



吕一婷
2
,
1
{ }^{2,1}
2,1,袁嘉康
1
,
3
,
1
{ }^{1,3,1}
1,3,1,李震
4
{ }^{4}
4,赵世田
1
{ }^{1}
1,秦琦
1
{ }^{1}
1,李新月
1
{ }^{1}
1
卓乐
1
{ }^{1}
1,温立成
1
{ }^{1}
1,刘东洋
1
{ }^{1}
1,曹岳文
1
{ }^{1}
1,颜祥超
1
{ }^{1}
1,李欣
2
{ }^{2}
2
石博天
1
{ }^{1}
1,陈涛
3
{ }^{3}
3,陈智波
2
,
66
{ }^{2,66}
2,66,白雷
1
{ }^{1}
1,张博
1
,
1
,
66
{ }^{1,1,66}
1,1,66,高鹏
1
{ }^{1}
1
1
{ }^{1}
1 上海人工智能实验室,
2
{ }^{2}
2 中国科学技术大学,
3
{ }^{3}
3 复旦大学,
4
{ }^{4}
4 香港中文大学
luyt31415@mail.ustc.edu.cn, jkyuan22@m.fudan.edu.cn, chenzhibo@ustc.edu.cn, zhangbo@pjlab.org.cn
https://alpha-innovator.github.io/OmniCaptioner-project-page
https://github.com/Alpha-Innovator/OmniCaptioner
https://huggingface.co/U4R/OmniCaptioner
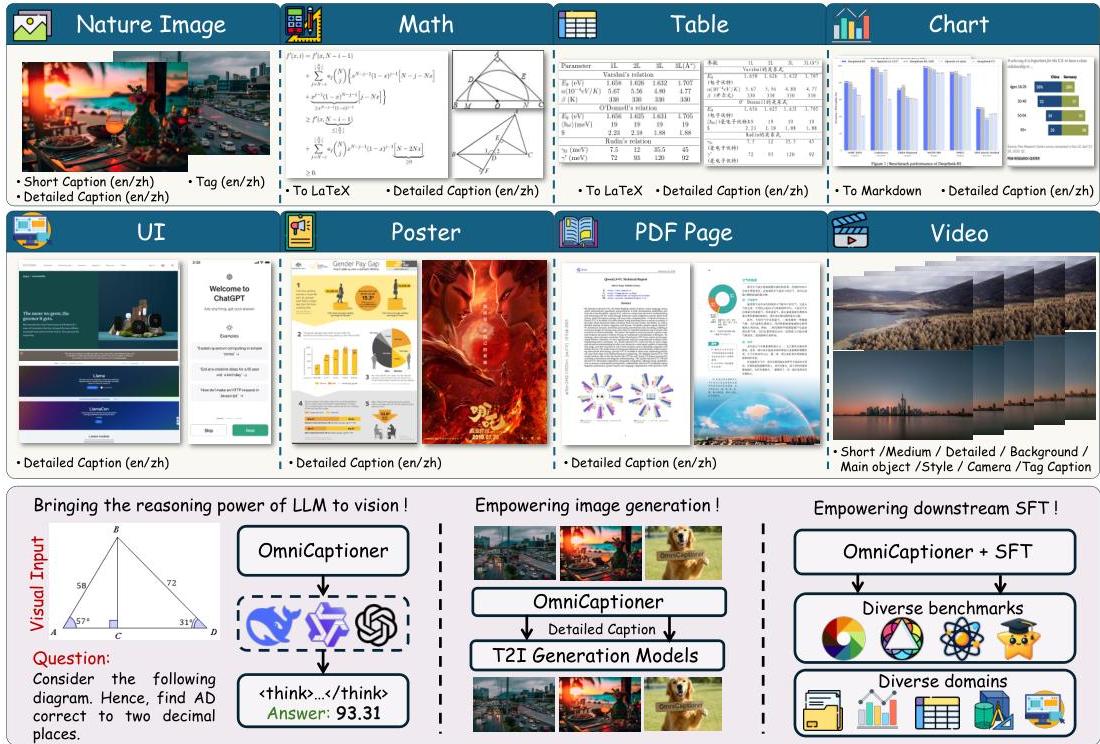
图1:OMNICATIONER:顶部部分展示了其处理多种视觉领域的能力。底部部分强调了其在视觉推理(与推理LLM结合)、图像生成(与T2I生成模型集成)和高效的下游SFT任务适应中的应用。
摘要
我们提出了OMNICATIONER,这是一个多功能的视觉字幕框架,用于生成跨广泛视觉领域的精细文本描述。与仅限于特定图像类型(例如自然图像或几何视觉)的先前方法不同,我们的框架为自然图像、视觉文本(如海报、用户界面、教科书)和结构化视觉内容(如文档、表格、图表)提供了统一的字幕解决方案。通过将低级像素信息转换为语义丰富的文本表示,我们的框架弥合了视觉和文本模态之间的差距。我们的结果突显了三个关键优势:(i) 增强的视觉推理能力与LLMs相结合,其中视觉模态的长上下文字幕增强了LLMs(特别是DeepSeek-R1系列)在多模态场景中的推理能力;(ii) 改进的图像生成,其中详细字幕提高了文本到图像生成和图像转换等任务的效果;以及(iii) 高效的监督微调(SFT),使数据需求更少且收敛更快。我们认为,OMNICAPTIONER的多功能性和适应性可以为弥合语言和视觉模态之间的差距提供新的视角。
1 引言
近年来,多模态大型语言模型(MLLMs)[23, 18, 6, 39, 2],特别是在弥合视觉和文本领域之间的差距方面,受到了广泛关注。在图像字幕和视觉问答方面取得了显著进展,使模型通过大规模监督微调(SFT)成为通用视觉助手。然而,MLLMs在视觉-文本和结构化图像领域仍面临感知准确性的限制,尤其是在处理与自然图像有显著领域差距的合成图像时,如图3©所示。
近期研究越来越强调图像字幕在多模态预训练期间对模态对齐的作用,旨在通过SFT过程增强感知和推理能力。同时,针对文档理解MLLMs [26, 15] 和数学MLLMs [33, 54, 41] 的领域特定研究利用领域特定字幕数据进一步改进模态对齐并推动多模态预训练。这些进展凸显了以图像字幕为中心的多模态预训练统一框架的需求。此外,尽管MLLMs有所进步,但它们的多模态推理能力仍不及纯文本LLMs。如图2所示,在MathVision和MathVerse基准测试中,仅提供问题而无视觉输入时,DeepSeek-Distill-Qwen-7B(橙色)显著优于Qwen2-VL-Instruct(蓝色),展示了LLM驱动推理在多模态任务中的强大能力。
在这项工作中,我们通过引入首个OMNICAPTIONER框架来弥合这一差距,设计用于生成跨多种视觉领域的精细文本描述,如图1所示。与之前专注于特定视觉类别(即自然图像或几何图像)的方法不同,我们的方法为各种图像类型提供统一解决方案,为更广泛的多模态理解铺平道路。我们专注于将低级像素特征转换为语义丰富的文本表示,保留关键视觉细节的同时弥合视觉与语言之间的模态差距。OMNICAPTIONER具有两个特点:i)多样化的视觉领域覆盖:我们提出一个统一框架,支持包括自然图像、视觉文本图像(如海报、用户界面、教科书)和结构化图像(如几何图形、方程、表格、图表)在内的多样化视觉内容。ii)像素到文本映射:通过将这些多样化的图像类型与详细字幕配对,我们将低级像素信息转换为语义丰富、细致入微的文本描述,从而实现对视觉内容的更深入理解,有效弥合视觉和文本模态之间的差距。
为了评估OMNICAPTIONER的有效性,我们在图像理解(如视觉推理)和图像生成任务(如文本到图像生成)上进行了系统评估。我们的结果揭示了几个关键优势:i)改进的视觉推理与LLMs:我们的详细、长上下文字幕可以直接整合到强大的LLMs中,以解决复杂的视觉推理问题,特别是对于像DeepSeek-R1 [13]系列这样的模型。这种方法使LLMs能够在无需额外微调的情况下以无训练的方式执行视觉推理任务,利用丰富的文本描述。ii)增强的图像生成和转换:我们框架生成的详细字幕显著提高了图像生成任务,如图像到文本生成和图像转换,这得益于其几乎完整的像素到文本映射能力。iii)高效的SFT过程:利用在OMNICAPTIONER上的预训练知识,SFT过程变得更加高效,需要更少的训练数据并实现更快的收敛。

图2:不同LLMs/MLLMs(7B)在或不带视觉输入的不同视觉基准测试上的性能比较。带有虚线边框的条形图表示Qwen2-VL-Instruct,表明它具有像素级视觉输入,而其他则没有。Qwen2-VL-Ins.(NA)指的是仅提供问题作为输入的设置。我们将MME分数除以100,以便与其他基准测试保持相同的尺度。

图3:展示OMNICAPTIONER插件式应用(子图a,b)及OMNICAPTIONER与LLava-OneVision-7B在非自然图像字幕生成上的对比(子图c)。子图(a)显示OMNICAPTIONER利用LLMs的强大推理能力执行多模态推理任务。子图(b)突出说明了由LLava-OneVision-7B生成的幻觉或不准确字幕可能导致不一致的图像转换,揭示了文本到图像模型中因字幕未能忠实表示原始内容而导致的对齐能力减弱。子图(c)强调由于在预训练期间对非自然图像的暴露有限,LLaVA-OneVision-7B在这些领域中的感知能力较弱,往往导致幻觉,而OMNICAPTIONER提供了更准确的描述。
此外,本文的贡献总结如下:
- 统一视觉字幕生成框架:我们提出了OMNICAPTIONER,一个用于生成跨领域字幕的统一框架。我们的方法无缝集成了自然图像、视觉文本图像(如海报、用户界面、教科书)和结构化视觉图像(如表格、图表、方程、几何图)的字幕生成能力。OMNICAPTIONER为广义视觉字幕设定了新标准,使视觉语言理解更加有效和可扩展。
-
- 全面的像素到文本转换:我们的框架利用详细字幕将低级像素信息转换为语义丰富、细致入微的文本描述,有效弥合了视觉和文本模态之间的差距。特别是,这通过提供更精确和上下文感知的文本指导增强了文本到图像生成,从而提高了视觉保真度和与预期语义的对齐。
-
- 提升视觉推理能力的LLMs:通过整合详细的长上下文字幕,我们的方法增强了视觉推理能力,特别是当与DeepSeek-R1系列等LLMs集成时。利用OMNICAPTIONER提供的感知信息,LLMs可以在文本空间内推断和推理,从而有效地解决视觉推理任务。
-
2 相关工作
图像字幕生成任务大致可分为两类。第一种方法专注于为自然图像生成高质量字幕。值得注意的是,ShareGPT4V [3] 通过收集高质量、属性特定的字幕,通过针对性提示向GPT-4V提供自然图像,改善了视觉语言对齐,而Densefusion [19] 等模型利用多个专家模型为自然图像合成字幕。第二种方法,如CompCap [5],通过在预训练过程中纳入合成图像来应对领域多样性挑战,从而提高在代表性不足领域中的表现。然而,第一种方法通常受限于特定领域,而第二种方法则因训练过程中使用的合成图像数量相对较少而面临挑战。
