




 本文详细介绍了如何优化Filebeat配置以提高大文件的采集效率,包括增大`bulk_max_size`以减少批量请求次数,增加`worker`数量以提高并发,调整`harvester_buffer_size`以增加单次读取文件的大小。同时,讨论了如何利用`registry`、`clean_inactive`和`clean_removed`等参数实现文件的重新采集。在文件重命名或删除的场景下,讨论了`close_ *`参数的作用,以确保在不影响采集的情况下正确处理文件操作。
本文详细介绍了如何优化Filebeat配置以提高大文件的采集效率,包括增大`bulk_max_size`以减少批量请求次数,增加`worker`数量以提高并发,调整`harvester_buffer_size`以增加单次读取文件的大小。同时,讨论了如何利用`registry`、`clean_inactive`和`clean_removed`等参数实现文件的重新采集。在文件重命名或删除的场景下,讨论了`close_ *`参数的作用,以确保在不影响采集的情况下正确处理文件操作。
文章目录
最近和一些客户交流,发现他们在使用filebeat进行文件采集的时候,主要的场景并不是以行为单位进行采集,而是以文件为单位进行采集。比如,一些实验数据是以文件的形式生成的,即filebeat的监控目录中会在实验结束后,添加数个实验结果的文件,这些文件有以下特点:
- 文件内容很大,从十万行到千万行级别不等
- 文件是一次性的变动,即直接移动到监控目录当中,之后不会再有改动
- 文件可能会有重命名或者删除操作
因为filebeat的默认监控对象是日志型文件,即数据会持续以行为单位输出到文件当中。因此filebeat的默认设置都是按照持续扫描,监控rotate的方式来完成数据采集的。因而,针对以上提到的结果型文件的一次性特点,我们需要对filebeat的配置进行一些特定的修改。
如何提高文件采集效率
对于结果型文件,大多数时候,这些文件都是很大的,动辄几十M,多辄几百M,文件由十万行到千万行级别不等。
举个例子,这是一个172247行的文件,文件大小在11M左右
使用filebeat的默认配置,我们会发现这个文件的采集大概需要花费5~10分钟。如果一个文件有上千万行,那么这个文件的采集可以达到1000分钟,这对我们来说是不可接受的。
这里,是什么限制了filebeat的采集速率?
bulk_max_size
# The maximum number of events to bulk in a single Elasticsearch bulk API index request.
# The default is 50.
bulk_max_size: 50
这个是output.elasticsearch的属性,控制发送给Elasticsearch的bulk API中,每批数据能包含多少条event,默认情况下,我们是每行数据一个document(或者说是event),因此,每次filebeat默认只会发送50行数据,因此,当我们添加进来的数据由几十万行的时候,可以简单推算,我们需要推送多少次bulk request才能完成这个文件的数据录入
