






ELK 是三款软件的组合。是一整套完整的解决方案。分别是由 Logstash(收集+分析)、ElasticSearch(搜索+存储)、Kibana(可视化展示)三款软件。ELK主要是为了在海量的日志系统里面实现分布式日志数据集中式管理和查询,便于监控以及排查故障。
Elasticsearch 部署安装
ElasticSearch 是一个基于 Lucene 的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful API 的 web 接口。Elasticsearch 是用 Java 开发的,并作为 Apache 许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
[root@seichung ] wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.2.rpm # 官网下载软件包
[root@seichung ] yum -y install java-1.8.0 # 相关依赖包
[root@seichung ] yum -y install epel-release
[root@seichung ] yum localinstall -y elasticsearch-6.4.2.rpm 安装完成之后,修改 ElasticSearch 的配置文件,然后启动 ElasticSearch 服务。
[root@seichung ] vim /etc/elasticsearch/elasticsearch.yml
# 将如下的内容的注释取消,并将相关信息改成你在配置时的实际参数
***注意:配置文件的参数,在冒号后都有一个空格,如没有空格,服务会启动失败,并且无任何提示
cluster.name: ES-cluster # 集群名称,可更改
node.name: es1 # 为本机的主机名
network.host: 192.168.4.1 # 为本机的IP
http.port: 9200 # elasticsearch服务端口,可更改
discovery.zen.ping.unicast.hosts: ["es1", "es2","es3"] # 集群内的主机(主机名,不一定全部都要写)
node.master: true # 节点是否被选举为 master
node.data: true # 节点是否存储数据
index.number_of_shards: 4 # 索引分片的个数
index.number_of_replicas: 1 # 分片的副本个数
path.conf: /etc/elasticsearch/ # 配置文件的路径
path.data: /data/es/data # 数据目录路径
path.work: /data/es/elasticsearch # 工作目录路径
path.logs: /data/es/logs/elasticsearch/logs/ # 日志文件路径