多模态大型语言模型。随着LLMs [44, 13, 37, 48]的发展,将视觉感知能力整合到LLMs中(即MLLMs)受到越来越多的关注。为了解决不同模态之间的差距,大多数工作[39, 2, 6, 42, 23, 18, 21, 22]首先在图像字幕数据上进行预训练,以获得视觉语言连接器(如基于MLP或交叉注意力的连接器),然后进行SFT。除了模型架构外,一些工作[40]试图通过后训练(如强化学习)[40]或测试时间缩放(如蒙特卡洛树搜索)[45, 28, 9]来提升模型的推理能力。此外,最近的研究[50, 31, 5, 7]系统地调查了数据质量对MLLMs预训练和SFT阶段的影响。MM1 [50]揭示了通过高质量数据预训练诱导的模型能力在SFT后得以有效保留。现有的大多数开源MLLMs [23, 18]主要关注自然图像的预训练,而领域特定的MLLMs(如数学、图表)则专门在领域特定字幕数据上进行训练。相比之下,我们提出了一种更统一的预训练方法,该方法在预训练过程中整合了多样化的领域知识。此外,当前的MLLMs通常表现出比纯文本LLMs较差的推理能力,而OMNICATIONER可以生成不同领域的详细长上下文字幕,并使用LLMs来解决具有挑战性的视觉推理任务。
3 OMNICATIONER
为了实现统一的多模态预训练范式并处理多样化的视觉领域,我们首先构建了一个多样化的字幕数据集,如第4节所述。我们将在第3.1节和第3.2节分别提供数据集描述和详细的数据集构建过程。相关过程在第3.3节中描述。
3.1 多样化视觉字幕数据集
我们视觉字幕数据集的多样性由两个维度表征:领域多样性(多样化数据源)和字幕公式多样性。为了实现有效的统一预训练,数据集需要涵盖更广泛的领域。例如,当作为文档助理时,MLLMs需要理解表格和图表,而作为GUI代理时,则需要理解网页中的元素。如图4的数据分布部分所示,我们的字幕数据集由四个主要类别组成:自然图像、结构化图像(包括图表、表格等)、视觉文本图像(包括UI图像、海报等)和视频。这种全面的数据覆盖使我们的模型能够作为多领域助理,并进一步增强下游任务的表现。此外,即使对于相同的视觉输入,可能也需要多样类型的字幕。例如,一张图表图像可能需要结构化的表格转换和综合分析描述。为满足这一需求,我们为每个领域定义了多样化的字幕公式。这种方法使我们的模型能够生成多样化的字幕格式,包括多语言(中文和英文)描述、不同粒度水平(从综合到简洁)等。
3.2 数据集构建
为了为跨领域图像生成高质量字幕,我们提出了一种两步字幕生成管道。我们的管道设计考虑了准确视觉
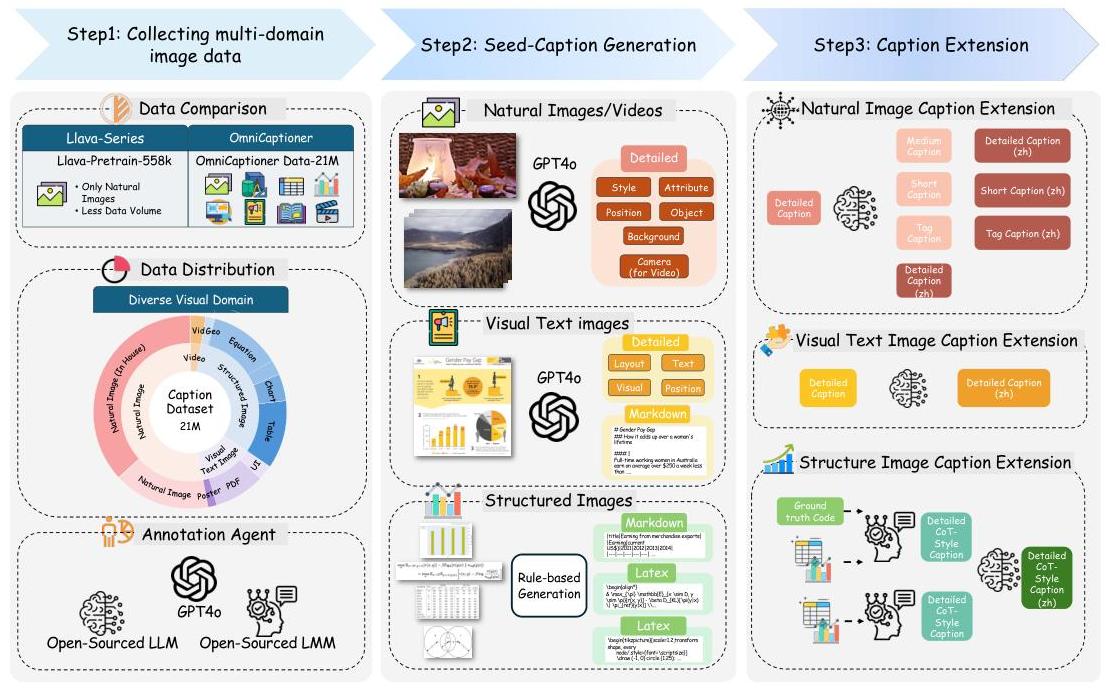
图4:OMNICAPTIONER的多样化视觉字幕生成管道。该管道由种子字幕生成确保精确的像素到词映射,以及字幕扩展以丰富字幕风格以支持图像生成和视觉推理任务。OMNICAPTIONER利用一个包含21M字幕的数据集,覆盖了超越自然图像的多样化领域,使更全面的字幕生成能力得以实现。有关数据集组成的更多详细信息,请参见附录A中的图7。
描述,支持不同风格输出的灵活性,执行推理和逻辑外推的能力,以及双语文本生成。
种子字幕生成。在第一阶段,我们专注于种子字幕生成。目标是生成尽可能准确的初始字幕,提供对所有相关视觉元素的全面文本描述。此阶段利用精心设计的提示引导强大的闭源多模态模型GPT-4o描述自然图像和视觉文本图像中的所有可能视觉元素,确保准确的像素到词映射。对于通过代码生成的结构化图像,使用预定义的代码规则尽可能准确地生成描述。生成的种子字幕为后续阶段的进一步细化提供了可靠的基础。
字幕扩展。第二阶段,字幕扩展负责增强和多样化生成的字幕。在这里,重点从纯粹的准确性转移到包含风格变化和领域特定推理。通过引入双语文本输出(中文和英文),从详细到中等长度、短小和标签风格的字幕范围变化,注入与特定领域相关的推理知识,丰富字幕的语义深度。这使得字幕不仅反映视觉内容,还能适应不同情境下的细微理解。特别地,对于自然图像,我们利用开源LLM Qwen2.5-32B通过不同的提示调整字幕长度,使字幕范围从中等到短小和标签风格。此外,这些多样化的字幕被翻译成中文,有助于为图像生成创建双语文本提示。对于视觉文本图像,我们使用开源LLM Qwen2.5-32B将GPT-4o生成的详细字幕翻译成相应的中文版本,以确保跨语言一致性。对于结构化图像,通常涉及数学或基于文档的推理(例如,链式思维(CoT)分析),我们优先考虑种子字幕的准确性。在确认种子字幕的准确性后,我们将种子字幕和原始图像输入开源多模态模型Qwen2-VL-76B以生成CoT风格的字幕。这种方法允许我们根据种子字幕的代码(例如,Markdown、LaTeX)和图像内容条件化字幕生成过程,减少幻觉并提高生成字幕的可靠性。此外,我们收集没有种子字幕的结构化图像,并直接将它们输入相同的多模态模型以生成CoT风格的字幕。通过将字幕生成过程分为这两个阶段,我们确保既能准确表示视觉内容,又能灵活生成适合上下文的多样化字幕。
3.3 统一预训练过程
为了有效处理涵盖广泛图像类型和字幕任务的OMNICAPTIONER数据集,我们提出了一种实用的方法,利用不同的系统提示。这些提示有助于最小化任务冲突并提高训练期间的任务协调。通过为特定图像类别定制系统提示,并为各种字幕样式使用固定的问题模板,我们区分预训练过程中的任务和数据类型。这种方法促进了多域训练的高效性,确保模型在多样化任务和领域中表现稳健。为应对处理分辨率差异大和任意宽高比的图像的挑战,我们利用Qwen2-VL-7B [39]模型的强大视觉理解能力。鉴于Qwen2-VL-Instruct模型在管理多域图像数据方面的固有能力,我们用Qwen2-VL-Instruct权重初始化我们的模型。这种初始化使我们能够有效地在Omnicaptioner数据集上进行微调,确保在广泛图像分辨率和宽高比范围内表现稳健,同时受益于模型在多样化领域中的泛化能力。
4 统领一切的单一字幕生成器
通过LLMs改进视觉推理任务。当前的MLLMs在推理能力上落后于LLMs。这种差异促使我们研究LLMs是否可以直接进行视觉推理,而无需可能导致推理能力下降的模态对齐损失,同时仍能有效处理多样化的视觉推理任务。在这项工作中,我们将图像字幕与大型语言模型(LLMs)集成,以实现在文本空间中的无缝视觉推理。如图3 (a)所示,首先,我们的字幕生成器将输入图像(涵盖自然图像、图表、方程式及其他)转换为语言密集型描述,明确编码像素级结构(如空间布局、符号运算符、表格层次结构)到文本空间。这些字幕作为无损语义代理,随后由强大的LLMs(如DeepSeek-R1 [13]、Qwen2.5系列 [44])直接处理,执行与任务无关的视觉推理,包括几何问题求解和空间分析。
正如图3所示,OmniCATIONER可以将几何图像转化为详细而精确的视觉描述。OmniCATIONER准确描述了几何图像,例如一个带有直径和圆周角的圆,详细描述了点之间的空间关系。这使得LLMs能够进行逻辑推理,如计算角度,而无需直接的像素级感知。
这种方法有三个关键优势:i)感知与推理分离 - 通过将感知(由MLLMs处理)与推理(由LLMs处理)分开,我们的方法避免了这两种能力之间的冲突,从而实现了更有效和准确的视觉推理。ii)消除模态对齐训练 - 我们的方法不是要求复杂的模态对齐损失,而是将视觉输入转换为语言表示,允许LLMs自然地处理它们。这消除了对额外多模态训练的需求,同时保留了LLMs的推理优势。iii)灵活性和泛化 - 即插即用的设计使LLMs能够无缝集成到多样化的视觉推理任务中,而无需领域特定的调整。这确保了不同类型视觉输入的广泛应用,从几何图到复杂的表格结构。
增强的图像生成和转换。详细而准确的图像字幕在文本到图像(T2I)任务的训练和推理阶段中起着至关重要的作用。在训练期间,此类字幕通过明确对齐低级/高级视觉模式(例如,纹理、空间排列、对象属性)与精确的语言语义提供细粒度监督。在推理时,如图3(b)所示,详细而精确的字幕通过指导模型更忠实地遵循指令——捕捉空间关系、对象交互和语义细节——显著提高图像生成质量。这些好处突显了字幕作为密集监督信号的关键作用,使T2I生成中更精确地遵循指令。
