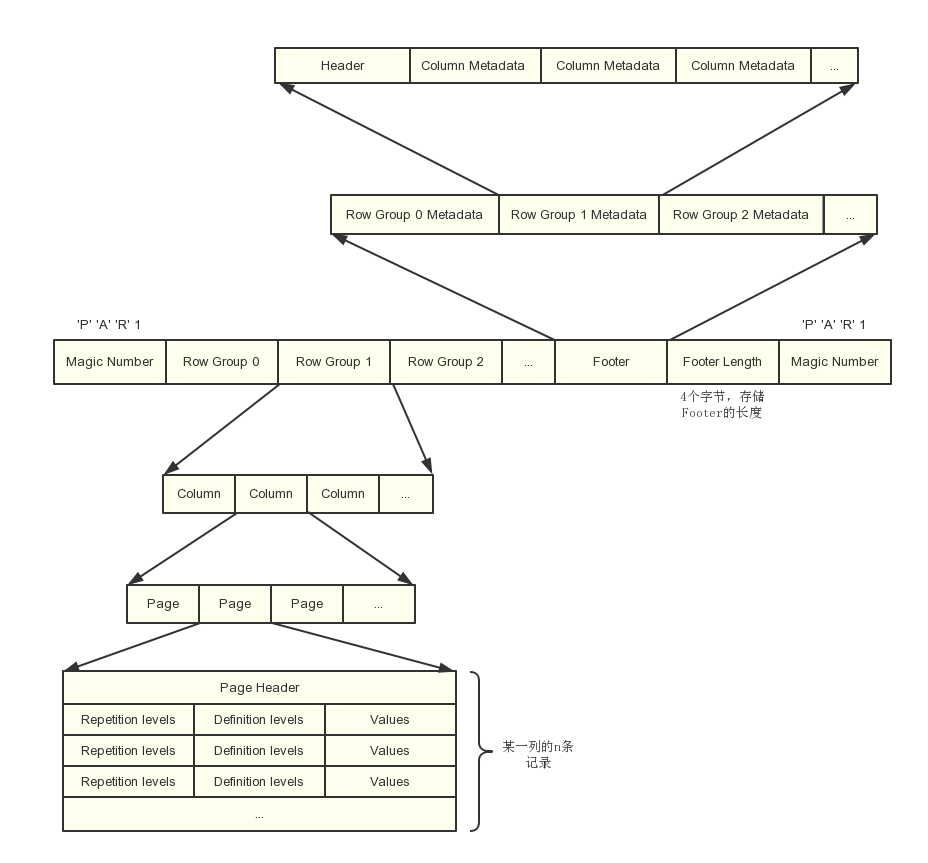
- Row Group 可以理解为一个个block,这个特性让parquet是可分割的,因此可以被mapreduce split来处理
- Row Group,还是page,都有具体的统计信息,根据这些统计信息可以做很多优化
- 每个 Row Group由一个个 Column chunk组成,也就是一个个列。Column chunk又细分成一个个page,每个page下就是该列的数据集合。列下面再细分page主要是为了添加索引,page容量设置的小一些可以增加索引的速度,但是设置太小也会导致过多的索引和统计数据,不仅占用空间,还会降低扫描索引的时间。
- parquet可以支持嵌套的数据结构,它使用了Dremel的 Striping/Assembly 算法来实现对嵌套型数据结构的打散和重构
四、Orc
Orc也是一个列式存储格式,产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。
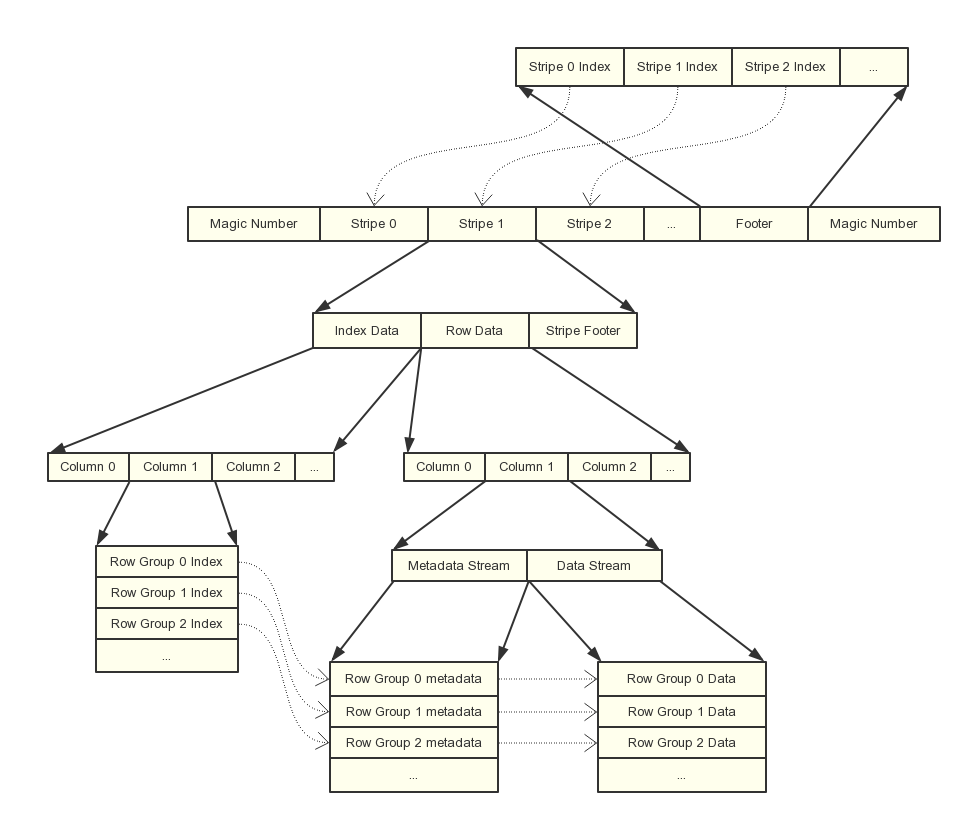
- 和Parquet的设计类似,也是将行分成多个组,然后组内按列存储,之后再对列进行分割。orc 的 Stripe 对应parquet的 Row Group,row Group 对应的是 parquet的 page
- ORC文件是自描述的,它的元数据使用Protocol Buffers序列化
- 除了基本类型以外,还支持更复杂的数据结构,如LIST、STRUCT、MAP和UNION类型。
五、同为列式存储, orc和parquet的区别
列式存储的优化点
目前列式存储是大数据领域基本的优化项,无论是存储还是查询,列式存储能做的优化都很多,看完上面对orc和parquet的文件结构介绍后,我们列式存储的优化点做一个总结:
在压缩方面:
- 由于每一列的数据类型都是一样的,因此可以针对每一列的数据类型使用更高效的压缩算法。比如存储时间戳时,我们可以以时间戳偏移大小来存储,减少存储容量
在查询方面:
- 在查询时只要扫描需要查询的列数据,不用进行全表扫描。
- 由于Column chunk、page都记录了一些统计信息,就可以很方便的根据column的条件直接过滤一些row group、column chunk、或者page不扫描。举个例子,比如已知Row Group的age字段的最小值是10,那么要查询age < 10的数据时就没必要扫描该group了
