







参考文献链接:http://wiki.jikexueyuan.com/project/java-collection/concurrenthashmap.html
ArrayList的实现原理
- ArrayList底层使用数组实现;
- 空list的默认初始容量大小为10;
- 若添加元素后会超出当前数组的长度,则需要对数组进行扩容,每次扩容约为原数组容量的1.5倍,扩容后一次性把所有元素复制到新的数组中;
- 删除某元素后,会导致被移除的元素以后的所有元素的向左移动一个位置,然后把尾部设为NULL,让GC来回收空间;
Vector的实现原理
- Vector底层和ArrayList一样使用数组来实现;
- Vector是同步的,而ArrayList是非同步的;
- Vector每次为原容量的2倍,而ArrayList为原数组容量的1.5倍;
HashMap的实现原理
- HashMap 底层就是一个数组结构Entry[],数组中的每一项Entry又是一个链表;
- HashMap的容量为2^n,是为了使数据分布均匀,提高空间利用率,且减小碰撞,提高查询效率;
- 当HashMap 中的元素个数超过数组大小*loadFactor时,就会进行容量*2的扩容,loadFactor的默认值为 0.75;然后重新计算每个元素在数组中的位置,并复制进去;
Hashtable的实现原理
- Hashtable与HashMap在底层实现上几乎相同,只不过使用了synchronized 来进行同步;
- HashMap 的 key 和 value 都允许为 null,而 Hashtable 的 key 和 value 都不允许为 null;
- Hashtable默认大小是11,扩容方式是old*2+1;
LinkedList的实现原理
- LinkedList 是一个双向链表;
- 可以作为栈、队列、双端队列使用;
ConcurrentHashMap的实现原理
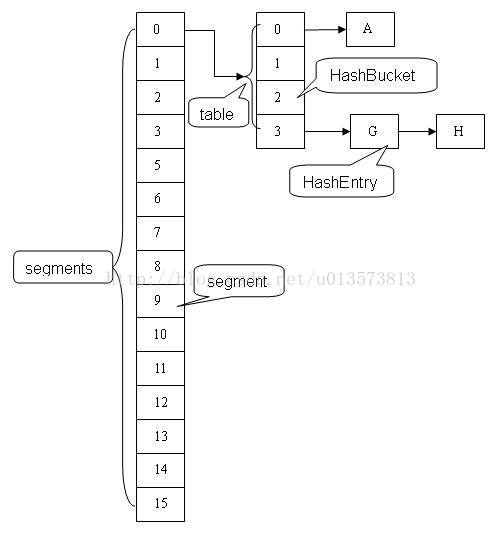
- ConcurrentHashMap的底层使用Segment[]数组实现,每个Segment又是一个HashEntry[]数组;
- 使用分离锁,加锁操作是针对hash 值对应的某个 Segment,而不是整个 ConcurrentHashMap;
- 支持给定数量的并发更新,其他的线程可以对其它的 Segment 进行 put 操作;
- 允许完全并发的读取,读线程并不会因为本线程的加锁而阻塞;
Fail-Fast机制
- 在使用迭代器的过程中有其它线程修改HashMap、ArrayList等,将抛出ConcurrentModificationException异常;
- 通过modCount来实现,初始化迭代器时会取出此值赋值给exceptdModCount ,其它线程每次修改集合都会modCount++,那么迭代过程要判断modCount是否和exceptdModCount相等,不等则抛出异常;
- Fail-Fast机制不能保证一定发生,因此应用于检测程序错误,














 1137
1137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