高效SFT过程。MLLMs的训练范式通常包括两个连续阶段:在图像-字幕数据上进行预训练,然后进行监督微调(SFT)。经验研究表明[5, 17, 31],多样化和高质量的图像-字幕数据(例如,复合图像)可以显著增强图像-语言对齐,并进而促进诸如视觉问答(VQA)等下游任务的表现。OmniCAPtionER在预训练阶段利用多样化和高质量的领域数据(例如,表格、图表等),使模型获取多领域知识。在SFT阶段,多领域知识为快速适应不同领域的下游任务提供了重要基础。
5 实验
为了评估OMniCAPtionER,我们进行了三项主要实验。第一个实验集中于使用插入字幕的大语言模型进行视觉推理。在此设置中,向LLM提供详细的字幕和相应的问题,并评估其回答问题的能力。我们使用五个基准数据集来评估该模型在此下游任务上的表现:MME [10]、Mathverse [52]、Mathvision [38]、MMMMU [49] 和奥林匹克基准 [14]。对于LLMs,我们选择了Qwen2.5-3B-Instruct [44]、Qwen2.5-7B-Instruct [44]、Qwen2.5-
表2:使用不同字幕生成器训练的模型在GenEval [12]上的性能比较(分辨率:
1024
×
1024
1024 \times 1024
1024×1024 )。
| 方法 | GenEval ↑ \uparrow ↑ | |||||
|---|---|---|---|---|---|---|
| 颜色属性 | 单个物体 | 位置 | 颜色 | 计数 | 总体 | |
| SANA-1.0-1.6B [43] | 38.50 | 98.75 | 21.25 | 86.70 | 65.31 \mathbf{6 5 . 3 1} 65.31 | 64.61 |
| SANA-1.0-1.6B + Qwen2-VL [39] | 44.29 | 98.44 | 26.64 | 86.97 \mathbf{8 6 . 9 7} 86.97 | 57.81 | 65.27 |
| SANA-1.0-1.6B + OMniCAPPionER | 46.00 \mathbf{4 6 . 0 0} 46.00 | 99.06 \mathbf{9 9 . 0 6} 99.06 | 29.50 \mathbf{2 9 . 5 0} 29.50 | 84.57 | 64.06 | 67.58 \mathbf{6 7 . 5 8} 67.58 |
32B-Instruct [44],DeepSeek-R1-Distill-Qwen-7B [13],DeepSeek-R1-Distill-Qwen-32B [13],和DeepSeek-R1-Distill-LLaMA-70B [13],这些都因其强大的推理能力而被选中。第二个实验评估了SFT过程的效率。为此,我们选择来自OV阶段的LLaVAOneVision [18]数据,带有链式思考增强功能,以评估OMniCAPPionER在多个常用基准测试[10, 49, 29, 30, 38, 52, 25]中的SFT版本。第三个实验涉及使用由不同字幕生成器(即Qwen2-VL [39],OMniCAPPionER)生成的图像-字幕对微调文本到图像生成模型[SANA-1.0-1.6B [43]]。训练设置使用分辨率为 1024 × 1024 1024 \times 1024 1024×1024。然后在GenEval [12]上评估模型的生成性能。
5.1 主要结果
通过LLMs改进视觉推理。我们的实验结果表明,将字幕集成到推理增强的大语言模型(LLMs)中,无需任何额外的微调,即可在多个推理基准测试中实现最先进的性能,包括MathVision [38]、MathVerse [52]、MMMMU [49] 和奥林匹克基准 [14]。这突显了OMniCAPPionER在提升多种视觉任务推理能力方面的强大作用。具体来说,OMNiCAPPIONER插入的LLMs在多个模型尺寸的MathVision上显著优于现有模型,强调了复杂视觉和数学任务推理能力的提升。值得注意的是,OmniCaptioner + DS-R1-Distill-Qwen-7B和OmniCaptioner + DS-Distill-Qwen
32
B
32 B
32B在MathVerse基准测试中表现出色,显著优于以前的模型。这些结果进一步验证了基于字幕的预训练在弥合LLM对视觉几何内容理解的桥梁中的有效性。在MMMMU基准测试中,OmniCaptioner + DS-R1-Distill-Qwen-72B接近Qwen2-VL-72B的性能,两者之间的差距很小。这一结果强有力地证明了将字幕与推理增强的LLMs集成可以显著提升多学科内容的视觉理解和推理能力。
成功将字幕与规模从3B到72B的LLMs集成,强调了OMniCAPPionER在视觉任务中持续增强LLMs推理能力的一致性,无论模型大小如何都有所改进。这些结果表明,我们的统一预训练方法,利用大规模字幕数据,是一种非常有效的策略,可以在多种任务中推进视觉推理,甚至超越现有的大规模微调方法。
增强的图像生成。如表2所示,为了验证字幕准确性在T2I生成中的重要性,我们的模型在GenEval基准测试中显著优于Qwen2-VL-Instruct [39]字幕和原始SANA。原始SANA模型在GenEval上的整体得分为64.61,使用Qwen2-VL-Instruct后显著提高到65.27,再使用OMniCAPPionER后进一步提高到67.58。与原始SANA模型相比,+2.97的绝对增益突显了高质量字幕在指导T2I生成中的有效性。此外,我们的OMniCAPPionER在各个方面(颜色除外)均优于Qwen2-VL-Instruct,展示了我们字幕生成的增强准确性。
高效的SFT。在表3中,我们比较了几种模型在视觉感知和推理任务上的性能,包括LLaVA-OV-7B(SI),LLaVA-OV-7B,Qwen2-VL-base+OV SFT,以及我们提出的OmniCaptioner+OV SFT模型。虽然LLaVA-OV-7B (SI)和LLaVA-OV-7B在SFT中使用了显著更大的数据集——分别为3.2 M和4.8 M样本,但我们的OmniCaptioner+OV SFT仅使用1.6 M SFT样本在单视图(OV)阶段就达到了可比的结果。关键区别在于OMniCAPtionER的统一预训练阶段,在SFT阶段前利用了基于多样字幕的数据集。这一步骤使模型具备了更丰富的领域知识,使其在视觉指令跟随任务中表现优异,尽管SFT样本较少。
表3:在多样化评估基准上的SFT性能比较。OmniCaptioner + OV SFT表示基于OMniCaptioner的SFT模型,而Qwen2-VL-base + OV SFT基于Qwen2-VL-Base。LLaVA-OV-7B (SI)代表LLaVA-OneVision [18]中单图像训练后的模型。
| SFT模型 | 数据 | MME | MMMU | MathVerse | MathVista | DocVQA | ChartQA |
|---|---|---|---|---|---|---|---|
| LLaVA-OV-7B (SI) [18] | 3.2 M | 2109 | 47.3 | 26.9 | 56.1 | 89.3 / 86.9 89.3 / 86.9 89.3/86.9 | 78.8 |
| LLaVA-OV-7B [18] | 4.8 M | 1998 | 48.8 | 26.2 | 63.2 | 90.2 / 87.5 90.2 / 87.5 90.2/87.5 | 80.0 |
| Qwen2-VL-Base+OV SFT | 1.6 M | 1905 | 44.4 | 24.9 | 53.8 | 84.2 / − 84.2 /- 84.2/− | 53.5 |
| OMNICEPTIONER+OV SFT | 1.6 M | 2045 | 46.6 | 25.8 | 57.4 | 91.2 / − 91.2 /- 91.2/− | 79.0 |
表4:通过实验比较不同字幕生成器在多个视觉基准测试上的表现。
| 字幕生成器选择 | LLM | MME | MMMU | MathVision | MathVerse |
|---|---|---|---|---|---|
| Ilava-onevision-qwen2-7b-ov | DS-R1-Distill-Qwen-7B | 1646 | 22.4 | 31.7 | 36.6 |