path.plugins: /data/es/plugins # 插件路径
bootstrap.mlockall: true # 内存不向 swap 交换
http.enabled: true # 启用http
# 如果目录路径不存在的,需要先创建
[root@seichung ] /etc/init.d/elasticsearch start # 启动服务
[root@seichung ] systemctl enable elasticsearch # 开机自启一个简单的 ElasticSearch 就搭建好了,如果要部署一个ES集群,那么只需要在所有主机上部署好 Java 环境,以及在所有主机上的 /etc/hosts 解析主机,如下:
此操作是在ES集群主机上必做
[root@seichung ] yum -y install java-1.8.0
[root@seichung ] vim /etc/hosts
192.168.4.1 es1
192.168.4.2 es2
192.168.4.3 es3将已经完成 elasticsearch 服务安装的主机,将 hosts 文件、elasticsearch.yml 配置文件拷贝一份到集群主机上,只要修改 node.name: 为本机的主机名 即可,然后将服务启动起来
最后来查看下 Es 集群是否部署好,不成功则 number_of_nodes 永远为 1 ,成功会有下图信息,:
[root@seichung ] curl -i http://192.168.4.1:9200/_cluster/health?pretty
# 返回的信息包括集群名称、集群数量等,如果 number_of_nodes 显示的是实际得集群数量,则说明集群部署成功
{
"cluster_name" : "ES-cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 26,
"active_shards" : 52,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}ElasticSearch 插件安装
# 采用本地安装,也可以采用远程安装
[root@seichung ] /usr/share/elasticsearch/bin/plugin install file:///data/es/plugins/elasticsearch-head-master.zip
[root@seichung ] /usr/share/elasticsearch/bin/plugin install file:///data/es/plugins/elasticsearch-kopf-master.zip
[root@seichung ] /usr/share/elasticsearch/bin/plugin install file:///data/es/plugins/bigdesk-master.zip
