







关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,python 里面也有一个包去使用Tesseract-OCR。
这个包 叫pytesseract 。
安装pytesseract
pip install pytesseract
除此之外还需要安装图像处理的包PIL
pip install pillow
然后要安装一个Tesseract-OCR软件。这个软件是由Google维护的开源的OCR软件。再在Windows下配置一下环境变量。
下载地址:
链接:https://pan.baidu.com/s/16XOFmKImOMbqlKSnDh6Y6w 密码:uls8
下载好之后安装需要勾选相应的中文简体,繁体数据包,来识别中文哦。
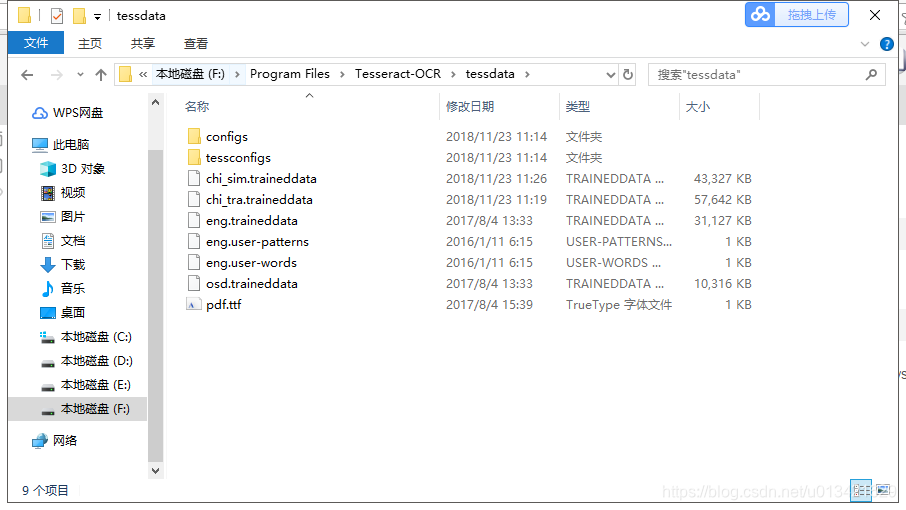
F:\Program Files\Tesseract-OCR\tessdata
这个目录的chi_sim 就是中文简体,chi_tra就是繁体了。chi_sim 要对应版本,如果你不是从安装那儿下载的话。
然后修改 pytesseract安装包的地方的一个脚本:
E:\laidefa\Lib\site-packages\pytesseract 目录下
Tesseract-OCR引擎指向你安装的地方,这样才能跑起来。
tesseract_cmd = 'F:/Program Files/Tesseract-OCR/tesseract.exe'
安装好了环境,下面就可以开始中文识别啦。
先来一波简单的数字识别:

识别下面数字试试:
全部识别正确。
换做文本试试:


效果也不错哦。
#-*-coding:utf-8-*-
from PIL import Image,ImageEnhance
import pytesseract
import time
def pic_to_word(filepath,filename,resize_num,b):
"""
:param filepath: 文件路径
:param filename:图片名
:param resize_num:缩放倍数
:param b:对比度
:return:返回图片识别文字
"""
try:
time1 = time.time()
im = Image.open(str(filepath)+str(filename))
# 图像放大
im = im.resize((im.width * int(resize_num), im.height * int(resize_num)))
# 图像二值化
imgry = im.convert('L')
# 对比度增强
sharpness = ImageEnhance.Contrast(imgry)
sharp_img = sharpness.enhance(b)
content = pytesseract.image_to_string(sharp_img, lang='chi_sim')
time2 = time.time()
print('本次图片识别总共耗时%s s' % (time2 - time1))
except Exception as e:
print("{0}".format(str(e)))
return content
if __name__ == '__main__':
filepath="F:/img_spam/test/"
filename="4.png"
resize_num = 2
b = 2.0
content=pic_to_word(filepath,filename,resize_num,b)
print(content)
函数代码模块:
import pytesseract
import requests
from PIL import Image
from PIL import ImageFilter
from StringIO import StringIO
def process_image(url):
image = get_image(url)
image.filter(ImageFilter.SHARPEN)
return pytesseract.image_to_string(image)
def get_image(url):
return Image.open(StringIO(requests.get(url).content))















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