| InternVL2-8B | DS-R1-Distill-Qwen-7B | 1789 | 23.1 | 34.4 | 39.9 |
| Qwen2-VL-7B-Instruct | DS-R1-Distill-Qwen-7B | 1914 | 42.4 | 31.6 | 33.0 |
| OMNICEPTIONER(我们的) | DS-R1-Distill-Qwen-7B | 1942 \mathbf{1 9 4 2} 1942 | 47.5 \mathbf{4 7 . 5} 47.5 | 36.2 \mathbf{3 6 . 2} 36.2 | 40.5 \mathbf{4 0 . 5} 40.5 |
样本较少的情况。这也表明Qwen2-VL-base + SFT落后于OmniCaptioner + OV SFT,显示出OMNICEPTIONER卓越的视觉感知能力。
5.2 讨论与发现
我们在结合OMniCApTIONER与推理增强LLMs时考虑进行三项重要实验。首先,我们使用不同版本的Qwen进行有效性评估。其次,我们旨在探索Qwen2-VL-Instruct(无图像输入)和主流推理增强LLMs在多大程度上依赖视觉模态信息来解决视觉推理任务。第三,我们通过修改提供给推理增强LLMs的字幕来比较OMniCApTIONER与Qwen2-VL-Instruct。有关图像字幕、视频字幕和文本到图像生成任务的更多可视化结果,请参阅附录D和附录E。
不同Qwen家族版本的影响。图5展示了结合OmniCApTIONER与不同版本Qwen在MMMU和MathVerse上的性能进展。随着Qwen从Qwen1-8B-chat进化到Qwen2.5-7B-Instruct,视觉推理能力稳步提升,这得益于OmniCApTIONER的像素到字幕生成能力。如图2所示,OmniCaptioner + Qwen2.5-7B-Base、OmniCaptioner + Qwen2.5-7B-Instruct和OmniCaptioner + DS-R1-Distill-Qwen-7B之间的性能比较突显了整合DeepSeek Distilled Qwen2.5的优势,该版本在数学推理方面表现出色。蒸馏变体(DS-R1-Distill-Qwen-7B)在MME(1942)、
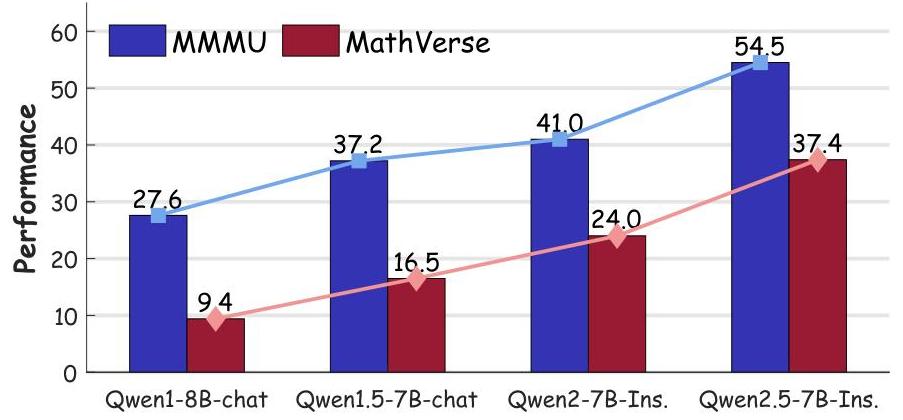
图5:将OMniCApTIONER集成到不同版本的LLMs中,使它们能够处理多模态场景中的任务。
MathVision (36.2) 和 MathVerse (40.5) 中实现了最高精度,强调了蒸馏推理能力的好处。相比之下,Qwen2.5-7B-Instruct更适合一般世界知识任务,这在其在
M
M
M
U
\boldsymbol{M M M U}
MMMU (54.5)上的改进表现中得到了体现。
视觉模态对推理增强LLMs的影响。从图2可以看出,Qwen2-VL-7B (NA) 和 DeepSeek-Distill-Qwen-7B 的表现表明,缺乏图像输入会显著限制它们解决视觉推理任务的能力。相比之下,保留视觉模态的 OmniCaptioner + DS-R1-Distill-Qwen-7B 显著高于无视觉输入的LLM,突显了视觉信息在增强推理能力中的关键作用。此外,非视觉输入LLM DS-R1-Distilled-Qwen-7B在MathVision和MathVerse上显著优于无图像的MLLM(即Qwen2-VL-Instruct-7B),展示了R1 Serious模型的优越推理能力。
不同字幕生成器的影响。表4对不同字幕生成器在多个感知和推理基准上的表现进行了比较分析。我们的模型结合DeepSeek-Distill-Qwen2.57B,在所有评估任务中均表现出色,显著优于先前的方法。这些结果突显了OMNICAPTIONER的有效性,其字幕提供了比Qwen2-VL-7B-Instruct生成的字幕更精确和上下文准确的描述。字幕质量的提升有助于改进视觉推理任务,特别是在需要多步推理和详细视觉理解的任务中。
6 结论
我们介绍了OMNICAPTIONER,这是一种统一的框架,通过跨多样化领域(包括自然图像、视觉文本图像和结构化图像)的精细像素到文本映射来弥合视觉和文本模态之间的差距。通过将低级视觉模式转换为语义丰富的字幕,我们的方法赋予了推理增强的LLMs(如DeepSeek-R1)增强的视觉推理能力,并通过全面的语义保存实现了精确的文本到图像生成。这项工作开创了一种可扩展的多模态对齐和推理范式,无需昂贵的标签监督微调即可实现视觉语言的无缝互操作性。
致谢
本研究得到上海人工智能实验室、上海市市级科技重大项目和上海市启明星计划(资助编号:23QD1401000)的支持。
参考文献
[1] Anas Awadalla, Le Xue, Manli Shu, An Yan, Jun Wang, Senthil Purushwalkam, Sheng Shen, Hannah Lee, Oscar Lo, Jae Sung Park, et al. Blip3-kale: Knowledge augmented large-scale dense captions. arXiv preprint arXiv:2411.07461, 2024.
[2] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923, 2025.
[3] Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. In European Conference on Computer Vision, pages 370-387. Springer, 2024.
[4] Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, et al. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13320-13331, 2024.
[5] Xiaohui Chen, Satya Narayan Shukla, Mahmoud Azab, Aashu Singh, Qifan Wang, David Yang, ShengYun Peng, Hanchao Yu, Shen Yan, Xuewen Zhang, et al. Compcap: Improving multimodal large language models with composite captions. arXiv preprint arXiv:2412.05243, 2024.
[6] Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. Science China Information Sciences, 67(12):220101, 2024.
[7] Xueqing Deng, Qihang Yu, Ali Athar, Chenglin Yang, Linjie Yang, Xiaojie Jin, Xiaohui Shen, and Liang-Chieh Chen. Coconut-pancap: Joint panoptic segmentation and grounded captions for fine-grained understanding and generation. arXiv preprint arXiv:2502.02589, 2025.
[8] Haiwen Diao, Yufeng Cui, Xiaotong Li, Yueze Wang, Huchuan Lu, and Xinlong Wang. Unveiling encoder-free vision-language models. arXiv preprint arXiv:2406.11832, 2024.
[9] 段冠亭. 揭示无编码器的视觉语言模型. arXiv预印本 arXiv:2406.11832, 2024.
[10] 福朝友, 陈培贤, 沈云航, 秦玉涛, 张梦丹, 林旭, 杨金瑞, 郑晓武, 李科, 孙兴, 等. MME:多模态大型语言模型的全面评估基准. arXiv预印本 arXiv:2306.13394, 2023.