[root@seichung ] /usr/share/elasticsearch/bin/plugin list # 查看已安装的插件插件安装完成之后,访问对应插件的 Url,如果访问出现如下图,则成功:
head 插件展示图 http://192.168.4.1:9200/_plugin/head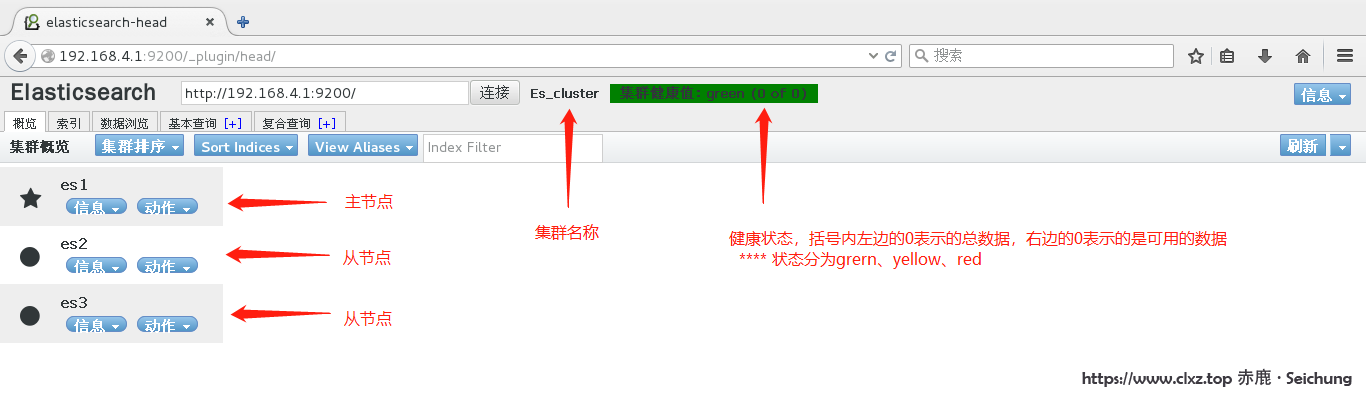
kopf 插件展示图 http://192.168.4.1:9200/_plugin/kopf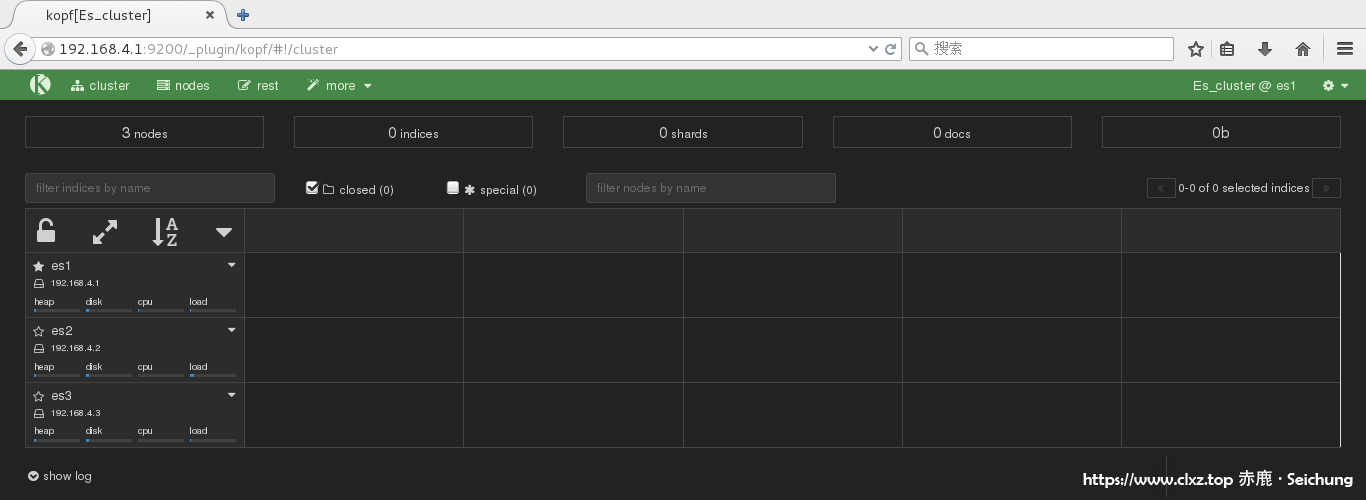
Bigdesk 展示图 http://192.168.4.1:9200/_plugin/bigdesk
Logstash 部署安装
logstash 是一个数据采集、加工处理以及传输的工具,能够将所有的数据集中处理,使不同模式和不同数据的正常化,而且数据源能够随意轻松的添加。
安装 logstash 软件包
[root@seichung ] wget https://artifacts.elastic.co/downloads/logstash/logstash-6.4.2.rpm安装完成编写logstash.con日志收集文件测试:
[root@seichung ] vim /etc/logstash/logstash.conf
# 编写简单的收集日志文件
input{
stdin{}
}
output{
elasticsearch{
hosts => ["192.168.4.1:9200","192.168.4.2:9200","192.168.4.3:9200"]
}
}编写完后,使用命令查看下 logstash.conf 是否无误 /opt/logstash/bin/logstash -f /etc/logstash/logstash.conf --configtest --verbose,需要注意的是,yum 安装的 Logstash 默认在 /opt 目录下。源码安装可以自行指定。
[root@seichung ] /opt/logstash/bin/logstash -f /etc/logstash/logstash.conf --configtest --verbose如果出现 Configuration OK字样,则说明文件准确无误
在确认 logstash.conf 文件无误后,利用 logstash.conf 里面的语句进行数据的收集,然后在屏幕上输入你想测试的数据。
详细见下图:
在输入后,再回到 Es 查看是否有刚刚在屏幕上输入的数据。
下图可以看到,数据已经分别写入到了刚刚搭建好的 Es 集群中。
此外,再来看看刚刚收集的数据的详细信息:
通过简单测试,可以得出的 Es 集群是处于健康状态并且可以收集到数据的。那么自动的收集日志数据,等搭建完 Kafka 时一同实现。
Kafka 部署安装
