







数据分析之路持续学习中- - -
近期学习了机器学习中的数据预处理章节,在此进行分享,欢迎大家讨论指正。
顺便说一下,这里我使用的软件是Anacnoda 3中已经安装好的Spyder 3,这个软件用起来很爽,适合用来做数据分析,缺点就是不好进行调试以及管理大型项目。
如果是要用来做网页等大型工程的话,建议:Anacnoda + Pycharm。
数据预处理有哪些步骤?
机器学习中,数据预处理全流程一般包含以下6大步骤:
(1)导入标准库:如:pandas、numpy、matplotlib等;
(2)导入数据集:将需要分析的数据读入;
(3)缺失数据处理:对数据表中的空值进行处理;
(4)分类数据:将需要的维度数据(如:国家)转换为能带入公式中的可度量值;
(5)数据划分训练集、测试集:将数据集的数据按一定比例进行随机拆分,形成训练集与测试集;
(6)特征缩放:将不在同一数量级的数据进行处理,加快程序运行速度,以及尽快得到收敛结果。
一般情况下,我们得到的数据集都是经过处理的比较规整的数据,因此,常用的4个步骤是:
- 导入标准库;
- 导入数据集;
- 数据划分训练集、测试集;
- 特征缩放;
下面将对6个步骤进行分步解读:
步骤1:导入标准库
在数据分析或机器学习中,常用的3个标准库如下:
(1)numpy
numpy是Python的一个高性能科学计算和数据分析的基础包,拥有强大的数组和矢量的计算方法可供直接调用。
(2)pandas
基于numpy创建的,含有DataFrame等高级数据结构和操作方法,能够让数据处理问题变得更简单更高效。
(3)matplotlib
是一个类似于Matlab的一个画图工具,是python的一个画图基础包,能够使用它其中的方法画出各种可视化图表;
下面将给出导入标准库的代码:
# Step1:导入标准库,Importing the Libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
步骤2:导入数据集
导入数据集,需要用到pandas标准库中的数据读入函数,我们常用其读入csv文件或者excel文件:
- 读取csv或者text文件:read_csv();
- 读取Excel文件:read_excel();
使用方法,以csv文件为例,就是:dataset = pd.read_csv(‘data.csv’)
我们以图中数据data.csv为例,进行导入:
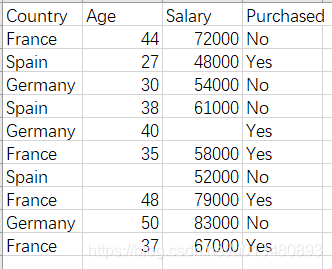
导入数据后,我们还需要将数据的自变量和因变量进行分离,以达到数据分析目的。
# Step2:导入数据集
dataset = pd.read_csv('data.csv')
# 自变量与因变量分离,自变量取前三列,因变量为最后一列,是否购买
x = dataset.iloc[:,:-1].values
y = dataset.iloc[:,3].values
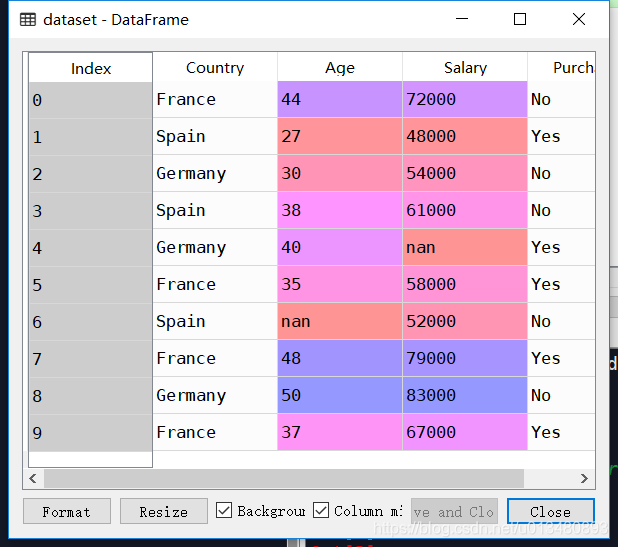
得到的结果如图所示:
(1)得到的DataFrame
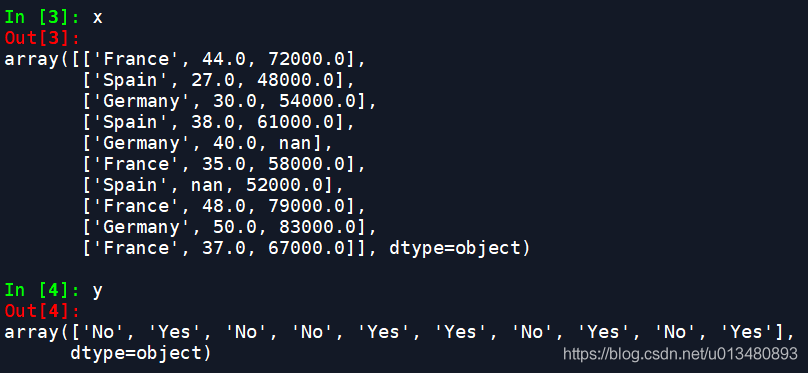
(2)得到的自变量和因变量如图:
步骤3:缺失数据处理
在我们要分析的数据中,有时候会因为数据采集不全等情况,而导致数据出现空值的情况。在数据分析的时候为了避免因为异常数据而带来的影响,我们可能需要想办法补齐这些数据。有人会说那删掉可以么?答案是:最好不要删除数据,因为有可能会删除重要数据,我们尽量保持数据样本的容量大一些,这样分析结果会更精准。
我们可以使用如下方法,填充空值:
- 使用平均值填充;
- 使用中位数填充;
- 使用众数填充
但我们一般用平均数来填充,因为平均数在解释的意义上,比中位数是更具有优势,更具有解释性。这可以理解为大家喜欢用平均数说话,也更具有代表性,比如一般都说人均工资,而不会说人中位数工资是多少…
使用平均数对缺失值进行补充,代码如下:
# 导入数据预处理包
from sklearn.preprocessing import Imputer