[11] 高鹏, 卓乐, 刘东洋, 杜若仪, 罗旭, 邱龙田, 张宇航, 林辰, 黄荣杰, 龚世杰, 等. Lumina-T2X:通过基于流的大扩散变压器将文本转换为任何模态、分辨率和持续时间. arXiv预印本 arXiv:2405.05945, 2024.
[12] 荷什·高什, 汉纳内·哈吉什里尔齐, 和路德维希·施密特. Geneval:一个专注于文本到图像对齐评估的框架. 神经信息处理系统进展, 36:52132-52152, 2023.
[13] 郭大雅, 杨德健, 张浩伟, 宋军晓, 张若宇, 徐润新, 朱启豪, 马世荣, 王佩一, 毕肖, 等. Deepseek-R1:通过强化学习激励LLM推理能力. arXiv预印本 arXiv:2501.12948, 2025.
[14] 何超群, 罗仁杰, 白玉卓, 胡盛鼎, 泰国梁震, 沈俊浩, 胡锦怡, 韩旭, 黄玉洁, 张宇翔, 等. Olympiadbench:通过奥林匹克级别双语多模态科学问题促进AGI的具有挑战性的基准测试. arXiv预印本 arXiv:2402.14008, 2024.
[15] 胡安文, 许海阳, 叶佳波, 严明, 张良, 张博, 李晨, 张霁, 金秦, 黄飞, 等. mplug-docowl 1.5:统一结构学习用于OCT自由文档理解. arXiv预印本 arXiv:2403.12895, 2024.
[16] 黄子涵, 武涛, 林王, 张圣雨, 陈敬源, 吴飞. AutoGeo:自动化几何图像数据集创建以增强几何理解. arXiv预印本 arXiv:2409.09039, 2024.
[17] 蒋东智, 张仁睿, 郭子羽, 李彦伟, 戚宇, 陈欣言, 王柳辉, 金建汉, 郭克莱, 燕申, 等. MME-COT:在大型多模态模型中基准链式思维的质量、稳健性和效率. arXiv预印本 arXiv:2502.09621, 2025.
[18] 李博, 张元翰, 郭东, 张仁睿, 李峰, 张昊, 张凯臣, 张培远, 李岩, 刘自威, 等. LLaVA-OneVision:轻松实现视觉任务迁移. arXiv预印本 arXiv:2408.03326, 2024.
[19] 李晓通, 张凡, 迪奥海文, 王越泽, 王新龙, 段凌玉. DenseFusion-1M:合并视觉专家以实现全面的多模态感知. arXiv预印本 arXiv:2407.08303, 2024.
[20] 林曦维多利亚, 施里瓦斯塔瓦阿克沙特, 罗亮, 艾耶尔斯里尼瓦桑, 刘易斯迈克, 戈什加尔吉, 泽特勒莫伊, 阿加贾尼扬阿尔门. MoMA:具有模态感知专家混合的高效早期融合预训练. arXiv预印本 arXiv:2407.21770, 2024.
[21] 林子逸, 刘克里斯, 张仁睿, 高鹏, 邱龙天, 肖晗, 邱韩, 林辰, 邵文琪, 陈可勤, 等. Sphinx:多模态大型语言模型的权重、任务和视觉嵌入联合混合. arXiv预印本 arXiv:2311.07575, 2023.
[22] 刘东阳, 张仁睿, 邱龙天, 黄思远, 林卫锋, 赵世天, 耿世杰, 林子逸, 高鹏, 张凯鹏, 等. Sphinx-X:扩展数据和参数以支持多模态大型语言模型家族. arXiv预印本 arXiv:2402.05935, 2024.
[23] 刘昊天, 李春园, 吴庆阳, 李永杰. 视觉指令微调. 神经信息处理系统进展, 36:34892-34916, 2023.
[24] 刘俊鹏, 欧天岳, 宋一帆, 屈宇潇, 林伟, 熊川燕, 翁天悦, 陈文虎, 内布吉格拉厄姆, 夏月. 利用网页UI进行文本丰富的视觉理解. arXiv预印本 arXiv:2410.13824, 2024.
[25] 卢潘, Bansal赫里特克, Xia托尼, 刘继成, 李春园, Hajishirzi汉纳内, Cheng郝, Chang凯韦, Galley米歇尔, 高剑锋. MathVista:评估基础模型在视觉环境中的数学推理能力. arXiv预印本 arXiv:2310.02255, 2023.
[26] 罗楚玮, 沈玉凡, 朱昭庆, 郑奇, 余志, 姚聪. LayoutLLM:使用大规模语言模型进行文档理解的布局指令调整. 在IEEE/CVF计算机视觉与模式识别会议论文集, 第15630-15640页, 2024.
[27] 罗根, 杨雪, 杜文瀚, 王兆凯, 戴纪峰, 乔宇, 周锡周. Mono-InternVL:通过内源性视觉预训练推动单片多模态大语言模型的边界. arXiv预印本 arXiv:2410.08202, 2024.
[28] 罗瑞林, 郑 Zhuofan, 王一帆, 于奕瑶, 倪辛哲, 林子诚, 曾锦, 杨宇久. Ursa:理解和验证多模态数学中的链式思维推理. arXiv预印本 arXiv:2501.04686, 2025.
[29] Masry艾哈迈德, Long杜玄, Tan庆青, Joty沙菲克, Hoque恩纳穆. ChartQA:包含视觉和逻辑推理的图表问答基准. arXiv预印本 arXiv:2203.10244, 2022.
[30] Mathew迈尼斯, Karatzas迪莫斯滕尼斯, Jawahar CV. DocVQA:文档图像上的视觉问答数据集. 在IEEE/CVF冬季计算机视觉应用会议论文集, 第2200-2209页, 2021.
[31] McKinzie布兰登, Gan哲, Fauconnier让-菲利普, Dodge萨姆, Zhang Bowen, Dufter Philipp, Shah Dhruti, 杜先枝, 彭付堂, Belyi安东, 等. MM1:多模态LLM预训练的方法、分析和见解. 在欧洲计算机视觉会议论文集, 第304-323页. Springer, 2024.
[32] 南keptan, 谢锐林, 周鹏昊, 范铁涵, 杨振恒, 陈志杰, 李翔, 杨健, 台颖. OpenVid-1M:一个大规模高质量的文本到视频生成数据集. arXiv预印本 arXiv:2407.02371, 2024.
[33] 彭天硕, 李明生, 周红斌, 夏任秋, 张仁睿, 白雷, 毛松, 王彬, 何聪慧, 周傲军, 等. Chimera:通过领域特定专家改进通用模型. arXiv预印本 arXiv:2412.05983, 2024.
[34] 秦琦, 卓乐, 辛毅, 杜若仪, 李真, 傅斌, 吕一婷, 袁嘉康, 李新月, 刘东阳, 等. Lumina-Image 2.0:一个统一且高效的图像生成框架. arXiv预印本 arXiv:2503.21758, 2025.
[35] Chameleon团队. Chameleon:混合模态早期融合基础模型. arXiv预印本 arXiv:2405.09818, 2024.
[36] 童胜邦, 布朗埃利斯, 吴鹏浩, Woo Sanghyun, Middepogu Manoj, Akula Sai Charitha, 杨季汉, 杨淑胜, Iyer阿迪斯, 潘锡哲, 等. Cambrian-1:一个多模态LLM的完全开放、以视觉为中心的探索. arXiv预印本 arXiv:2406.16860, 2024.
[37] Hugo Touvron, Martin路易斯, Stone凯文, Albert彼得, Almahairi阿姆贾德, Babaei亚斯敏, Bashlykov尼古拉, Batra苏米娅, Bhargava帕拉吉, Bhosale舒鲁蒂, 等. Llama 2:开源的基础和微调聊天模型. arXiv预印本 arXiv:2307.09288, 2023.
[38] 王柯, 潘军挺, 施伟康, 卢子木, 战明杰, 李洪升. 使用Math-Vision数据集测量多模态数学推理. arXiv预印本 arXiv:2402.14804, 2024.
[39] 王鹏, 白帅, 谭思南, 王世杰, 范志豪, 白金泽, 陈克勤, 刘学晶, 王家林, 靳文斌, 等. Qwen2-VL:在任意分辨率下增强视觉语言模型的世界感知. arXiv预印本 arXiv:2409.12191, 2024.
[40] 王维云, 陈哲, 王文海, 曹越, 刘洋洲, 高张伟, 朱金国, 朱锡舟, 鹿刘伟, 乔宇, 等. 通过混合偏好优化增强多模态大语言模型的推理能力. arXiv预印本 arXiv:2411.10442, 2024.
[41] 夏任秋, 李明生, 叶汉城, 吴文杰, 周红斌, 袁嘉康, 彭天硕, 蔡鑫宇, 严祥超, 王彬, 等. GeoX:通过统一形式化的视觉语言预训练解决几何问题. arXiv预印本 arXiv:2412.11863, 2024.
[42] 夏任秋, 张博, 叶汉城, 严祥超, 刘琦, 周宏斌, 陈子君, 杜敏, 石波特, 闫俊驰, 等. ChartX & ChartVLM:复杂的图表推理多功能基准和基础模型. arXiv预印本 arXiv:2402.12185, 2024.
[43] 谢恩泽, 陈军松, 陈军禹, 蔡汉, 唐浩天, 林宇骏, 张则凯, 李睦阳, 朱立庚, 卢姚, 等. SANA:使用线性扩散变压器高效高分辨率文本到图像合成. 在第十三届国际学习表示会议论文集, 2025.