Apache kafka 是消息中间件的一种,是一种分布式的,基于发布/订阅的消息系统。能实现一个为处理实时数据提供一个统一、高吞吐、低延迟的平台,且拥有分布式的,可划分的,冗余备份的持久性的日志服务等特点。
将下载的 kafka tar 包解压到指定的位置,并修改 zookeeper 集群文件以及 kafka 的 server 文件,如下:
[root@seichung ] wget http://mirror.bit.edu.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz
[root@seichung ] tar -xvf kafka_2.11-2.0.0.tgz -C /opt/
[root@seichung ] cd /opt/kafka_2.11-2.0.0/zookeeper 集群
[root@seichung kafka_2.11-2.0.0] vim config/zookeeper.properties
dataDir=/data/zookeeper # 指定 zookeeper 的目录,如果不存在则需要创建
tickTime=2000 # 客户端与服务器之间维持心跳的时间间隔
initLimit=20
syncLimit=10
server.1=192.168.4.1:2888:3888 # 2888 表示的是 zookeeper 集群中 Leader 的端口
server.2=192.168.4.2:2888:3888 # 3888 表示的是如果 Leader 宕掉了,那么从 3888 端口中重新选举新的Leader
server.3=192.168.4.3:2888:3888 kafka 服务配置
[root@seichung kafka_2.11-2.0.0] vim config/server.properties
broker.id=0 # 唯一的
port=9092
host.name=192.168.4.1
log.dirs=/data/kafka-logs # 注意这里的是 kafka 的存储目录。并不是存放日志的目录,当你启动kafka的时候,会自动在当前目录下生成一个 log 专门存放 kafka 的日志文件。如果没有需创建
zookeeper.connect=192.168.4.1:2181,192.168.4.2:2181,192.168.4.3:2181 #这里可以是主机名,也可以是 ip,但是填写的是主机名,就必须在 /etc/hosts 文件下进行解析才可以生效上述的操作是单机的 kafka,如果需要搭建 kafka 集群,那么将修改好的 kafka 整个目录 scp 到集群服务器上即可。
另外需要注意的是:修改每台主机配置文件下的个别参数,主要修改如下操作,以下操作均在 server.properties 上操作:
broker.id = x # x:是任意数,只要不重复即可
host.name=xxx.xxx.xxx.xxx 这里填写的应为本机的 IP 地址
