







背景技术:
并行的业务需求, 需要多套开发、 测试环境。
业界有两种主流模式
1、 维护多套完整、 独立的开发、 测试环境, 每套环境使用独占的资源、 以及固定的分支, 需求分支合并到相应的环境进行开发、 测试, 逐级推进, 直至上线。
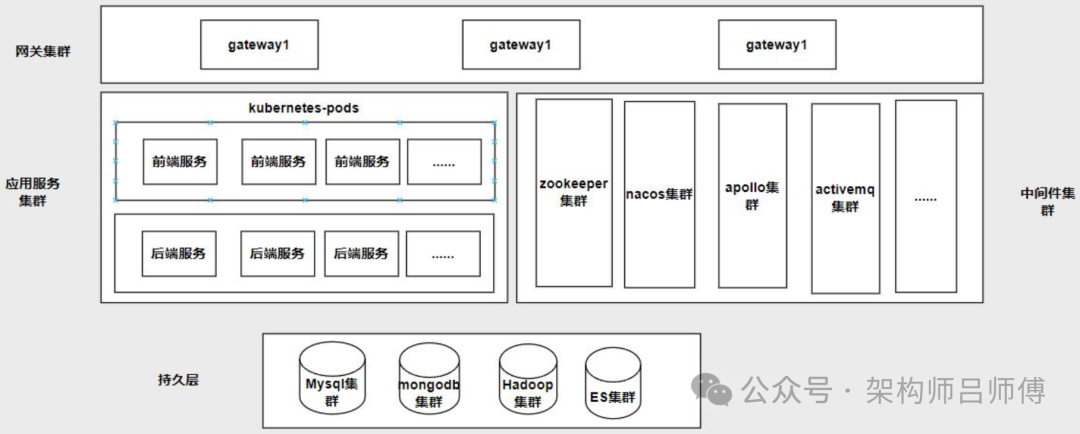

其缺点也比较明显:
如图 1 简洁的微服务架构下, 微服务数量众多, 架构依赖复杂。搭建一套完整的测试环境成本是非常高的, 初始要投入一至两周的时间搭建环境, 既占用较多服务器资源, 也需要持续投入人力维护。而且还长期存在着其他方面的问题, 如分支合并经常冲突、 多套环境的配置经常不同步、 专属环境总是不够、 各固定分支代码差异随时间越来越大、 环境极其不稳定等等
2、 基于全链路染色的服务调用路由方案
为了解决方案 1 的问题, 一些公司提出了环境复用的方案, 如阿里的云效。
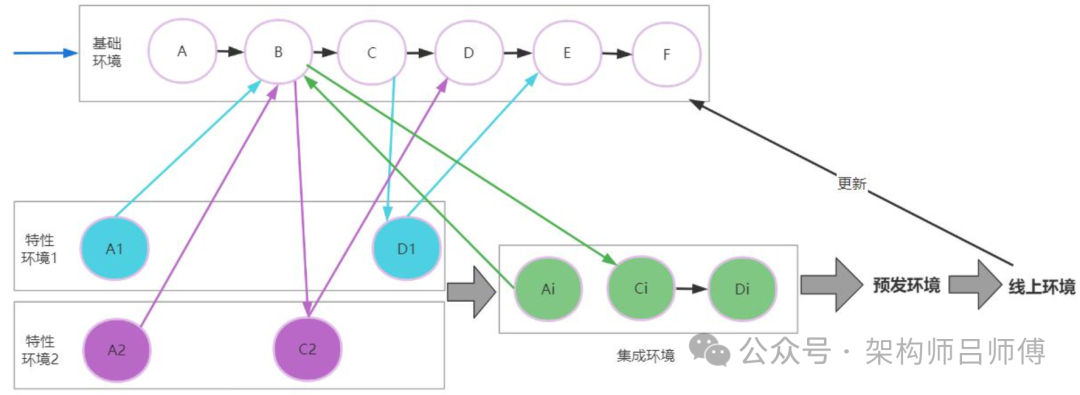
如上图所示, 搭建一套完整的基础环境, 覆盖所有的微服务、 中间件等, 本地开发、 特性环境、 测试环境、 集成环境都依赖这一套基础环境, 但按需部署有变更的微服务。每套环境都具有自己的环境标识, 通过给调用链路“染色” ,虚拟出完整的特性环境。