orc和parquet的一些区别和对比
- 由于设计理念类似,他们的文件格式有很多互通的地方。但是parquet的索引和元数据全部放在footer块,而orc则是分散在各个stripe中。目前也不能说哪种设计更好,只能看实际场景了
- 列编码的实现算法不同
- 选择的压缩算法不同
就网上找到的一些数据来看,Orc的压缩比会比Parquet的高一些,至于查询性能,两个应该不会差距太大。本人之前做过一个测试,在多数场景,hive on mr下,orc的查询性能会更好一些。换成hive on spark后,parquet的性能更好一些
六、一些总结
本文介绍的4种大数据存储格式,2个是行式存储,2个是列式存储,但我们可以看到一个共同点:它们都是支持分割的。这是大数据文件结构体系中一个非常重要的特点,因为可分割使一个文件可以被多个节点并发处理,提高数据的处理速度。
另外,当前大数据的主要趋势应该是使用列式存储,目前我们公司已经逐步推进列式存储的使用,本人也在hive上做过一些测试,在多个查询场景下,无论是orc还是parquet的查询速度都完爆text格式的,差不多有4-8倍的性能提升。另外,orc和parquet的压缩比都能达到10比1的程度。因此,无论从节约资源和查询性能考虑,在大多数情况下,选择orc或者parquet作为文件存储格式是更好的选择。另外,spark sql的默认读写格式也是parquet。
当然,并不是说列式存储已经一统天下了,大多时候我们还是要根据自己的使用场景来决定使用哪种存储格式。
查询资料附录
Sequencefile
https://blog.csdn.net/en_joker/article/details/79648861
https://stackoverflow.com/questions/11778681/advantages-of-sequence-file-over-hdfs-textfile
Avro和Sequencefile区别
parquet
https://www.cnblogs.com/ITtangtang/p/7681019.html
Orc
https://www.cnblogs.com/ITtangtang/p/7677912.html
https://www.cnblogs.com/cxzdy/p/5910760.html
Orc和parquet的一些对比














 1404
1404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