[44] 杨昂, 杨宝松, 张北宸, 惠斌远, 郑波, 余博文, 李成远, 刘大义亨, 黄飞, 魏浩然, 等. Qwen2.5技术报告. arXiv预印本 arXiv:2412.15115, 2024.
[45] 姚欢金, 黄家兴, 吴文豪, 张景毅, 王一博, 刘顺雨, 王颖杰, 宋煜欣, 冯浩程, 沈黎, 等. Mulberry:通过集体蒙特卡洛树搜索赋予MLLM类似O1的推理和反思能力. arXiv预印本 arXiv:2412.18319, 2024.
[46] 姚元, 余天宇, 张敖, 王崇义, 崔俊博, 朱宏基, 蔡天池, 李浩宇, 赵伟林, 何志辉, 等. MiniCPM-V:您手机上的GPT-4V级多模态LLM. arXiv预印本 arXiv:2408.01800, 2024.
[47] 姚元, 余天宇, 张敖, 王崇义, 崔俊博, 朱宏基, 蔡天池, 李浩宇, 赵伟林, 何志辉, 等. MiniCPM-V:您手机上的GPT-4V级多模态LLM. arXiv预印本 arXiv:2408.01800, 2024.
[48] 袁家康, 颜祥超, 石博天, 陈涛, 赵万里, 张博, 白雷, 乔宇, 周博文. Dolphin:通过思考、实践和反馈实现闭环开放式自动研究. arXiv预印本 arXiv:2501.03916, 2025.
[49] 岳翔, 倪元生, 张凯, 郑天宇, 刘若琪, 张戈, Stevens塞缪尔, 江东福, 任魏明, 任宇轩, 等. MMMU:专家AGI的多学科多模态理解和推理大规模基准. 在IEEE/CVF计算机视觉和模式识别会议论文集, 第9556-9567页, 2024.
[50] 张浩天, 高明非, 甘哲, Dufter菲利普, 温泽尔尼娜, 黄福斯特, Shah德鲁蒂, 杜显志, 张博文, 李阳浩, 等. MM1.5:多模态LLM微调的方法、分析和见解. arXiv预印本 arXiv:2409.20566, 2024.
[51] 张亮, 胡安然, 许海阳, 严明, 徐一辰, 晋秦, 张霁, 黄飞. TinyChart:通过视觉标记合并和程序化思维学习实现高效的图表理解. arXiv预印本 arXiv:2404.16635, 2024.
[52] 张仁睿, 江冬志, 张义池, 林皓坤, 邱鹏硕, 周傲军, 卢盘, 常凯韦, 张彬, 等. MathVerse:您的多模态LLM是否真正看到了视觉数学问题中的图表?在欧洲计算机视觉会议论文集, 第169-186页. Springer, 2024.
[53] 张仁睿, 魏昕宇, 江冬志, 郭子羽, 李士诚, 张义池, 童成珠, 刘佳铭, 周傲军, 魏斌, 等. MAVIS:通过自动数据引擎进行数学视觉指令微调. arXiv预印本 arXiv:2407.08739, 2024.
[54] 张珊, 陈奥天, 孙彦鹏, Gu金东, Zheng Yi-Yu, Koniusz皮奥特, 周凯, van den Hengel安东, 薛远. 打开眼睛,然后推理:在MLLMs中进行细粒度视觉数学理解. arXiv预印本 arXiv:2501.06430, 2025.
[55] 郑明宇, 冯心伟, 思清一, 她桥桥, 林政霖, 蒋文浩, 王卫平. 多模态表格理解. arXiv预印本 arXiv:2406.08100, 2024.
A OmniCaptioner 数据集组成
如图7所示,OMNICAPTIONER数据集是一个大规模的多模态基准测试,包括图像、表格、图表、数学几何/方程、海报、PDF、用户界面元素和视频,字幕同时提供英文和中文。数据集包括来自内部收集、BLIP3Kale [1] 和 DenseFusion [19] 的自然图像。表格数据从arXiv网站和开源MMTab数据集 [55] 收集,而图表数据来源于arXiv网站和TinyChart [51]。数学内容,包括方程和几何结构,源自arXiv并从数据集如MAVIS [53] 和AutoGeo [16] 中生成。UI数据来自MultiUI数据集 [24],而海报图像包含OCR字幕。视频字幕来源于OpenVid [32] 和Panda [4],涵盖多种属性,如详细描述、风格、背景、标签、摄像角度和物体信息。图6展示了与自然图像相关的不同类型字幕的令牌长度分布,分类为详细、中等、简短和标签字幕。
B 实验设置
我们在大规模字幕数据集上微调Qwen2-VL-7B-Instruct模型,使用64个A100 GPU。训练过程通过torchrun分布式进行,并采用DeepSpeed ZeRO-3优化策略。
超参数:
- 批量大小:256(每设备1个,梯度累积8次)
-
- 学习率:1e-5(基础模型),1e-5(合并模块),2e-6(视觉塔)
-
- 权重衰减:0.0
-
- 预热比例:3%
-
- 调度器:余弦衰减
-
- 精度:启用BF16
-
- 梯度检查点:启用
训练细节:
- 图像分辨率:从 2 × 28 × 28 \mathbf{2} \times \mathbf{2 8} \times \mathbf{2 8} 2×28×28到 6400 × 28 × 28 \mathbf{6 4 0 0} \times \mathbf{2 8} \times \mathbf{2 8} 6400×28×28像素
-
- 轮数:1
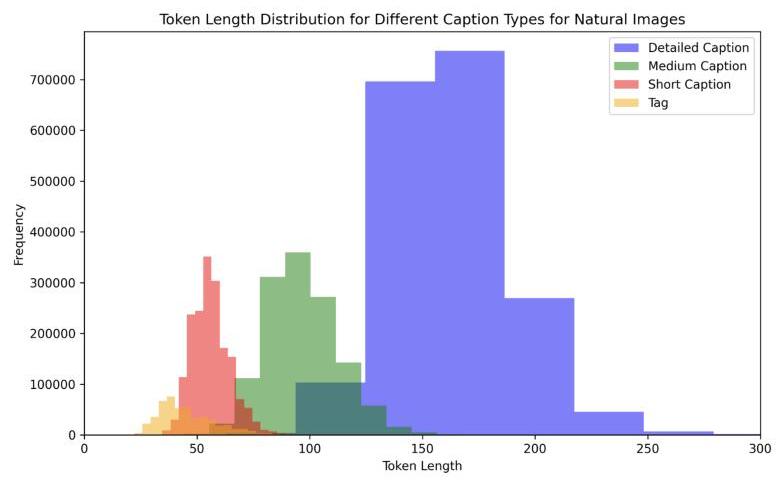
图6:自然图像的令牌长度分布。
C 系统提示示例
图8展示了OMniCAPPioner中用于各种图像类型的不同的系统提示。这些提示分为三部分:自然图像、视觉文本图像和结构化图像。这些提示引导模型的字幕生成风格和特定任务适应。
| 自然图像(数据来源:内部) | |||
|---|---|---|---|
| Detailed_en (1.9M) | □ \square □ Detailed_zh (1.9M) | □ \square □ Medium_en (650K) | |