现有技术的缺陷和不足
方案 2 较好地做到了环境的复用等一系列问题, 但仅支持基础环境的复用, 还有一些需求是有依赖关系的。 如需求 A 上线后, 需求 B 才能上线。 但等 A 上线后再开发 B 需求, 时间上已经不允许了, 因此必须并行开发才能赶上进度。
同时,本地开发的服务也应该能方便的调试,但又不应该影响到现在的环境。
因此需要一种支持多级复用的环境路由方案。
技术解决的痛点
1:公用资源, 无需按环境和需求进行独立建立资源, 即复用资源
2:为需求子需求的层层依赖提供了解决方案
技术实现过程
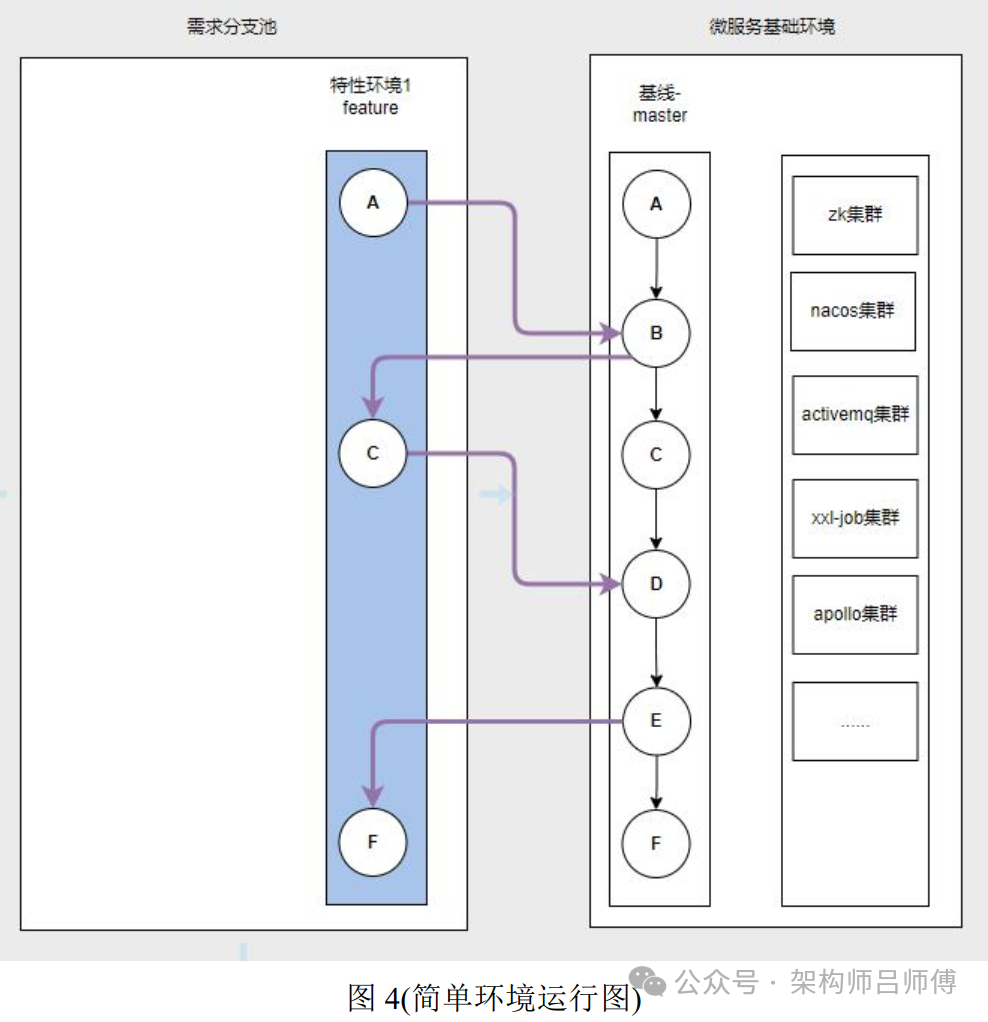
一个开发组在需求池中领取一个需求的时候, 会为当前需求建立一个唯一标识的特性环境标,以此环境标来建立需求相关的微服务应用资源, 然后开发就可在此资源上进行开发需求。此应用服务如果依赖了没有变更需求的微服务应用, 则不会给此特性环境建立此服务的资源, 以此达到复用基础环境资源。
图 4:就说明了需求 1 的特性环境依赖, 在开发资源过程中, 只有A、C、F应用进行了代码变更,则只申请对应的 A、C、F 资源, 其中中间件等服务都是公用服务。
