







此为作者学习中的笔记,多有网搜资料。
DATA:8-1
#progma pack(1)的解释:
有如下的两个结构体:
struct A struct B
{ {
int a; int a;
unsigned int64 b; short c;
short c; unsigned int64 b;
}; };那么 sizeof(A) 和 sizeof(B) 一样吗?怎么不一样?两个结构体明明相同,只是第二和第三个成员变量的位置颠倒了结果却大相径庭。到底是因为什么呢?
答案是编译器的数据对齐方式在作怪。以 vc6.0 为例,默认情况下的对其方式是 8 位。所以struct A的大小为 24,struct B 的大小为 16, 下面就具体分析一下数据空间占用情况。
在struct A 中的, 编译器首先检测所有的成员变量中的 size 最大值。很显然 unsigned int64 最大, sizeof(unsigned int64) 为 8 ,然后第一个变量 a 为 int 型只占 4 个字节,但是为了对齐其被补上了四个字节 , 接着变量 b 在变量a有效位置之后被放置,但是目前只有 4 个空闲的字节,根本放不下b ,于是编译器就再申请了8 字节的空间大小,将变量b 放在 4 个空闲字节之后,也就是说变量b的起始位置在第九个字节。由于变量 b 需要 8 个字节所以没有留给变量 c 任何的剩余空间,于是变量 c 再次申请 8 个字节的空间用于存储自己,当然它本可以只申请 2 字节的空间就行了,但是为了对齐只能申请8字节。
在struct B 中的 , 编译器前几步的处理也和structA 的一样,直到该处理变量 c 时,编译器依然要先看看为变量a分配的空间是否还有多余并且多余的空间是否足以容纳下变量 c, 由于变量 c 只需要两个字节,而 a 却有 4 个字节的剩余空间,所以变量 c 就很轻松的被放置在 a 之后的 4 个字节内而不需要再申请空间。变量 b 依然申请 8 字节的空间并跟随在变量 a 空余空间之后。最后我们就可以看到如下图所示的数据存储结构:
通过以上的分析我们明白了结构体内部 (也可以引伸到类的内部) 成员变量的声明顺序并不是随意的,尤其是在内存需求特别紧张的开发环境中。
对齐的目的和原理,计算,什么是对齐,以及为什么要对齐:
对齐的作用和原因:
各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个int型(假设为 32 位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出,而如果存放在奇地址开始的地方,就可能会需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该int数据。显然在读取效率上下降很多。这也是空间和时间的博弈。
对齐的算法:
由于各个平台和编译器的不同,现以本人使用的gcc version 3.2.2编译器(32位x86平台)为例子,来讨论编译器对struct数据结构中的各成员如何进行对齐的。
设结构体如下定义:
struct A
{
int a;
char b;
short c;
};
结构体A中包含了4字节长度的int一个,1字节长度的char一个和2字节长度的short型数据一个。所以A用到的空间应该是7字节。但是因为编译器要对数据成员在空间上进行对齐。所以使用sizeof(strcut A)值为8。
现在把该结构体调整成员变量的顺序:struct A
{
char b;
int a;
short c;
};
这时候同样是总共7个字节的变量,但是sizeof(struct B)的值却是12。
下面我们使用预编译指令#progmapack (value)来告诉编译器,使用我们指定的对齐值来取代缺省的。
#progma pack (2) /*指定按2字节对齐*/
#progma pack () /*取消指定对齐,恢复缺省对齐*/
这里面有四个概念值:
1、数据类型自身的对齐值:就是上面交代的基本数据类型的自身对齐值。
2、指定对齐值:#progma pack(value)时的指定对齐值value。
3、结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值。
4、数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中小的那个值。
有了这些值,我们就可以很方便的来讨论具体数据结构的成员和其自身的对齐方式。有效对齐值N是最终用来决定数据存放地址方式的值,最重要。有效对齐N,就是表示“对齐在N上”,也就是说该数据的"存放起始地址%N=0"。
