







无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。人工智能教程
强化学习是一类算法,是让计算机从什么都不懂,脑袋里一点想法都没有,通过不断地尝试,从错误中学习,最后找到规律,学习到达到目标的方法。这就是一个完整的强化学习过程。
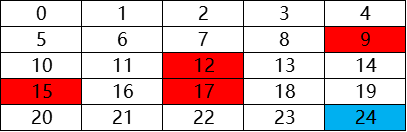
如为了实现自走的路径,并尽量避免障碍,设计一个路径。
如图所示,当机器人在图中的任意网格中时,怎样让它明白周围环境,最终到达目标位置。
Q-learning的想法
奖赏机制
在一个陌生的环境中,机器人首先的方向是随机选择的,当它从起点开始出发时,选择了各种各样的方法,完成路径。但是在机器人碰到红色方块后,给予惩罚,则经过多次后,机器人会避开惩罚位置。当机器人碰到蓝色方块时,给予奖赏,经过多次后,机器人倾向于跑向蓝色方块的位置。
具体公式
完成奖赏和惩罚的过程表达,就是用值表示吧。
首先建立的表是空表的,就是说,如下这样的表是空的,所有值都为0:
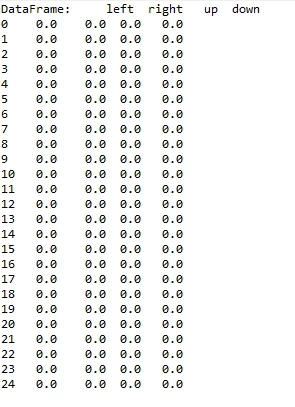
在每次行动后,根据奖惩情况,更新该表,完成学习过程。在实现过程中,将奖惩情况也编制成一张表。表格式如上图类似。
Q-table:
left right up down
0 0.000000 29.131876 0.000000 29.131876
1 27.218688 31.245833 0.000000 31.257640
2 29.131876 33.558380 0.000000 33.611442
3 30.892266 21.891451 0.000000 36.224813
4 23.744314 0.000000 0.000000 26.811900
5 0.000000 31.257640 27.218688 31.257640
6 29.131876 33.619599 29.131876 33.619600
7 31.257640 36.244000 30.919118 25.244000
8 33.618194 28.148718 33.038027 39.160000
9 35.168930 0.000000 18.353572 42.399996
10 5.375851 33.619600 29.131876 22.619600
11 31.257640 25.244000 31.257640 36.244000
12 33.619600 39.160000 33.618893 28.160000
13 25.244000 42.399998 36.243967 42.400000
14 39.159509 0.000000 28.143890 46.000000
15 0.000000 36.244000 31.257640 36.244000
16 22.619600 28.160000 33.619600 39.160000
17 36.244000 42.400000 25.244000 42.400000
18 28.160000 45.999999 39.160000 46.000000
19 42.399834 0.000000 40.733374 50.000000
20 0.000000 39.160000 22.619600 0.000000
21 36.244000 42.400000 36.244000 0.000000
22 39.160000 46.000000 37.160000 0.000000
23 42.400000 50.000000 42.400000 0.000000
24 0.000000 0.000000 0.000000 0.000000
而奖惩更新公式为:
贝尔曼方程:
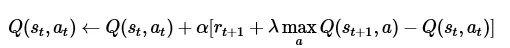
其中的 表示当前的Q表,就是上图25行4列的表单。 表示学习率, 表示下一次行为会得到的奖惩情况, 表示一个贪婪系数,在这里的公式中,就是说,如果它的数值比较大,则更倾向于对远方的未来奖赏。
实现代码:
import numpy as np
import pandas as pd
import time
N_STATES = 25 # the length of the 2 dimensional world
ACTIONS = ['left', 'right','up','down'] # available actions
EPSILON = 0.3 # greedy police
ALPHA = 0.8 # learning rate
GAMMA = 0.9 # discount factor
MAX_EPISODES = 100 # maximum episodes
FRESH_TIME = 0.00001 # fresh time for one move
# 创建Q表
def build_q_table(n_states, actions):
table = pd.DataFrame(
np.zeros((n_states, len(actions))), # q_table initial values
columns=actions, # actions's name
)
return table
# 行为选择
def choose_action(state, q_table):
state_actions = q_table.iloc[state, :]
if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()): # act non-greedy or state-action have no value
if state==0:
action_name=np.random.choice(['right','down'])
elif state>0 and state<4:
action_name=np.random.choice(['right','down','left'])
elif state==4:
action_name=np.random.choice(['left','down'])
elif state==5 or state==15 or state==10 :
action_name=np.random.choice(['right','up','down'])
elif state==9 or state==14 or state==19 :
action_name=np.random.choice(['left','up','down'])
elif state==20:
action_name=np.random.choice(['right','up'])
elif state>20 and state<24:
action_name=np.random.choice(['right','up','left'])
elif state==24:
action_name=np.random.choice(['left','up'])
else:
action_name=np.random.choice(ACTIONS)
else: # act greedy
action_name = state_actions.idxmax() # replace argmax to idxmax as argmax means a different function in newer version of pandas
return action_name
# 奖赏表达
def get_init_feedback_table(S,a):
tab=np.ones((25,4))
tab[8][1]=-10
tab[4][3]=-10
tab[14][2]=-10
tab[11][1]=-10
tab[13][0]=-10
tab[7][3]=-10
tab[17][2]=-10
tab[16][0]=-10
tab[20][2]=-10
tab[10][3]=-10
tab[18][0]=-10
tab[16][1]=-10
tab[22][2]=-1
tab[12][3]=-10
tab[23][1]=50
tab[19][3]=50
print(tab)
return tab[S,a]
# 获取奖惩
def get_env_feedback(S, A):
action={'left':0,'right':1,'up':2,'down':3}
R=get_init_feedback_table(S,action[A])
if (S==19 and action[A]==3) or (S==23 and action[A]==1):
S = 'terminal'
return S,R
if action[A]==0:
S-=1
elif action[A]==1:
S+=1
elif action[A]==2:
S-=5
else:
S+=5
return S, R
def rl():
# main part of RL loop
q_table = build_q_table(N_STATES, ACTIONS)
# print(q_table)
for episode in range(MAX_EPISODES):
S = 0
is_terminated = False
while not is_terminated:
A = choose_action(S, q_table)
S_, R = get_env_feedback(S, A) # take action & get next state and reward
if S_ != 'terminal':
q_target = R + GAMMA * q_table.iloc[S_, :].max() # next state is not terminal
else:
# print(1)
q_target = R # next state is terminal
is_terminated = True # terminate this episode
q_table.loc[S, A] += ALPHA * (q_target - q_table.loc[S, A]) # update
S = S_ # move to next state
return q_table
if __name__ == "__main__":
q_table = rl()
print('\r\nQ-table:\n')
print(q_table)















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