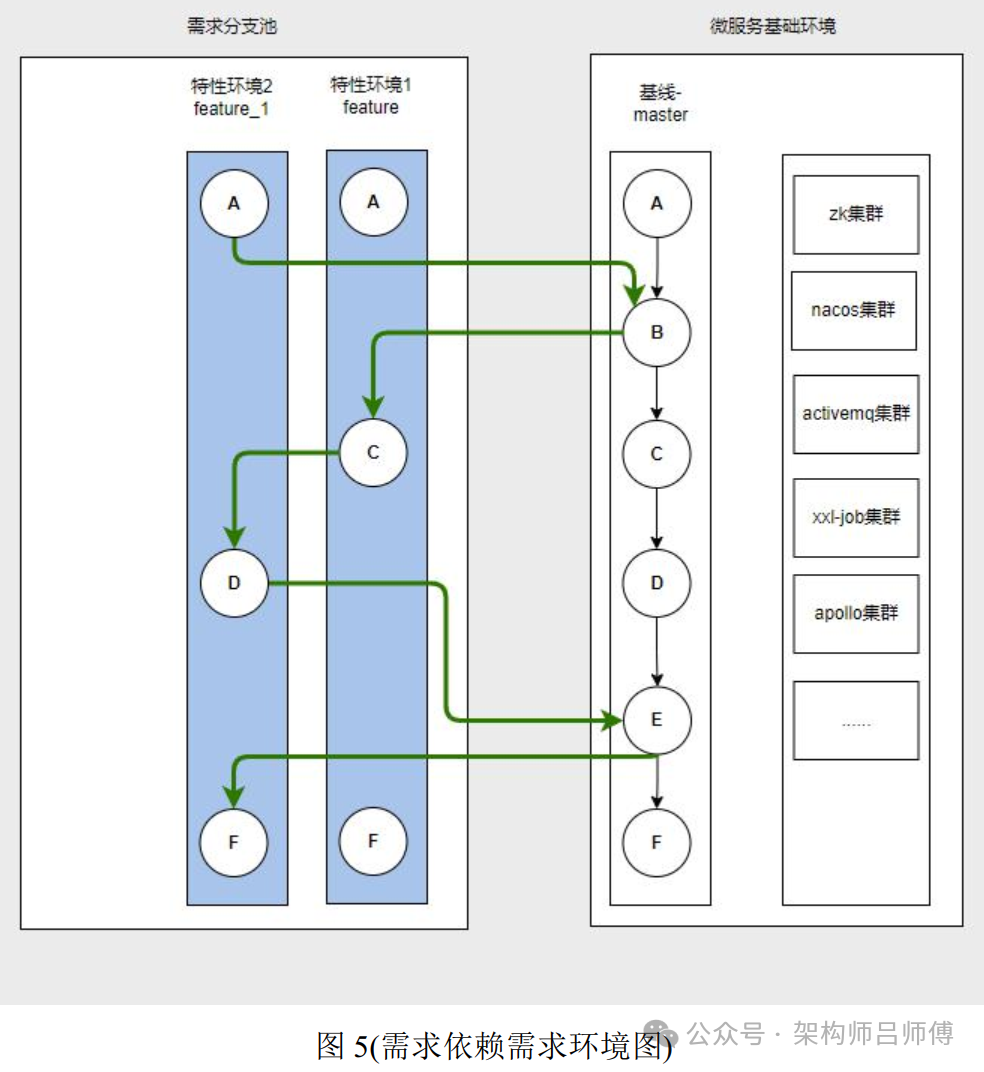
图 5:在开发过程中, 有些需求是并行的, 即多个需求变更了同一个项目的同一段相关逻辑,此时, 如果是传统业务开发, 各种开发各自的, 就会产生代码冲突问题。而此时从图中就能看出公用了 C 服务, 需求 2 的变更 A、C、D、F 中, C 的变更模块依赖了需求 1 的 C 的变更, 此时就能完美的解决冲突问题, 从而不会产生冲突。
环境搭建步骤
特性环境启动阶段
我们公司以 Kubernetes 作为部署平台, 就以此案例来讲。在容器化部署的过程中, 把当前容器的名称以服务名称和特性环境标结合来命名。例如:order-feature。如果是其他工具部署, 类似增加组合名称即可
容器启动的环境变量配置
容器启动过程中需要注册 zookeeper、 nacos、 activemq 等中间件资源, 注册上去的信息要附带当前环境变量的特性环境标值。
具体的请求调用阶段
请求调用时根据浏览器或者 app 发送的请求头中来确定当前请求的是那个特性环境, 如果请求头中没有加入特性环境标, 则视为走基线环境。在请求过程中如何根据环境标路由(寻找)对应的应用逻辑解决方案, 如下:
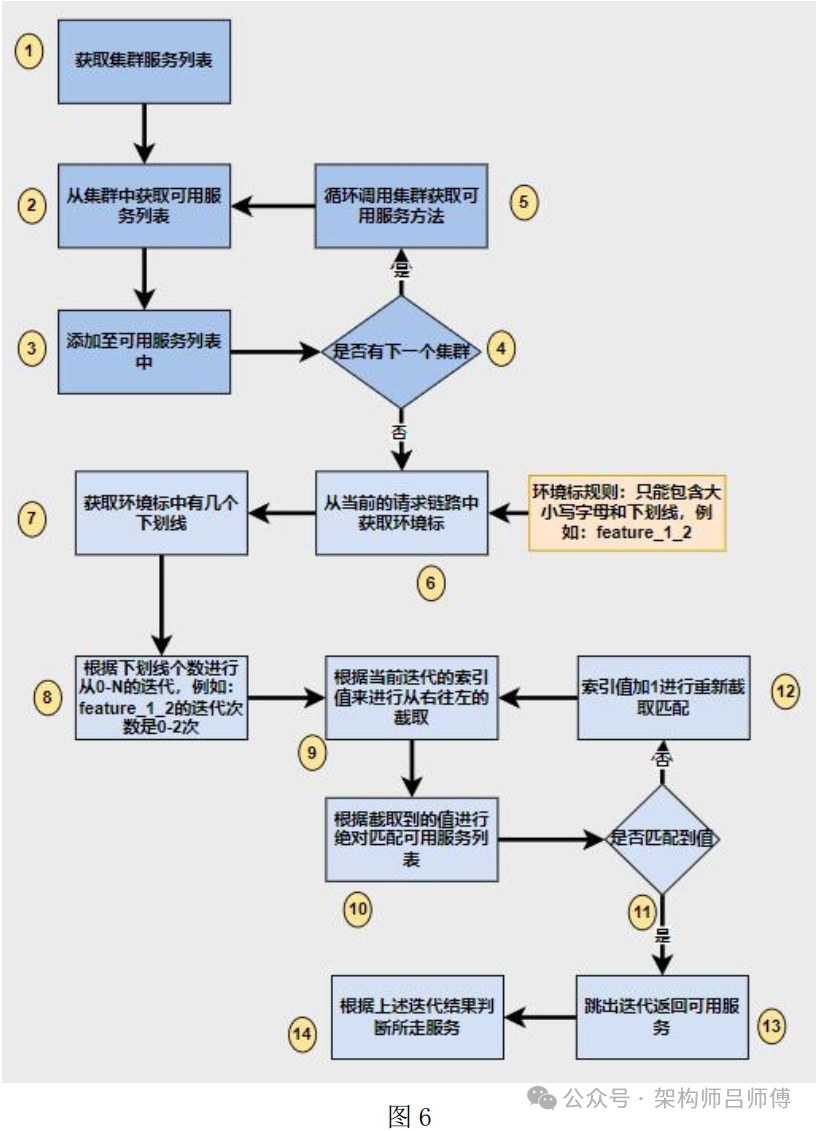
上图设计是匹配算法, 具体会落实到各个中间层,例如:dubbo 服务消费者寻找服务提供者、 消息中间件消息发送者寻找消息消费者、 xxl-job 寻找对应的服务执行者等。
具体步骤解析:
步骤 1:在发现服务过程中, 要先获取可用集群列表。
步骤 2:从集群列表中获取对应的所需的可用服务, 例如:A 逻辑代码需要获取 B 服务的 B_1 接口,如果存在, 则返回这个集群中 B_1 的提供者服务信息, 以便后面筛选调用。
步骤 3:把 2 结果添加到方法域缓存列表中。
步骤 4:判断是否存在多个集群环境。
步骤 5:如果有, 则继续进行迭代上述步骤。
步骤 6:如果没有, 则进行下个迭代的算法中。从当前的请求链路中获取环境标识。注意:此处使用到了全链路追踪技术, 最终的环境标识要根据具体的链路技术去获取。
步骤 7、 8、 9:根据规则计算迭代次数, 至少迭代一次。如果迭代一次, 则是没有子级需求。
步骤 10:获取迭代截取的值, 也就是特性环境标。然后根据不同的中间件去匹配不同的服务列表。此处的实现基于接口实现, 具体的实现逻辑跟有多个中间件一对一匹配。
步骤 11:判断是否匹配到值。
