







链表:
struct node
{
int data;
node* next;
};
这个结构有两个成员数据,一个是整数data,另外一个是指向这种结构的指针next。那么若干个这样的结构变量,就能把这些变量连接成一条链子。

这些利用结构指针连接起来的结构变量称为链表(Link List),每一个结构变量(相当于链条中的每个环节)称为链表的结点(Node)。
和数组一样,链表也可以用来存储一系列的数据,它也是电脑中存储数据的最基本的结构之一。
链表可以在程序运行时根据实际需要动态地一个个分配堆内存空间,并且用它的指针把一系列零零散散的内存空间串联起来,就像一条链子一样。这样一来,就能够利用指针对整个链表进行管理了。
如果任何一个分配的结构变量失去了指向它的指针,那么这个内存空间将无法释放,就造成了内存泄漏。由于指针还维系着各结点之间关系,指针的丢失造成了结点之间断开,整个链表就此被破坏。
所以,必须要保证每个结点都在控制之内,即利用指针访问到链表的任一个结点。这也是在所有对链表的操作过程中始终要注意的一点。
遍历:能够访问到链表中的每一个结点,即输出每个结点的数据。
创建链表:
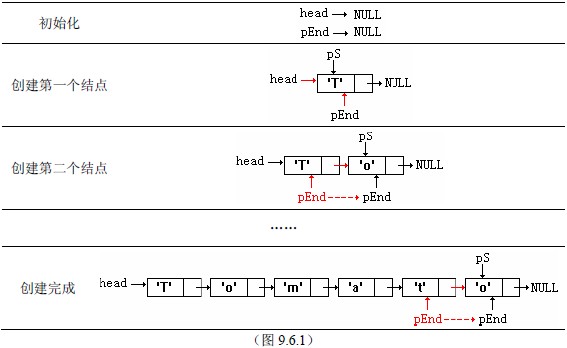
一、由于第一个结点也是动态分配的,因此一个链表始终要有一个指针指向它的表头,否则将无法找到这个链表。把这个表头指针称为head。
二、在创建一个多结点的链表时,新的结点总是连接在原链表的尾部的,所以必须要有一个指针始终指向链表的尾结点,方便操作。把这个表尾指针称为pEnd。
三、每个结点都是动态分配的,每分配好一个结点会返回一个指针。由于head和pEnd已经有了各自的岗位,还需要一个指针来接受刚分配好的新结点。把这个创建结点的指针称为pS。
四、在遍历的过程中,需要有一个指针能够灵活动作,指向链表中的任何一个结点,以读取各结点的数据。把这个访问指针称为pRead。
五、应该要把创建链表和遍历各自写为一个函数,以方便修改和维护。
#include<iostream>
using namespace std;
struct node//定义结点结构类型
{
char data;//用于存放字符数据
node* next;//用于指向下一个结点(后继结点)
};
node* create(void);//创建链表的函数,返回表头
void showList(node* head);//遍历链表的函数,参数为表头
int main()
{
node* head;
head=create();//以head为表头创建一个链表
showList(head);//遍历以head为表头的链表
return 0;
}
node* create()
{
node* head=NULL;//表头指针,一开始没有任何结点,所以为NULL
node* pEnd=head;//表尾指针,一开始没有任何结点,所以指向表头
node* pS=NULL;//创建新结点时使用的指针
char temp;//用于存放从键盘输入的字符
cout<<"Please input a string end with '#':"<<endl;
do//循环至少运行一次
{
cin>>temp;
if(temp!='#')//如果输入的字符不是结尾符#,则建立新结点
{
pS=new node;//创建新结点
pS->data=temp;//新结点的数据为temp
pS->next=NULL;//新结点将成为表尾,所以next为NULL
if(head==NULL)//如果链表还没有任何结点存在
head=pS;//则表头指针指向这个新结点
else//否则
pEnd->next=pS;//把这个新结点连接在表尾
pEnd=pS;//这个新结点成为了新的表尾
}
}
while (temp!='#');//一旦输入了结尾符,则跳出循环
return head;//返回表头指针
}
void showList(node* head)
{
node* pRead=head;//访问指针一开始指向表头
cout<<"The data of the link list are:" <<endl;
while(pRead!=NULL)//当访问指针存在时(即没有达到表尾)
{
cout<<pRead->data;//输出当前访问结点的数据
pRead=pRead->next;//访问指针向后移动
}
cout<<endl;
}
//运行结果:
//Please input a string end with '#':
//Tomato#
//The data of the link list are:
//Tomatocreate函数的主要工作有:
①做好表头表尾等指针的初始化。
②反复测试输入的数据是否有效,如果有效则新建结点,并做好该结点的赋值工作。将新建结点与原来的链表连接,如果原链表没有结点,则与表头连接。
③返回表头指针。
程序中showList函数的主要工作有:
①初始化访问指针。
②如果访问指针不为空,则输出当前结点的数据,否则函数结束。
③访问指针向后移动,并重复第二项工作。
注意,虽然上述程序可以运行,但是它没有将内存释放,严格意义上来说,它是一个不完整的程序。
链表的查询:
node* search(node* head,char keyWord)//返回结点的指针
{
node* pRead=head;
while(pRead!=NULL)//采用与遍历类似的方法,当访问指针没有到达表尾之后
{
if(pRead->data==keyWord)//如果当前结点的数据和查找的数据相符
return pRead;//则返回当前结点的指针
else