# 创建相关文件夹以及文件,如在创建了 /data/zookeeper 后,下面应该还得再执行
echo 1 > /data/zookeeper/myid 每台机器操作的数字也不能一样当在集群主机上都修改好配置文件参数后,随后就是将 zookeeper 集群启动,以及将 kafka 服务启动起来。如下:
后台启动 zookeeper,在集群主机上进行操作即可
[root@seichung ] /opt/kafka_2.11-2.0.0/bin/zookeeper-server-start.sh -daemon /opt/kafka_2.11-2.0.0/config/zookeeper.properties 后台启动 kafka 服务,在集群主机上进行操作即可
[root@seichung ] /opt/kafka_2.11-2.0.0/bin/kafka-server-start.sh -daemon /opt/kafka_2.11-2.0.0/config/server.properties查看 2888、3888、2181、9092 端口是否都已经启动,如果 2888、3888 端口不存在,那么在 /opt/kafka_2.11-2.0.0/log/ 下查看 zookeeper.out 以及 server.log 报错信息
[root@seichung ] netstat -antulp | grep -E '2181|2888|3888|9092'配置了zookeeper集群以及kafka集群,启动了服务如下图为成功,缺一则为失败: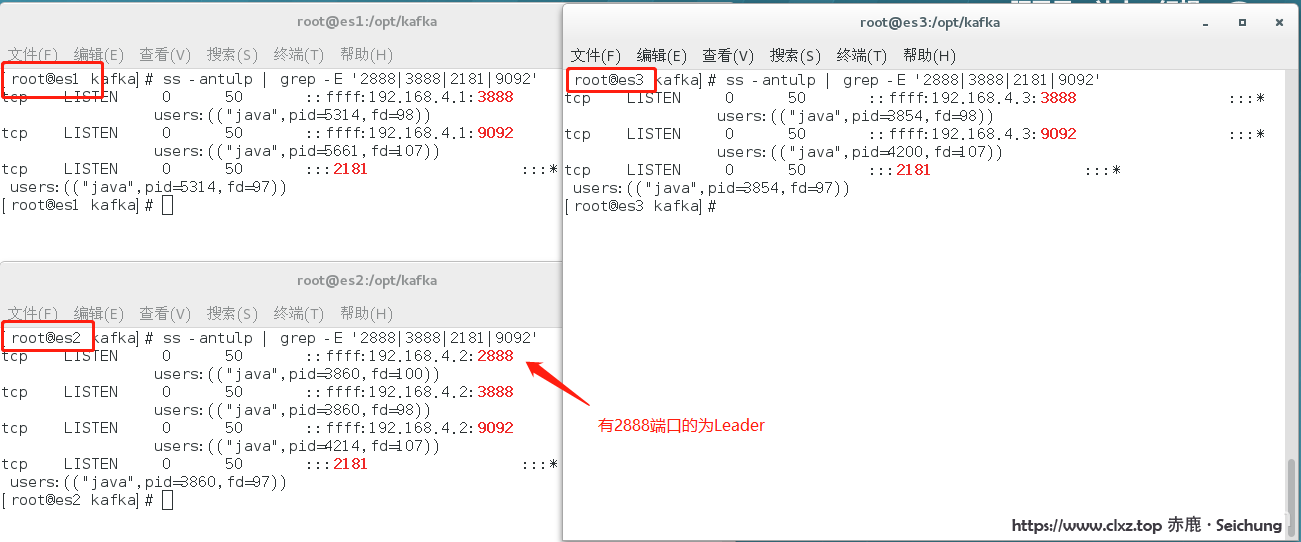
然后,来测试下,kafka是否可用:
新增一个 topic,然后 scon 为他分配一个分区,设置副本
[root@seichung ] /opt/kafka_2.11-2.0.0/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 5 --topic scon
# 这里需要非常注意,就是 factor 数不能超过 broke r数。broker 数就是集群机器的总数。如,编者的集群机器数为3台,那么 factor 的数就不能大于 3,只能 <=3.查看新创建的主题scon
[root@seichung ] /opt/kafka_2.11-2.0.0/bin/kafka-topics.sh --list --zookeeper localhost:2181
[root@seichung ] /opt/kafka_2.11-2.0.0/bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic scon修改创建的 scon 主题,这里将副本数 5,修改为 6