步骤 12:如果没有匹配到值, 迭代的索引值加一, 继续 8、 10、 11 操作 直至迭代数量终结。
步骤 13:如果匹配到值, 则为最优的服务列表, 即立即跳出迭代
步骤 14:最终服务选择逻辑, 如果没有匹配到, 则进行走基线服务。如果匹配到了, 则进行走所匹配到的服务。
小结
支持多级路由的测试环境,功能更加强大与灵活, 部署成本低。无需人工维护路由表, 部署时设置微服务的环境标识, 系统自动、 实时地维护依赖关系, 并自动路由到相应的父级环境, 如直接父级不存在, 则可以复用父父级环境, 直至复用根环境。很好的支持了有时间先后依赖的这种常见业务需求的并行研发, 大大提高研发效率。也可以非常方便对某个环境的服务进行本地服务的在线替换、 调试, 而不会阻碍、 影响其他开发和测试人员的正常工作

匹配示例
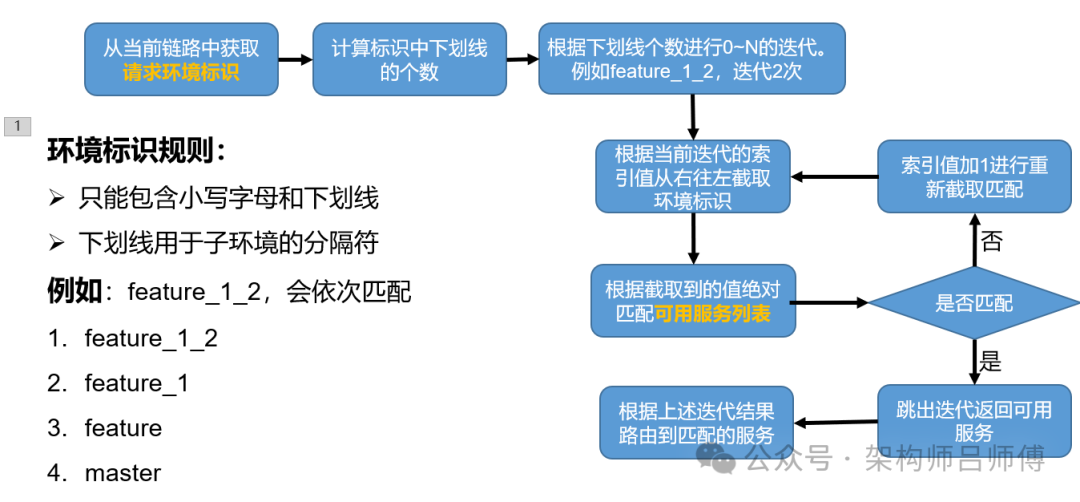
多级环境路由算法
如果你觉得这篇文章对你有帮助,请关注我的公众号“架构师吕师傅”,我们可以进一步讨论实现方案和细节。你的支持永远是我前进的动力~~~
















 2077
2077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