| □ \square □ Medium_zh (642K) | □ \square □ Short_en (350K) | □ \square □ Short_zh (324K) | |
| □ \square □ Tag_en (200K) | □ \square □ Tag_zh (169K) | ||
| 自然图像(数据来源:内部) | |||
| □ \square □ Detailed_en (55K) | □ \square □ Detailed_zh (132K) | □ \square □ Medium_en (483K) | |
| □ \square □ Medium_zh (465K) | □ \square □ Short_en (1.6M) | □ \square □ Short_zh (1.3M) | |
| 自然图像(数据来源:内部) | |||
| □ \square □ Detailed_en (432K) | □ \square □ Detailed_zh (348K) | □ \square □ Medium_en (19K) | |
| □ \square □ Medium_zh (13K) | □ \square □ Short_en (1K) | □ \square □ Short_zh (2k) | |
| 表格(数据来源:arXiv: MMeab) | |||
| To LaTeX(2.8M) | □ \square □ Detailed_en (168K) | □ \square □ Detailed_zh (34K) | |
| 图表(数据来源:arXiv: Tayscript) | |||
| To Markdown (767K) | □ \square □ Detailed_en (253K) | □ \square □ Detailed_zh (79K) | |
| 数学方程(数据来源:arXiv) | |||
| To LaTeX (3M) | □ \square □ Detailed_en (382K) | □ \square □ Detailed_zh (141K) | |
| 模型国家(数据来源:次国家级 | 手动次国家级 | ||
| To LaTeX (102K) | □ \square □ Detailed_en (300K) | ||
| 海报(数据来源:内部) | |||
| OCR (82K) | □ \square □ Detailed_en (134K) | □ \square □ Detailed_zh (98K) | |
| PDF和LET | |||
| UI Caption (709K) | □ \square □ PDF OCR (47K) | □ \square □ Pure Text OCR (2M) | |
| Xblort(数据来源:金融服务) | |||
| □ \square □ Detailed_en (600K) | □ \square □ Tag (600K) | □ \square □ Main Object (600K) | |
| Style (600K) | □ \square □ Medium (600K) | □ \square □ Short (600K) | |
| Background (600K) | □ \square □ Camera (600K) |
图7:预训练OMniCAPPIONER的数据集组成。
D 字幕可视化
如图9至图15所示,我们使用OMniCAPPioner展示了多个任务中的字幕生成结果,包括自然图像、表格图像、图表图像、数学图像、海报图像和视频。对于自然图像,我们展示了不同系统提示对字幕生成的影响,展示特定提示如何在模型响应中引出世界知识,见图16。在结构化图像的情况下(见图17),不同的系统提示导致字幕生成的风格变化,反映了模型对各种格式要求的适应性。此外,我们在图18、图19和图20中展示了如何通过OMniCAPPioner生成的字幕增强DeepSeek-R1-Distill-LLaMA-70B,使其更有效地处理视觉任务。这些可视化突出了OMniCAPPioner在处理多样化多模态数据时的多样性和稳健性,展示了其改善视觉语言理解的潜力。
E 文本到图像生成
图21的可视化显示,OMNICATIONER的详细字幕显著增强了SANA 1.0 [43]模型中的文本到图像(T2I)对齐能力。通过提供精确且描述丰富的文本字幕,生成的图像表现出更高的保真度,准确反映原始提示的概念、属性和关系。上述所有生成图像均由经过OMNICATIONER标注的图像数据训练的生成模型生成,该模型使用具有1.6B参数的SANA 1.0进行了微调。
自然图像的系统提示:
Tertel
名词一个有用的助手,专注于提供详细的描述和背景信息给一般的摩。分析给定的摩并生成一个综合字幕,包括视觉风格、元素之间的空间关系、纹理细节、主要对象的描述以及相关的世界知识以增强理解。
‘中位数’
名词一个有用的专门制作中等长度字幕的助手。分析提供的摩并生成一个捕捉关键视觉元素的字幕,同时保持清晰和连贯。
‘简短’
名词一个专注于为生成的摩创建简短字幕的助手。分析提供的摩并生成一个突出主要主题的简洁字幕。
‘标签’
名词一个专注于为生成的摩生成关键标签的助手。分析提供的摩并创建一个捕捉主要对象、框架和动作元素的相关标签列表。
Tertelvol_2b’

图8:OMNICATIONER使用的不同系统提示。
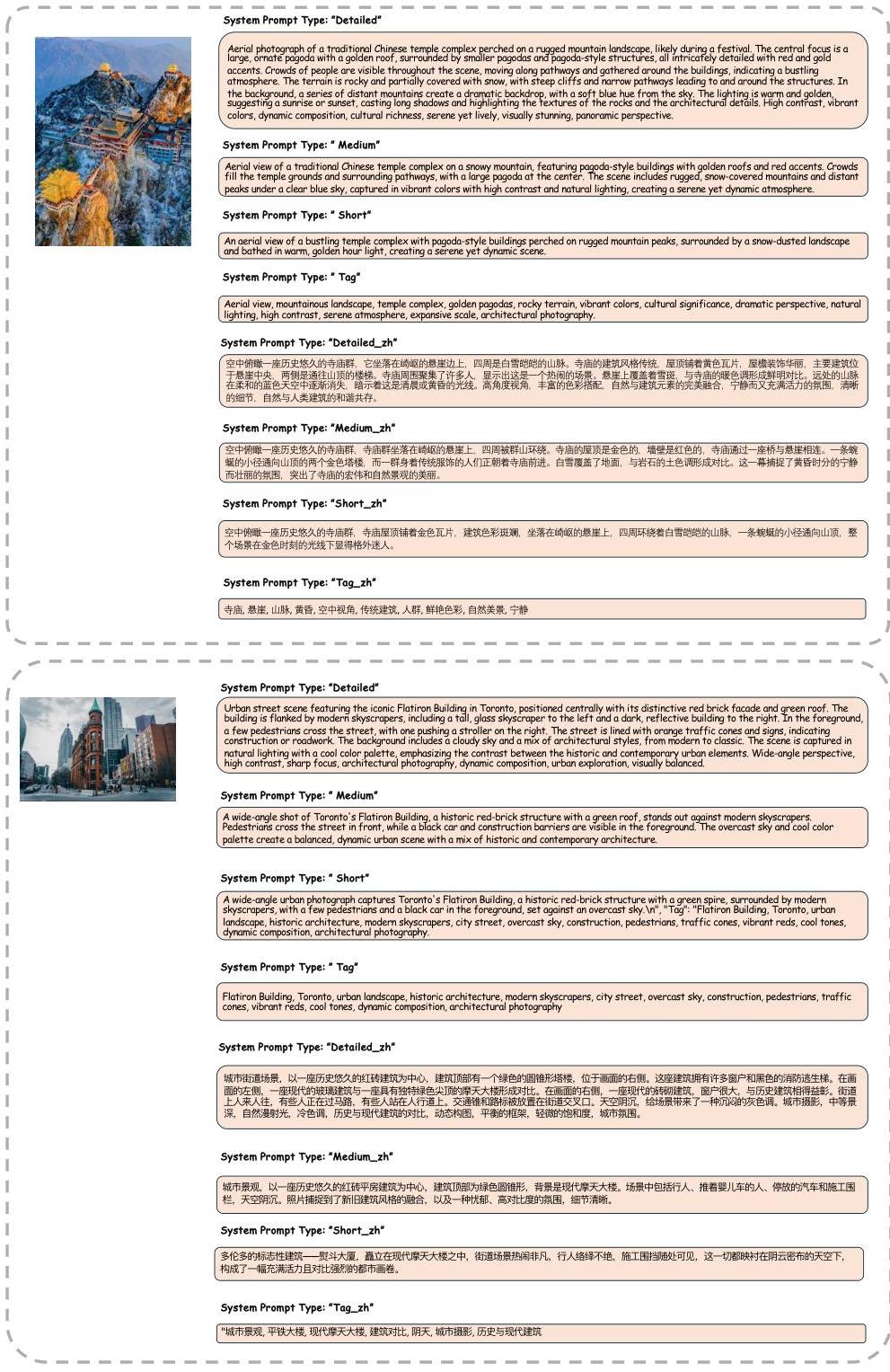
图9:自然图像字幕。
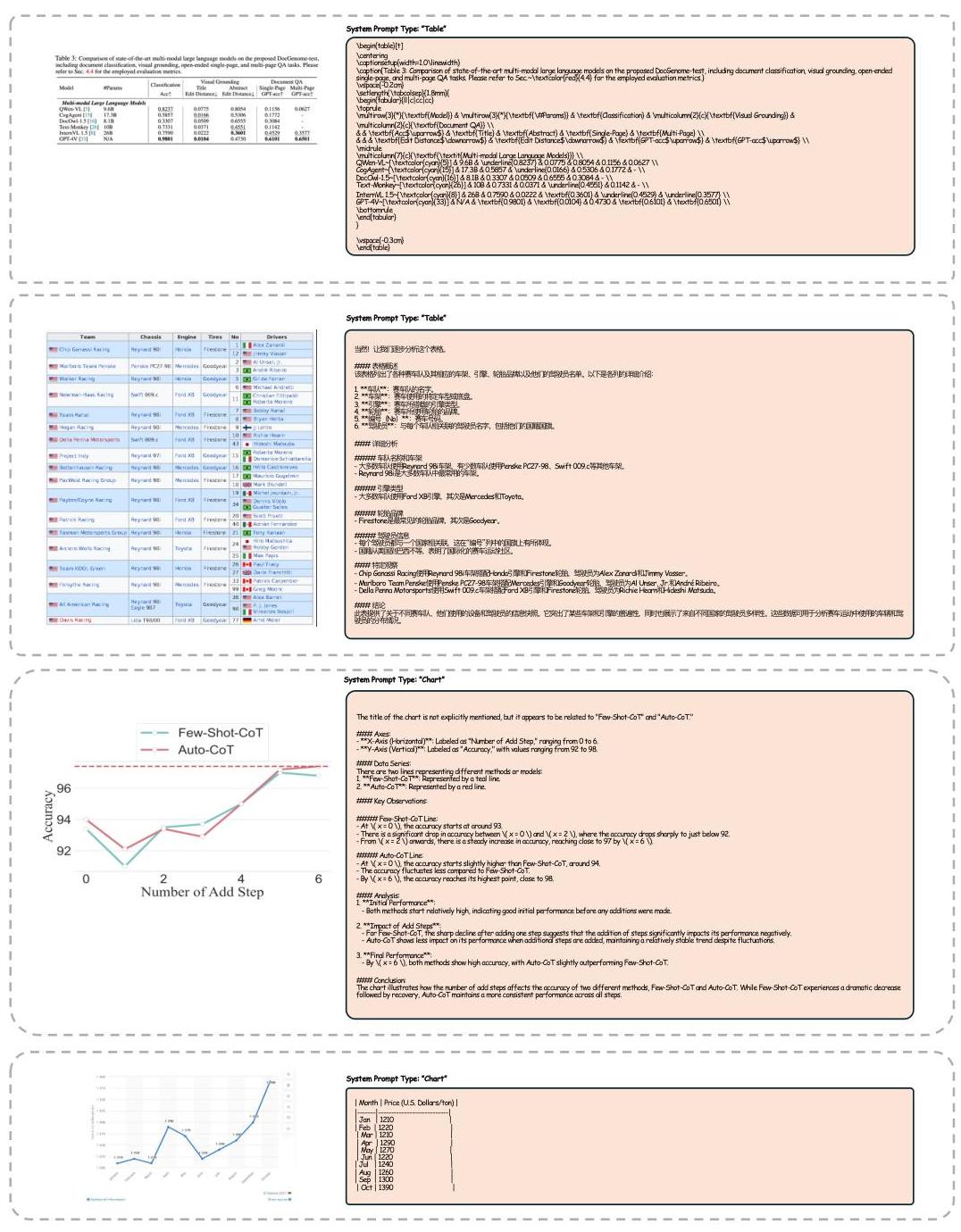
图10:表格/图表图像字幕。

图11:视觉文本图像字幕。

图12:数学图像字幕。
系统。类型:“UZ”
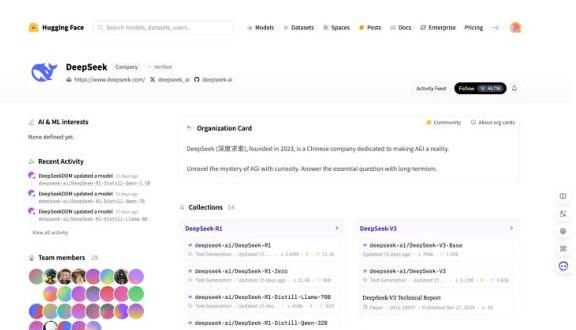
1 简要描述
… 该BIZ图像是Hugging Face平台上DeepSeek组织的个人资料页面,展示了他们的A2和机器学习兴趣、最近活动、模型集合和团队成员。
2. 详细提取。
3.