[root@seichung ] /opt/kafka_2.11-2.0.0/bin/kafka-topics.sh --alter --zookeeper localhost:2181 --partitions 6 --topic scon删除创建的 scon 主题
[root@seichung ] /opt/kafka_2.11-2.0.0/bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic scon注意: 是否开启 topic 的删除功能:默认为 false
delete.topic.enable 在 /opt/kafka_2.11-2.0.0/conf/server.properties 中
修改为:delete.topic.enable=true
测试效果如下图: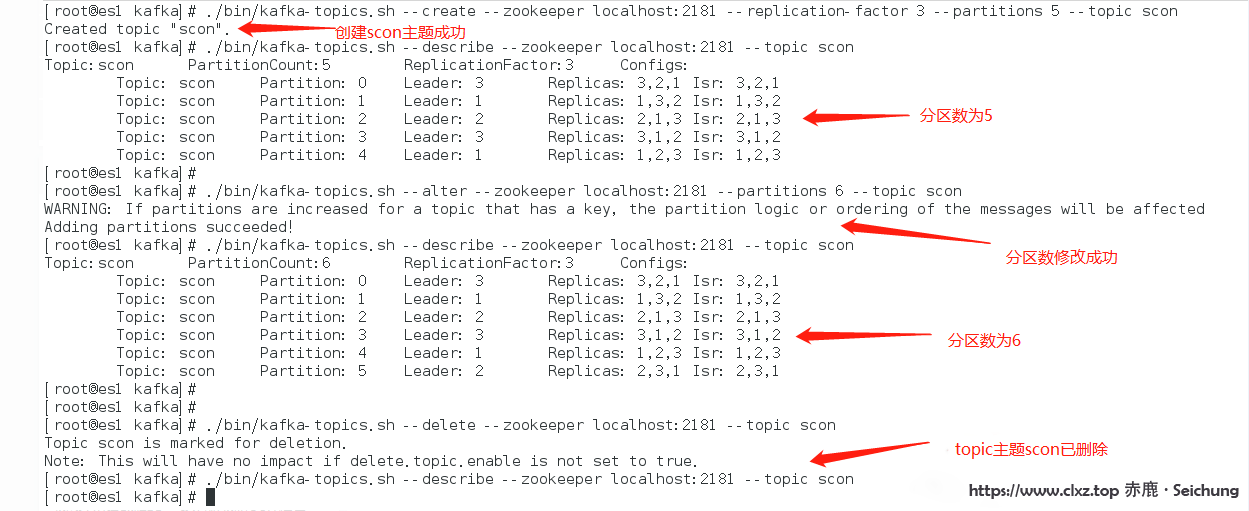
那么,Kafka 的集群环境已经搭建完成,那么需要测试下,logstash 是否能够将收集到的日志数据传递到 kafka 上,最后经过 kafka, 再将数据传到的 Es 集群上。
Redis 同样可以,为什么要选择 kafka ?
都知道 Redis 是以 key 的 hash 方式来分散对列存储数据的,且 Redis 作为集群使用时,对应的应用对应一个 Redis,在某种程度上会造成数据的倾斜性,从而导致数据的丢失。
而从之前部署 Kafka 集群来看,kafka 的一个 topic(主题),可以有多个 partition(副本),而且是均匀的分布在 Kafka 集群上,这就不会出现 redis 那样的数据倾斜性。Kafka 同时也具备 Redis 的冗余机制,像 Redis 集群如果有一台机器宕掉是很有可能造成数据丢失,而 Kafka 因为是均匀的分布在集群主机上,即使宕掉一台机器,是不会影响使用。同时 Kafka 作为一个订阅消息系统,还具备每秒百万级别的高吞吐量,持久性的、分布式的特点等。
接下来将编写 logstash.conf 文件,将收集日志文件并到 kafka。如下:
[root@seichung ] vim /etc/logstash/logstash.conf
input{
file {
type => "weblog" # 定义日志文件类型
path => "/opt/access.log" # 日志文件路径,这里收集 web 的日志文件
start_position => "beginning" # 从第一行开始读取数据
}
}
output {
kafka {
bootstrap_servers => "192.168.4.1:9092,192.168.4.2:9092,192.168.4.3:9092" # kafka 集群主机
topic_id => "web-log" # 主题名称,会自动创建
compression_type => "snappy" # 压缩方式
}
}