pRead=pRead->next;//数据不匹配,pRead指针向后移动,准备查找下一个结点
}
return NULL;//所有的结点都不匹配,返回NULL
}插入节点:
对插入结点这个功能具体分析一下:
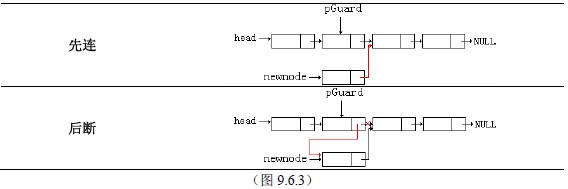
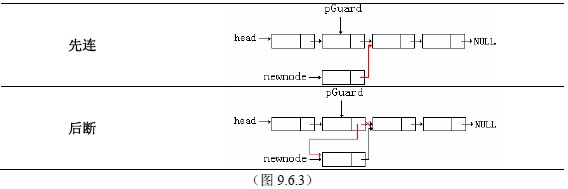
一、必须知道对哪个链表进行操作,所以表头指针head是必须知道的。
二、为了确定插入位置,插入位置前的结点指针pGuard是必须是知道的。
三、用一个newnode指针来接受新建的结点。
四、如果要插入的位置是表头,由于操作的是表头指针而不是一个结点,所以要特殊处理。
五、在插入结点的过程中,始终要保持所有的结点都在控制范围内,保证链表的完整性。为了达到这一点,采用先连后断的方式:先把新结点和它的后继结点连接,再把插入位置之前的结点与后继结点断开,并与新结点连接。
void insert(node* &head,char keyWord,char newdata)//keyWord是查找关键字符
{
node* newnode=new node;//新建结点
newnode->data=newdata;//newdata是新结点的数据
node* pGuard=search(head,keyWord);//pGuard是插入位置前的结点指针
if(head==NULL||pGuard==NULL)//如果链表没有结点或找不到关键字结点则插入表头位置
{
newnode->next=head;//先连
head=newnode;//后断
}
else//否则插入在pGuard之后
{
newnode->next=pGuard->next;//先连
pGuard->next=newnode;//后断
}
}删除结点:
与插入数据类似,数组为了保持其顺序存储的特性,在删除某个数据时,其后的数据都要依次前移。而链表中结点的删除仍然只要对结点周围小范围的操作就可以了,不必去修改其他的结点。
对删除结点这个功能具体分析一下:
一、必须知道对哪个链表进行操作,所以表头指针head是必须知道的。
二、一般来说,待删除的结点是由结点的数据确定的。然而还要操作待删除结点之前的结点(或指针),以连接前后两段链表。之前所写的search函数只能找到待删除的结点,却无法找到这个结点的前趋结点。
三、令pGuard指针为待删除结点的前趋结点指针。
四、由于要对待删除结点作内存释放,需要有一个指针p指向待删除结点。
五、如果待删除结点为头结点,则要操作表头head,作为特殊情况处理。
六、在删除结点的过程中,仍然要始终保持所有的结点都在控制范围内,保证链表的完整性。为了达到这一点,还是采用先连后断的方式:先把待删除结点的前趋结点和它的后继结点连接,再把待删除结点与它的后继结点断开,并释放其空间。
七、如果链表没有结点或找不到待删除结点,则给出提示信息。
void Delete(node* &head,char keyWord)//可能要操作表头指针,所以head是引用
{
if(head!=NULL)//如果链表没有结点,就直接输出提示
{
node* p=NULL;
node* pGuard=head;//初始化pGuard指针
if(head->data==keyWord)//如果头结点数据符合关键字
{
p=head;//头结点是待删除结点
head=head->next;//先连
delete p;//后断
cout<<"The deleted node is "<<keyWord<<endl;
return;//结束函数运行
}
else//否则
{
while(pGuard->next!=NULL)//当pGuard没有达到表尾
{
if(pGuard->next->data==keyWord)//如果pGuard后继结点数据符合关键字
{
p=pGuard->next;//pGuard后继结点是待删除结点
pGuard->next=p->next;//先连
delete p;//后断
cout<<"The deleted node is "<<keyWord<<endl;
return;//结束函数运行
}
pGuard=pGuard->next;//pGuard指针向后移动
}
}
}
cout<<"The keyword node is not found or the link list is empty!"<<endl;//输出提示信息
}
清除链表:
链表的结点也是动态分配的,如果在程序结束之前不释放内存,就会造成内存泄漏。因此,编写一个清除链表的函数就显得相当有必要。
先来分析一下清除这个功能:
一、必须知道对哪个链表进行操作,所以表头指针head是必须知道的,并且清除整个链表后要将其改为NULL。
二、类似于删除结点,还需要一个指针p来指向待删除结点。
三、类似于删除表头结点的操作,仍然要 先连后断:先把表头指向头结点的后继,再删除头结点。void destroy(node* &head)
{
node* p=NULL;
while(head!=NULL)//当还有头结点存在时
{
p=head;//头结点是待删除结点
head=head->next;//先连
delete p;//后断
}
cout<<"The link list has been deleted!"<<endl;
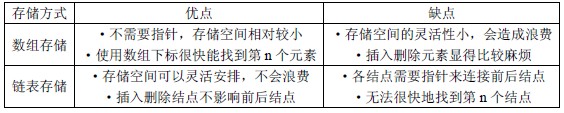
}数组存储和链表存储各自的优缺点:















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