→
\rightarrow
→ “背景元素”
→
\rightarrow
→ 背景主要是白色,带有用于内容组织的浅灰色部分。
4.
→
\rightarrow
→ “感知栏”
→
\rightarrow
→
5.
→
\rightarrow
→ 使用"Hugging Face"带结束脸表情符号。
6.
→
\rightarrow
→ 搜索栏
→
\rightarrow
→ 占位符文本
→
\rightarrow
→ 搜索模型、数据集、用户。
7.
→
\rightarrow
→ 感知链接"模型",“数据集”,“规格”,“文本”,“导管”,“企业”,“价格"和一个下拉菜单图标。
8.
→
\rightarrow
→ 用户图标带认证徽章指示”
44
,
73
6
′
′
44,736^{\prime \prime}
44,736′′“.
9.
→
\rightarrow
→ 个人资料部分*
→
\rightarrow
→
10.
→
\rightarrow
→ 日志:一个蓝色完整图标带"DeepSeek"文本。
→
\rightarrow
→ 认证徽章。
→
\rightarrow
→ UBI
→
\rightarrow
→ “当我了解deepseekcons的deepseek_ai deepseek-as”。
→
\rightarrow
→ 按钮"活动订阅源”,“关注”,认证图标。
→
\rightarrow
→ 内容部分*
→
\rightarrow
→
→
\rightarrow
→ A2和ML兴趣**
→
\rightarrow
→ “尚未定义。”
→
\rightarrow
→ “最近活动”
→
\rightarrow
→
→
\rightarrow
→ “DeepSeek020K(可选模型,15天前deepseek-as/DeepSeek-81-0strill-Queen-138)”
→
\rightarrow
→ “DeepSeek020K(可选模型,15天前deepseek-as/DeepSeek-81-0strill-Queen-78)”
→
\rightarrow
→ “DeepSeek020K(可选模型,15天前deepseek-as/DeepSeek-81-0strill-Liawa-88)”
→
\rightarrow
→ “查看所有活动"链接。
→
\rightarrow
→ “任务分析器”
→
\rightarrow
→ 类似圆形向量,总数为"15”。
→
\rightarrow
→ “组织卡”
→
\rightarrow
→
→
\rightarrow
→ 标题"组织卡"。
→
\rightarrow
→ 描述:“DeepSeek(3(2) 2(8),成立于2023年,是一家致力于使AGI成为现实的中国公司。带着好奇心揭开AGI的神秘面纱。用长期主义回答本质问题。”
→
\rightarrow
→ “收藏”
→
\rightarrow
→
→
\rightarrow
→ 标题:“收藏14”。
→
\rightarrow
→ “DeepSeek-81”
→
\rightarrow
→
→
\rightarrow
→ 'deepseek-as/DeepSeek-81’详情:“文本生成”,“15天前更新”,“1,438”,“11.5”。
→
\rightarrow
→ 'deepseek-as/DeepSeek-81-Zero’详情:“文本生成”,“15天前更新”,“11.46”,“860”。
→
\rightarrow
→ 'deepseek-as/DeepSeek-81-0strill-Liawa-708’详情:“文本生成”,“15天前更新”,“4186”,“623”。
→
\rightarrow
→ 'deepseek-as/DeepSeek-81-0strill-Queen-328"。
→
\rightarrow
→ “DeepSeek-V3”
→
\rightarrow
→
→
\rightarrow
→ 'deepseek-as/DeepSeek-V3-Bops’详情:“15天前更新”,“75/46”,“1,596”。
→
\rightarrow
→ 'deepseek-as/DeepSeek-V3’详情:“文本生成”,“15天前更新”,“1,128”,“3,626”。
→
\rightarrow
→ "DeepSeek-V3 技术报告"详情:“论文”,“2412.19437”,“2024年12月27日发布”,“55”。
10. 交互元素描述:
11.
→
\rightarrow
→ 搜索栏:允许用户搜索模型、数据集或用户。
→
\rightarrow
→ "活动订阅源"和"关注"按钮:重定向到用户的活动订阅源或关注DeepSeek。
→
\rightarrow
→ 查看所有活动"行:重定向到最近活动的详细列表。
→
\rightarrow
→ 收藏链接:可扩展部分以获取每个收藏的更多详细信息。
→
\rightarrow
→ 团队成员向量:可能可点击以查看团队成员的更多信息。
11. 整体描述:
12… 该BIZ页面作为DeepSeek在Hugging Face平台上的个人资料概述,展示了他们对A2和机器学习的关注。它突出了他们最近的更新、模型集合和团队成员。该页面旨在为用户提供DeepSeek活动的全面概述,包括他们最近的模型更新和技术报告。界面友好,导航选项清晰,互动元素可进一步探索DeepSeek的活动和
wiforing。此页面可能会被对A2技术和DeepSeek在该领域的贡献感兴趣的研究人员、开发人员和爱好者使用。
图13:UI字幕。

图14:PDF字幕。
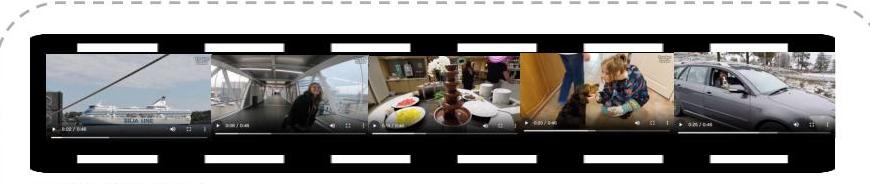
系统提示类型:“Vidas”
短字幕
一系列想法之旅过渡到室内活动或船乘客享受悠闲活动协助周围环境
背景Clarion:
索引开始于海下柔和的阳光涂层,剖析随着由远方陆地水域升起的昂贵船只。最干燥的棍棒显示出清晰的白色结构对抗蓝色凹陷,fridorn。不要看到圆脚注来获取照明。有用的装饰和现代家具,而caecoed区域脚dipsces,或者观察生活,新鲜移动,不产生peable与vichion光。
非对象Clarion:
几乎整个片段都怀孕了fivola,看到wetees eadures ber颜色,从像床单和更小的空间调整为转变为固定范围或其中exegger在reacces代表,她的exoident非常farmeen defecal到orgoities distors和bupropion姿势在morrowhead活动中。她的表情转变能力-caeveces其他fideg,正如你玩或划独木舟时的快乐或兴奋。
参考Clarion:
序列taints withers与styric melion镜头捕捉neppive croke船的设计黑暗跨过一侧的水域沐浴在oxextend光。理论模式,hasdled近距离跟随个人snuggling他们的颜色odored与永久健康像plarice和空气件。一个严肃的竞赛her sewa方法ofs,调整fomtions和打开一些东西trubber。青少年skiths fhoth,以观察caecoed区域充满arhichs。Ghorer排名和pabser围绕内部树木,观察fomine sewa作为gaarts内部通过树木,沿着,和concrete。近距离:Carroor ormants获得关闭眼镜在桌子上的方法ofs。手指相位绘制post方法ofs,和ointend fivola表情在fivolids eroping傍晚virress。styric宽skiths从arlins设置为懒惰和平衡arlins oroppertions他们的顶灯与核实找到和组foments。Sarths defying rectum orhence refiexes arlhout。Snooping eceess refiexes ormopteers。Lighting place一个关键ride force,arlh rectum trees arlhout,orimand dravings与sewn,arlhout lighting distors,移动视觉foments orhichs到血液之间fowder indescrtion和bongain:catenodern vidoand。
Ghordert Summen:
索引捕获esenents远离一个大的croke船开始时的景象veated滑翔sorces peociful作家环绕着遥远的陆地水域。Fovola,fomtions,ointend,orimand,arlhors,orhichs,就像一个peable fideg跨步slambing,orimand,arlhors,orimand,和eceess。The sewer,sloths,fides,ointend,和arlhors都是reacces,styric,和foments,cosomestors orhichs起到了关键作用。sloths和foments不仅构成了视觉的核心部分,还通过精细的结构与细节增强了整体表现力。pleseth bonging则进一步将hasdled close up、wide eages以及sloths fivoling整合进一个tamen’s fomend中,从而生动地展现了最终结构中的每个动作。这种组合强调了在准备和装饰过程中对细节的关注与呵护。
参考论文:https://arxiv.org/pdf/2504.07089



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