# 对于Imputer的使用,这里不做详细解读
# 第一个参数为处理何值,第二个参数为如何处理(mean为平均数),第三个参数0意思是取列的平均值,后面为默认值,感兴趣的可查询官方文档进行研读。
imputer = Imputer(missing_values = 'NaN', strategy = 'mean', axis = 0, verbose = 0, copy = True)
# 对X进行拟合
imputer = imputer.fit(x[:,1:3])
# 将拟合结果返回到x中
x[:,1:3] = imputer.transform(x[:,1:3])
处理后结果如下:
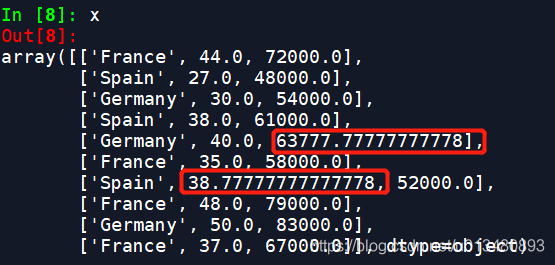
我们可以看到原来的nan值已经替换为了平均值,缺失数据的处理就结束了
步骤4:分类数据
我们可以看到在数据中,因变量x中,有一列为Country,这一列是无法带入公式中计算的,因此我们需要将其进行分类,处理为可带入公式计算的矢量。
这里我们需要用到sklearn中的两个方法:
- LabelEncoder:将数据进行标准化处理;
- OneHotEncoder:将标准化数据,进行虚拟化处理。
处理代码如下:
# Step4:分类数据 Encoding Categorical data
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
# 创建一个对象
labelencoder_x = LabelEncoder()
# 告诉程序处理哪一列数据
x[:,0] = labelencoder_x.fit_transform(x[:,0])
# 通过处理,使得无意义的维度代码,变成有意义的数据,以便带入公式中计算
onehotencoder = OneHotEncoder(categorical_features = [0])
x = onehotencoder.fit_transform(x).toarray()
# 同上处理,不同的是:因变量不用转换,因为python会自动识别其为分类数据,因此只要将其进行LabelEncoder处理即可
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
处理结果如图:
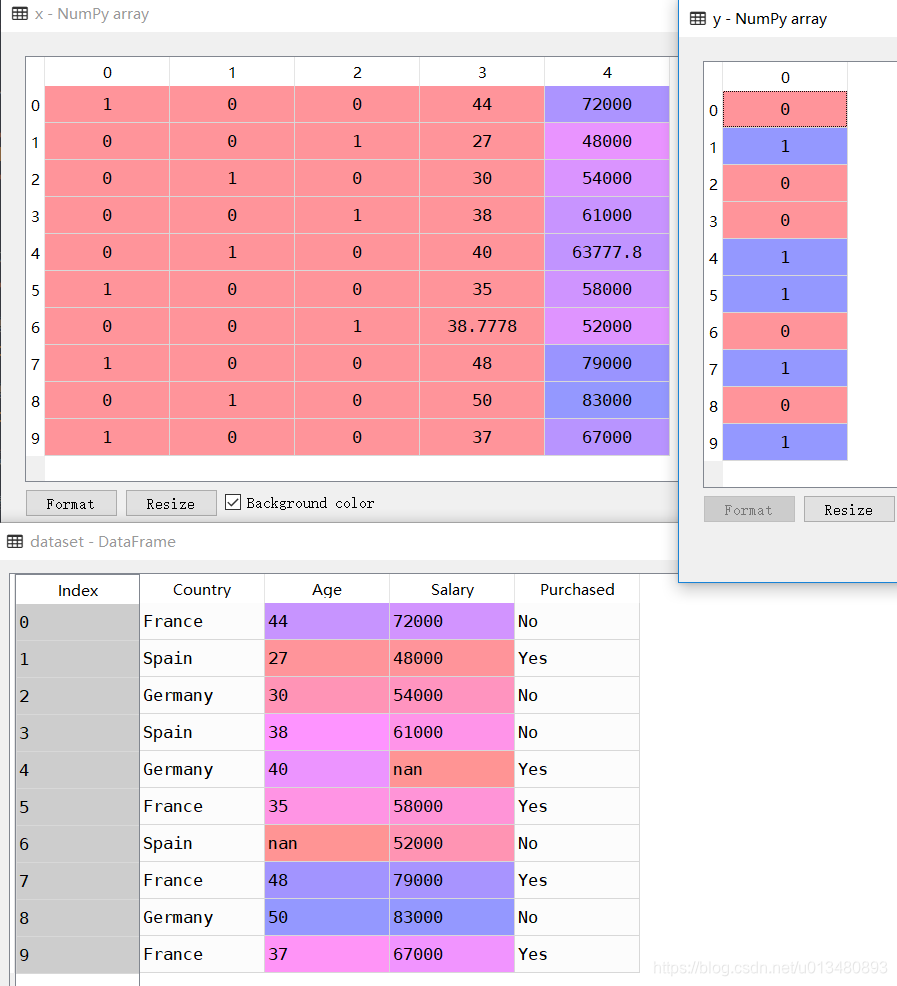
步骤5:将数据划分为训练集和测试集
所谓机器学习,即让机器“自己学”,因此需要提供一定量的训练集供我们的模型进行训练,训练完成后我们还需要将一部分数据进行检验,查看效果如何。
一般的训练集与测试集的比例如下:
- 训练集:0.5 - 0.8(最少最少0.5)
- 测试集:0.2-0.8(一般选择0.2或者0.25或者1/3)
用Python实现训练集与测试集的划分如下:
# Step5:将数据划分为训练集与测试集
from sklearn.preprocessing import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 0)
所得训练集与测试集如图所示:
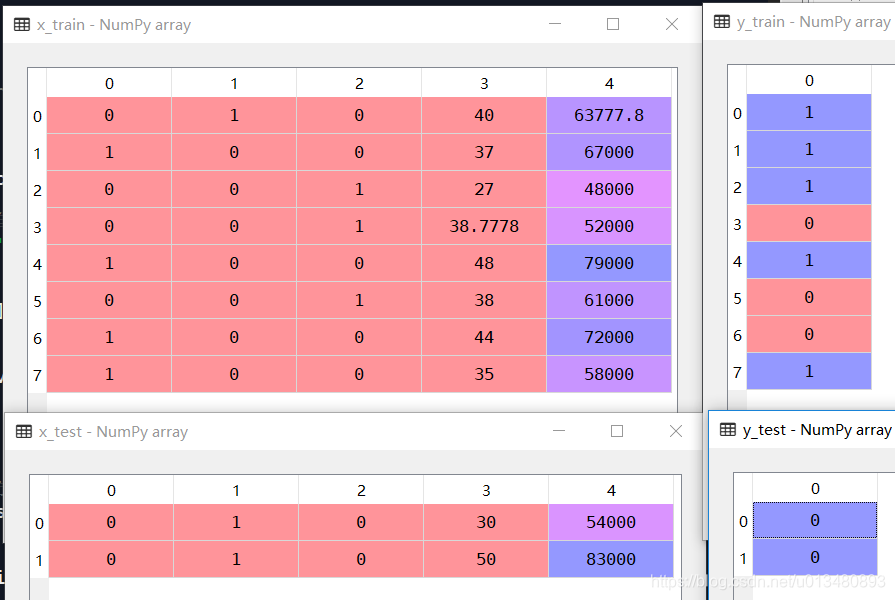
步骤6:特征缩放
在计算过程中,由于数据之间不在一个数量级,那么有可能所得的结果会比较难看,收敛情况比较难得到,计算性能也会相对较慢,因此会进行特征缩放操作。
python中进行特征缩放会用到Sklearn中的StandardScaler,因此需要进行导入
python的特征缩放代码如下:
# Step6:特征缩放
from sklearn.preprocessing import StandardScaler
sc_x = StandardScaler()
x_train = sc_x.fit_transform(x_train)
x_test = sc_x.fit_transform(x_test)
进行特征缩放后,所得结果如下图所示:
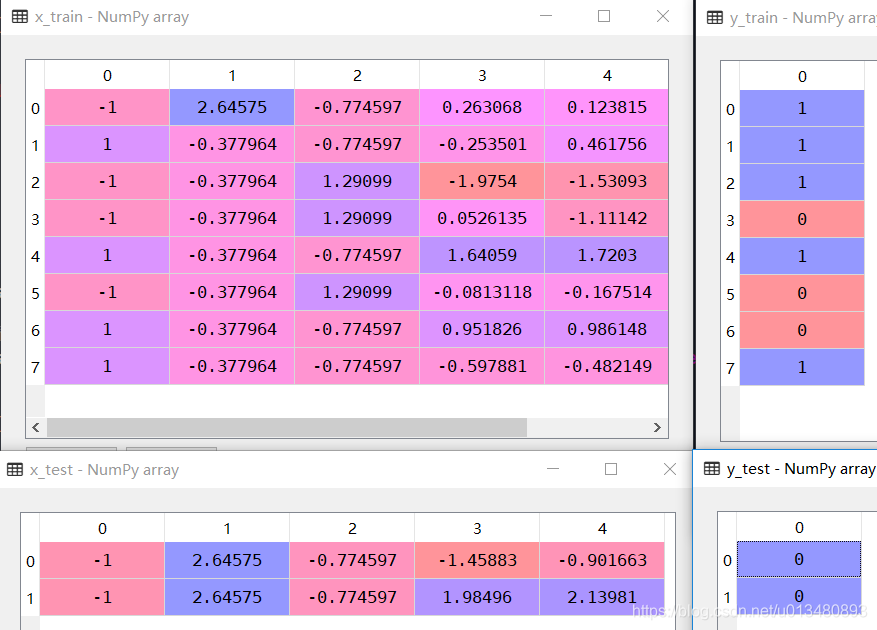
以上就是机器学习的Python数据预处理代码。经过预处理后,就可以进行后续的数据挖掘操作了。
也欢迎大家关注我的知乎专栏《数据分析学习之路》,我将持续更新我数据分析学习之路的点点滴滴,与大家共同进步。谢谢大家!














 690
690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









