








Faster R-CNN是当前目标检测领域内性能最好的算法之一,它将RPN(Region Proposal Network)网络和Fast R-CNN网络结合到了一起,实现了一个端到端的目标检测框架。作者Shaoqing Ren在github上公开了源代码,可以很方便地在自己的机器上进行测试。本文记录的是Ubuntu14.04下配置和测试Faster R-CNN的过程,其中包括Caffe的安装和编译过程,针对的是Matlab和仅使用CPU的环境。
文章arXiv链接:
https://arxiv.org/abs/1506.01497
下载源代码
Matlab源码链接:
https://github.com/ShaoqingRen/faster_rcnn
Python实现源码:
https://github.com/rbgirshick/py-faster-rcnn
下载源码faster_rcnn-master.zip以及其中的caffe源码,解压至本地目录。
安装编译Caffe
1.安装依赖项[1]
sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
sudo apt-get install --no-install-recommends libboost-all-devsudo apt-get install libatlas-base-devsudo apt-get install the python-devsudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev# glog
wget https://google-glog.googlecode.com/files/glog-0.3.3.tar.gz
tar zxvf glog-0.3.3.tar.gz
cd glog-0.3.3
./configure
make && make install
# gflags
wget https://github.com/schuhschuh/gflags/archive/master.zip
unzip master.zip
cd gflags-master
mkdir build && cd build
export CXXFLAGS="-fPIC" && cmake .. && make VERBOSE=1
make && make install
# lmdb
git clone https://github.com/LMDB/lmdb
cd lmdb/libraries/liblmdb
make && make install2.编译
Caffe可以采用Make或者CMake两种方式来编译,我使用的是Make,且编译之前需要根据个人情况修改caffe目录下的Makefile.config.example文件。具体需要修改的地方如下:
- 仅使用CPU的情况下,需要取消该文件中
CPU_ONLY := 1的注释。 - 指定Matlab的安装路径,我的是
MATLAB_DIR := /usr/local/MATLAB/R2016a。
修改完成后,执行如下命令:
cp Makefile.config.example Makefile.config
make clean
make all
make test
make runtestmake matcaffe之后在matlab/+caffe/private目录下将会生成caffe_.mex64文件,可以直接被Matlab调用。
3.测试示例[2]
在正式测试前,需要下载训练好的caffemodel文件[3]。有两种方式,直接在浏览器里输入地址下载,也可以运行脚本文件下载。我选择直接用浏览器下载,下载地址如下:
http://dl.caffe.berkeleyvision.org/bvlc_reference_caffenet.caffemodel
该模型文件243.9M,下载完成后将其拷贝到caffe根目录下的models/bvlc_reference_caffenet/文件夹中。
接着启动Matlab,切换到caffe的根目录,将caffe_.mex64的路径添加进来,便于加载。
addpath('./matlab/+caffe/private');I = imread('../../examples/images/cat.jpg');
[scores, maxlabel] = classification_demo(I, 0);Elapsed time is 0.025054 seconds.
Elapsed time is 1.069503 seconds.
Cleared 0 solvers and 1 stand-alone nets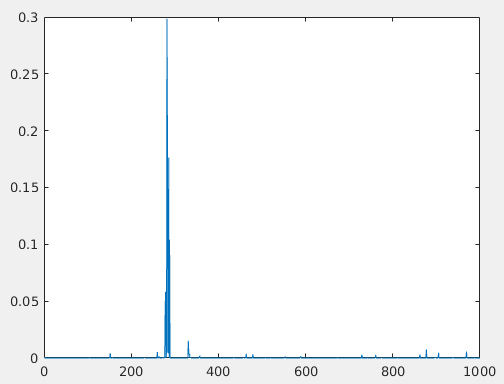
从图中可以看出,该图片被分到第282类的概率最高。至此,程序测试完成,说明Caffe安装配置成功。
配置运行Faster R-CNN
Faster R-CNN的配置和运行十分简单,启动Matlab,切换到faster_rcnn目录下。运行faster_rcnn_build.m,在仅使用CPU的情况下,Compiling nms_gpu_mex时会出错[4]。但是其他能够编译成功,这里不用担心。
run faster_rcnn_build.m
run startup.m获取训练好的模型,可以通过执行文件下载:
run fetch_data/fetch_faster_rcnn_final_model.m个人建议直接通过作者github主页上的链接来下载模型,地址在主页最后一行给出,选择其一下载。
3.Final RPN+FastRCNN models: OneDrive, DropBox, BaiduYun
模型较大,下载完成后直接将其解压至faster_rcnn根目录下。
在experiments目录下有测试文件,因为只使用CPU,运行前需要将其设置为不使用GPU。
experiments/script_faster_rcnn_demo.m
文件中的第3、4行需要注释掉,第9行的opts.use_gpu改为false。以下是修改后的代码,
%% -------------------- CONFIG --------------------
opts.caffe_version = 'caffe_faster_rcnn';
% opts.gpu_id = auto_select_gpu;
% active_caffe_mex(opts.gpu_id, opts.caffe_version);
opts.per_nms_topN = 6000;
opts.nms_overlap_thres = 0.7;
opts.after_nms_topN = 300;
opts.use_gpu = false;
opts.test_scales = 600;此外,由于VGG16模型较大,运行过程中会崩溃,因此将模型改为ZF,修改后如下:
% model_dir = fullfile(pwd, 'output', 'faster_rcnn_final', 'faster_rcnn_VOC0712_vgg_16layers'); %% VGG-16
model_dir = fullfile(pwd, 'output', 'faster_rcnn_final', 'faster_rcnn_VOC0712_ZF'); %% ZF至此,修改完毕。执行该程序,能够正常运行说明测试成功。我的处理器是Intel® Core™ i7-2600 CPU @ 3.40GHz × 8 ,输出如下信息:
001763.jpg (500x375): time 3.258s (resize+conv+proposal: 2.452s, nms+regionwise: 0.806s)
004545.jpg (500x375): time 4.073s (resize+conv+proposal: 2.543s, nms+regionwise: 1.530s)
000542.jpg (500x375): time 3.064s (resize+conv+proposal: 2.526s, nms+regionwise: 0.538s)
000456.jpg (500x375): time 3.757s (resize+conv+proposal: 2.497s, nms+regionwise: 1.259s)
001150.jpg (500x375): time 3.400s (resize+conv+proposal: 2.481s, nms+regionwise: 0.919s)
mean time: 3.510s
Cleared 0 solvers and 2 stand-alone nets
参考文献:
[1]http://caffe.berkeleyvision.org/install_apt.html
[2]http://www.aichengxu.com/view/2422137
[3]http://www.cnblogs.com/denny402/p/5111018.html
[4]http://blog.csdn.net/qq_30040223/article/details/48491997














 75万+
75万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