因此,我们可以综合考虑并发的环境来修改此参数。比如,我们所有的数据集中在几台机器上,只有几个filebeat实例在负责数据的录入时,我们可以把这个数据适当调大到500~1000的级别。需根据ES的吞吐,可以参考我们的benchmark:
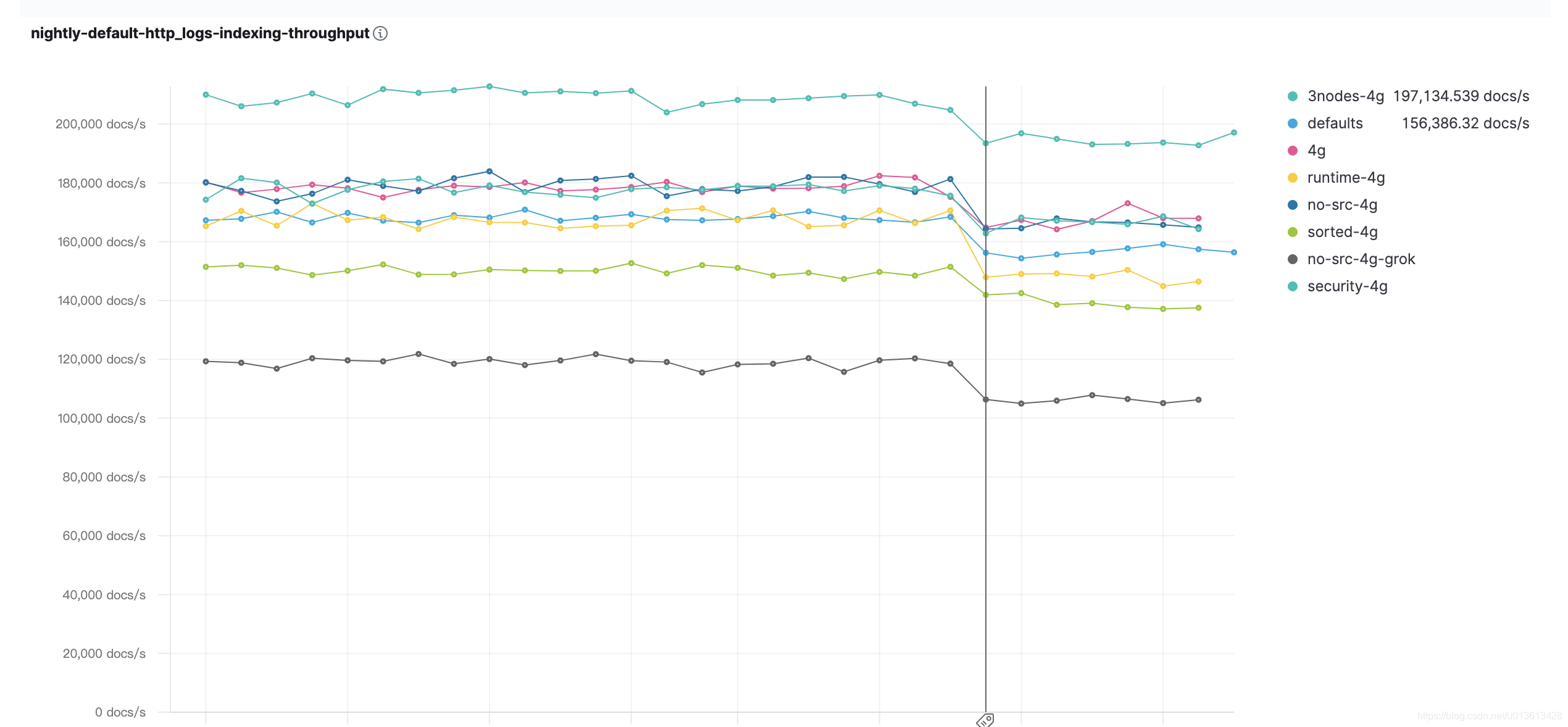
如何读懂这些指标可以参考我的另一篇博文:如何解读Elasticsearch benchmark上的各种指标
可以看到,使用SSD的情况下,3节点可以达到10万+的吞吐。比如说,我们现在只有3个filebeat进行专门的文件录入(通常这种情况下,存储文件的服务器并没有其他的服务需要运行),我们甚至可以让filebeat的在一个bulk request发送数千条event,当然,这个需要结合单条event的size,比如,一条event只有几十个byte,那么一次bulk request即便包含1000条event也只有几十K的大小,即我们可以再调大这个参数。
worker
# Number of workers per Elasticsearch host.
worker: 1
这个也是output.elasticsearch的属性,我们可以指定filebeat使用多高的并发来往Elastic发送数据,我们也可以适当的增加这个值,比如我们的ES集群有3个data节点 hosts: ["10.0.07:9200","10.0.08:9200","10.0.09:9200"],我们可以把这个worker设为 3。
结合上一个设置bulk_max_size: 1000,则我们可以达到更高的吞吐
harvester_buffer_size
# Defines the buffer size every harvester uses when fetching the file
harvester_buffer_size: 16384
这个是Log input的属性,这个属性限定了单个文件采集器harvester每次读取文件的大小,默认的大小是16K。如果我们要增加某些文件的读取吞吐,可以调整这个值的大小。可以通过定义多个input,每个input单独指定的方式来确定不同文件的吞吐大小,比如下面的配置,两个文件的吞吐就不一样:
filebeat.inputs:
- type: log
paths:
- '/Users/lex.li/Downloads/2020_04_11/平台指标/db_oracle_11g.csv'
exclude_lines: ['^"?itemid"?,"?name"?,"?bomc_id"?,"?timestamp"?,"?value"?,"?cmdb_id"?']
harvester_buffer_size: 1638400
- type 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