# 查看 kafka,logstash 是否成功将数据传入到 kafka 上
[root@seichung ] /opt/kafka_2.11-2.0.0/bin/kafka-topics.sh --list --zookeeper localhost:2181 如出现如下图,则数据写入成功:
这里可能就会有疑问了,收集时的分区数,副本数都是系统默认生成的,那么我该如何实现指定分区数,副本数?可以在收集时现行创建一个主题,然后再收集的时候就使用这个主题即可。如下:
[root@seichung ] /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.2.22:2181
--replication-factor 3 --partitions 7 --topic Topic_Name # 3个副本,7个分区好了,logstash 将数据写入到 kafka 已经是没有问题,那么接下来就是:如何将 kafka上 的数据信息写入到部署好的Es 集群上。当然,linux 可是” 一切皆文件 “。所以,还是修改 logstash.conf 的配置文件。
之所以使用 kafka 来进行数据存储,是为了减少 Es 集群前端的压力,所以加上了消息队列 Kafka 作为一个过渡。
编写配置文件,如下:
[root@seichung ] vim /etc/logstash/logstash.conf
input {
kafka {
zk_connect => "192.168.4.1:2181,192.168.4.2:2181,192.168.4.3:2181"
topic_id => "web-log"
reset_beginning => false
consumer_threads => 5
decorate_events => true
}
}
output {
elasticsearch {
hosts => ["192.168.4.2:9200","192.168.4.3:9200"]
index => "sc-%{type}-%{+YYYY.MM.dd}"
workers => 1
flush_size => 20000
idle_flush_time => 10
template_overwrite => true
}
}数据成功写入到Es集群,如下图所示: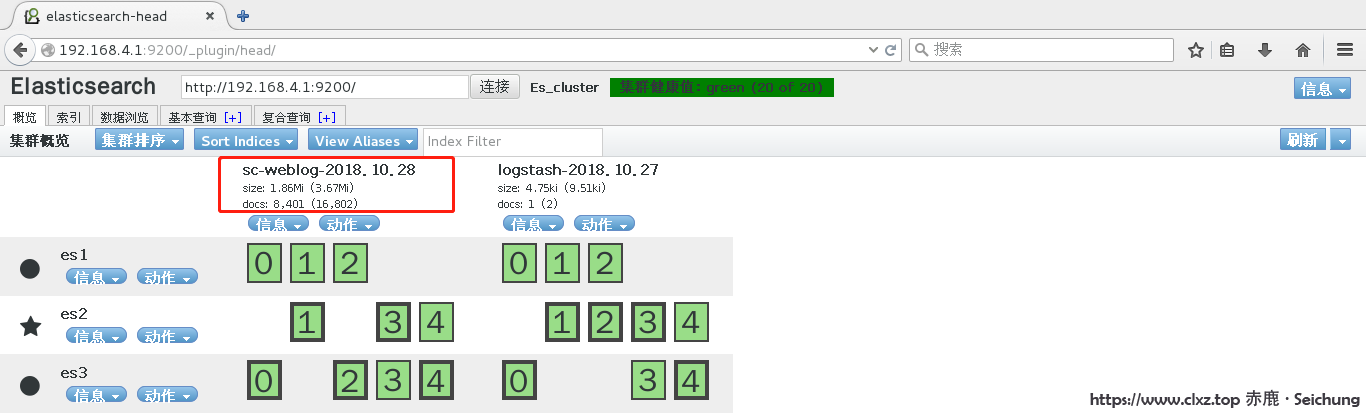
另外来看看详细的json数据信息: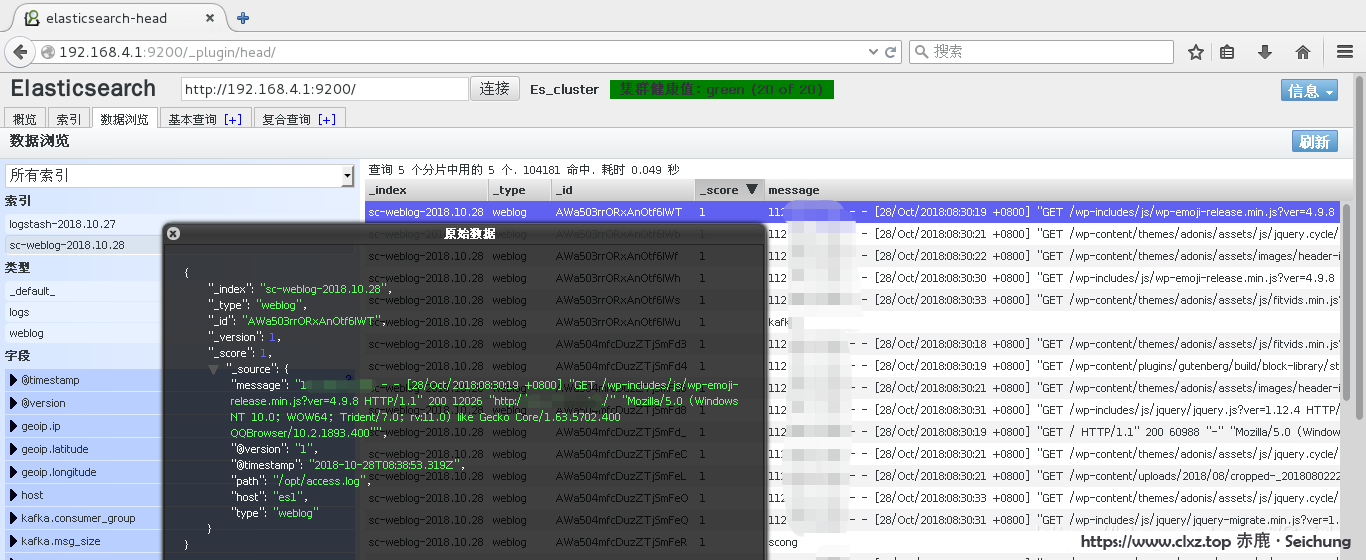
Kibana 部署安装
Kibana 是一个开源的分析与可视化平台,可以使用各种不同的图表、表格、地图等kibana能够很轻易地展示高级数据分析与可视化。
安装并启动 Kibana:
[root@seichung ] wget https://artifacts.elastic.co/downloads/kibana/kibana-6.4.2-x86_64.rpm
[root@seichung ] yum -y localinstall kibana-6.4.2-x86_64.rpm
# 在启动 Kibana 之前,先修改 kibana 的配置文件,修改完成后再启动 kibana 服务
[root@seichung ] vim /opt/kibana/config/kibana.yml
server.port: 5601 # kibana 的端口,切记一定不能修改端口,此端口是被写死在文件内的
server.host: "0.0.0.0" # kibana 的服务地址,可以是本地 IP 地址
elasticsearch.url: "http://192.168.1.11:9200" " # ES 的地址
kibana.index: ".kibana" #kibana的索引名称
kibana.defaultAppId: "discover"
elasticsearch.pingTimeout: 1500 # 连通 ES 的超时时间
elasticsearch.requestTimeoumeout: 30000 # ES 请求超时时间
elasticsearch.startupTimeoumeout: 5000
[root@seichung ] systemctl start kibana # 启动 kibana 服务
[root@seichung ] systemctl enable kiban # 开机自启动如果出现了如下图,则说明 kibana 服务跟 Es 集群已连通: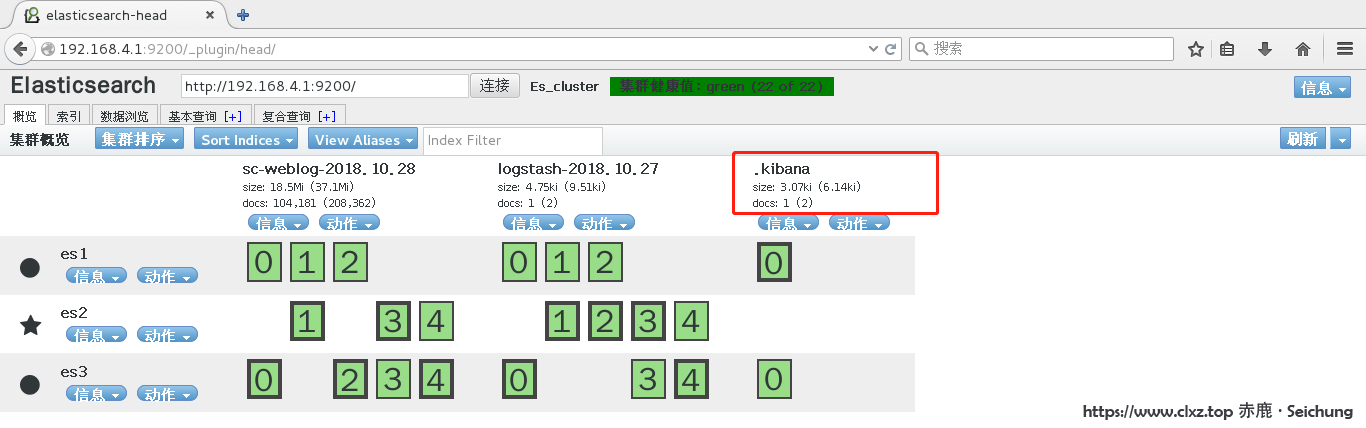
接下来来访问 kibana http://192.168.4.1:5601,如下图:
既然,Kibana 已经搭建成功,那么接下来就是如何的使用 Kibana,都知道 Kibana 是一个可视化的工具,它能制作不同的仪表盘以直观的方式展示。下面就来看看 kibana 是如何使用的。
一、填写需要制作的 index 名称: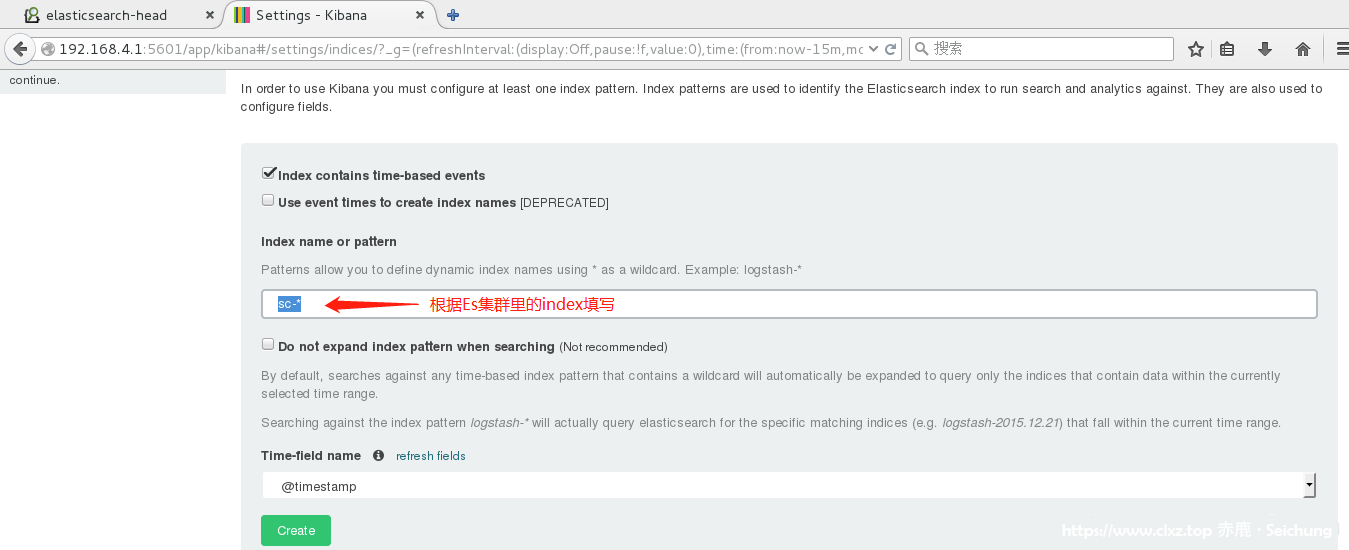
二、选择时间段查看数据: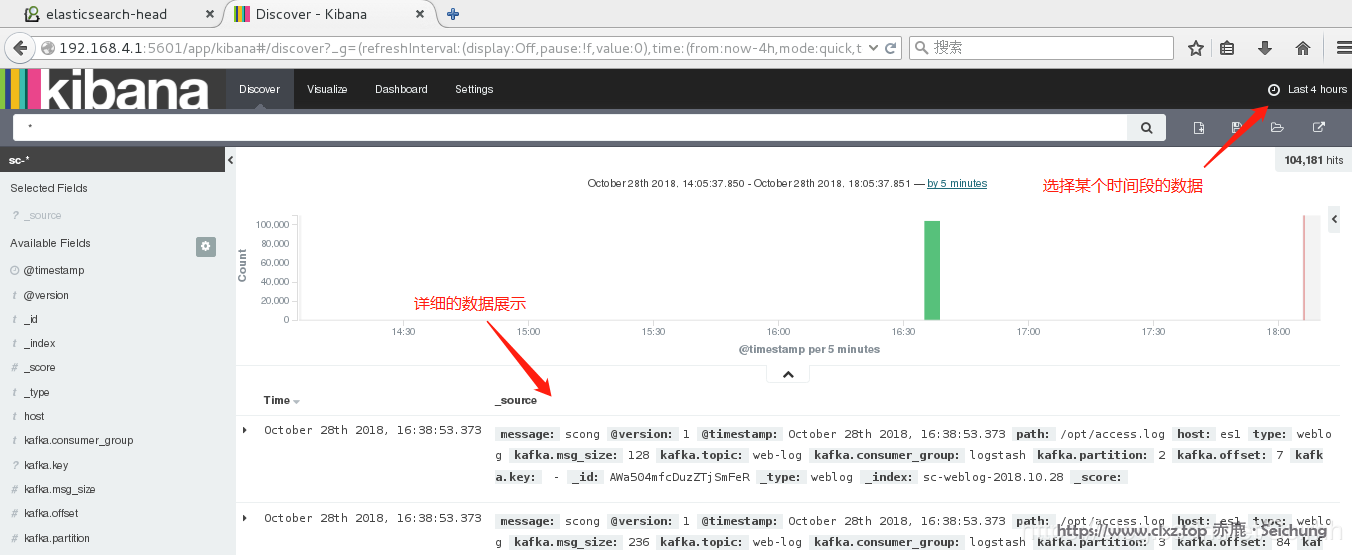
三、选择图形类型制作仪表盘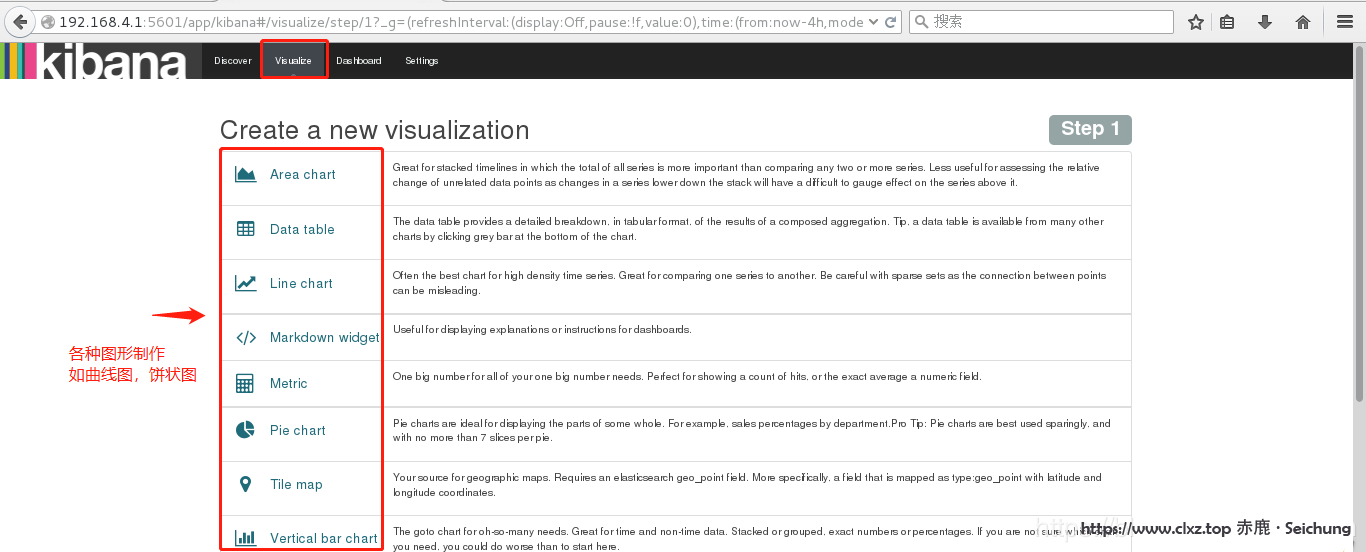
四、制作仪表盘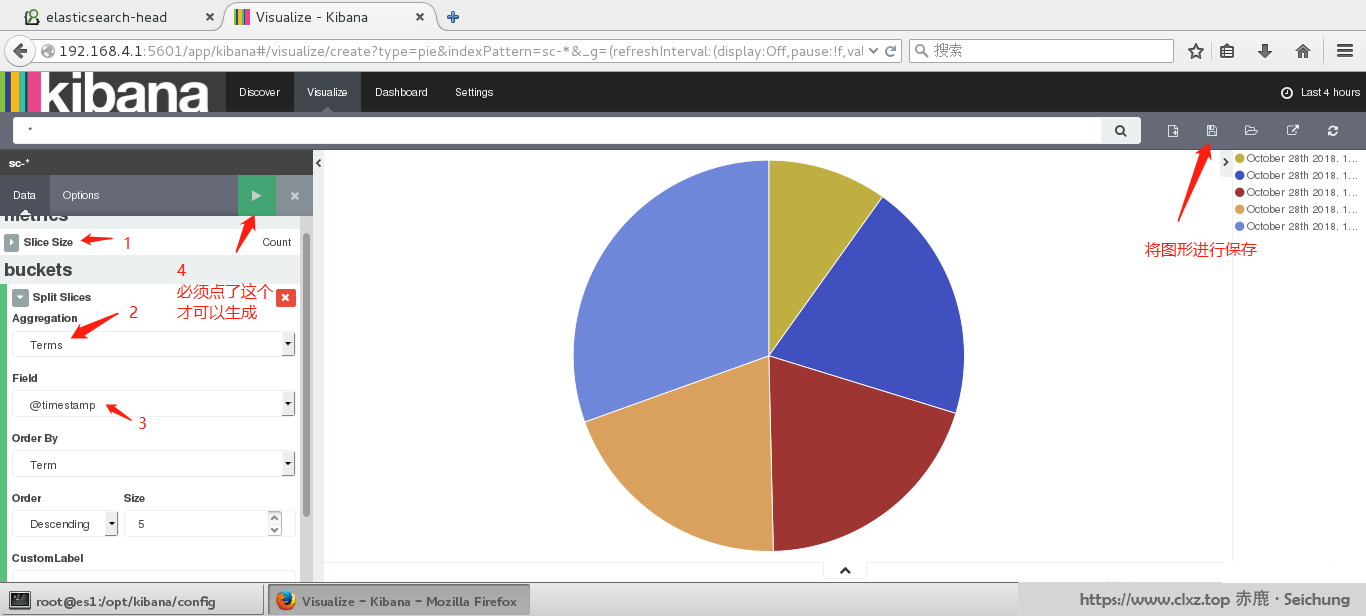
五、最后查看保存的仪表盘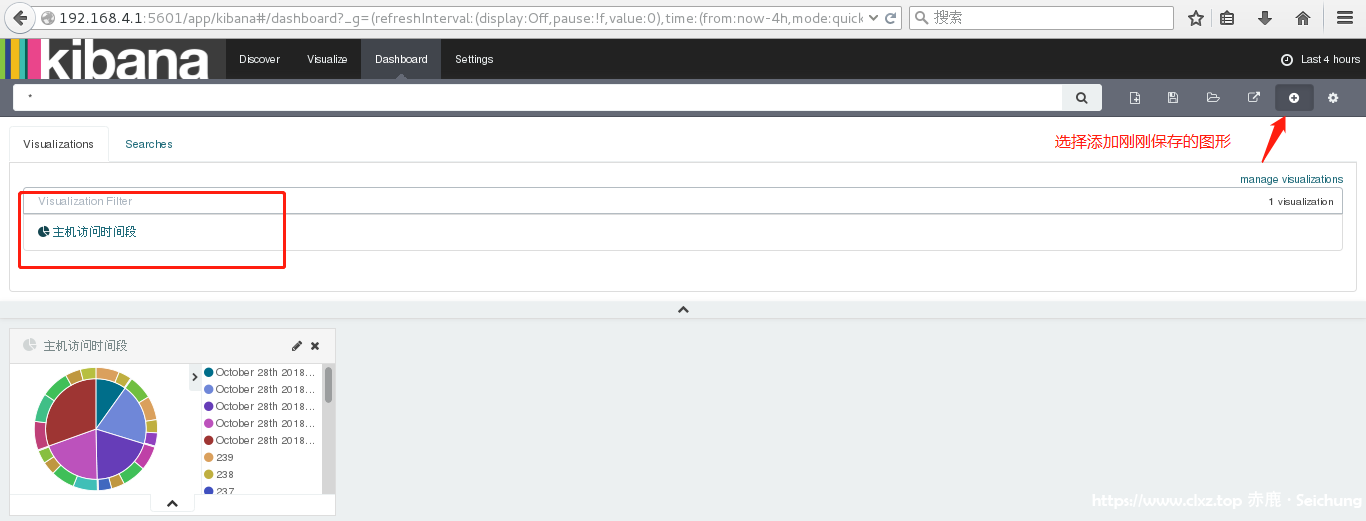
相对比杂乱无章的日志数据,以仪表盘的形式显现是不是更加清晰明了,且直击重点。在现如今每年全球的数据都会呈 2 倍的趋势增长的大数据时代。能够在海量的数据中能够实时且快速找到想要的重点,并且还能实时进行分布式的监控。或许这才是最为被大众所接受的。
至此,ELK + Kafka 架构已经搭建完成。















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