STM8S是基于8 位框架结构的微控制器
程序计数器用于存储CPU下一条要执行指令的地址。其内容在每一次指令操作后被自动刷新。
堆栈指针是一个16位的寄存器,其内容为堆栈中下一个可自由分配的单元地址,堆栈一般用于在中断调用或子程序调用时存储CPU的上下文,入栈操作使堆栈指针值减小,出栈操作使堆栈指针值增加。
高速外部晶体振荡器(HSE)
高速内部RC振荡器(HSI)
IrDA是一个半双工通信协议。如果发送器忙(也就是UART正在送数据给IrDA 编码器),IrDA
接收线上的任何数据都将被IrDA 解码器所忽略。如果接收器忙(也就是UART正在接收从
IrDA 解码器来的解码数据),从UART 的TX上到IrDA 的数据将不会被IrDA 编码。当接收数据时,应该避免发送,因为将被发送的数据可能被破坏。
DATA:8-7
独立看门狗模块可以用于解决处理器因为硬件或软件的故障所发生的错误。它由一个内部的128kHz的LSI(低速内部)阻容振荡器作为时钟源驱动,因此即使是主时钟失效时它仍然照常工作。
DATA:8-9
OSSemPost 和OSSemPend是成对出现的,在程序OSSemPost 尚未运行到的时候,在等待Sem的OSSemPend是会把当前的任务挂起,直到另外一个任务的OSSemPost 运行完毕都得到Sem。但是可以通过改变OSSemCreate(x)里面的值x改变这种局面,当x不为0时,OSSemPend会马上得到Sem继续运行当前任务至结束,并将x的数值减一,直到为0。为0后,只有等其他任务的OSSemPost了。
DATA:8-13
软件定时器
μC/OS-II从V2.83版本以后,加入了软件定时器,这使得μC/OS-II的功能更加完善,在其上的应用程序开发与移植也更加方便。在实时操作系统中一个好的软件定时器实现要求有高精度、小开销、小资源。
μC/OS-II通过OSTimTick函数对时钟节拍进行加1操作,同时遍历任务控制块,以判断任务延时是否到时。软件定时器同样由OSTimTick提供时钟,但是软件定时器的时钟还受OS_TMR_CFG_TICKS_PER_SEC设置的控制,也就是在μC/OSII的时钟节拍上面再做了一次“分频”,软件定时器的最快时钟节拍就等于μC/OSII的系统时钟节拍。这也决定了软件定时器的精度。
μC/OS-II系统中的时间管理功能包括任务延时与软件定时器,而软件定时器的主要作用是,对函数周期性或者一次性执行的定时,利用软件定时器控制块与“定时器轮”管理软件定时器。定时器控制块的结构如同任务控制块,创建一个定时器时,从空闲定时器控制块链表中得到一个空闲控制块,并对其赋值。
软件定时器也需要一个时钟节拍驱动,而这个驱动一般是硬件实现的,一般使用μC/OSII操作系统中任务延时的时钟节拍来驱动软件定时器。每个时钟节拍OSTmrCtr(全局变量,初始值为0)增1,当OSTmrCtr的值等于为OS_TICKS_PER_SEC/OS_TMR_CFG_TICKS_PER_SEC(此两者的商决定软件定时器的频率)时,调用函数OSTmrSignal(),此函数发送信号量OSTmrSemSignal(初始值为0,决定软件定时器扫描任务OSTmr_Task的运行)。也就是说,对定时器的处理不在时钟节拍中断函数中进行,而是以发生信号量的方式激活任务OSTmr_Task(具有很高的优先级)。任务OSTmr_Task对定时器进行检测处理,包括定时器定时完成的判断、回调函数的执行。
AXF是ARM芯片使用的文件格式,它除包含bin代码外,还包括了调试信息。
DATA:8-15
malloc 和free 成对出现的原则,即"谁申请,就由谁释放",不满足这个原则,会导致代码的耦合度增大。正确做法:在调用处申请内存,并传入function 函数。
char *p = malloc(...);
if(p==NULL) //一定要判断是否申请成功
....;
function(p);
....
free(p);
p = NULL; //拴住!!!
volatile变量可能用于如下几种情况:
(1) 并行设备的硬件寄存器(如:状态寄存器);
(2) 一个中断服务子程序中会访问到的非自动变量(也就是全局变量);
(3) 多线程应用中被几个任务共享的变量。
C 语言最精华的内涵皆在内存操作中体现。
DATA:8-16
Thumb-2是一个突破性的指令集。它允许 32位指令和16位指令水乳交融,代码密度与处理性能两手抓,两手都硬。而且虽然它很强大,却依然易于使用。CM3支持绝大多数传统的Thumb指令。
DATA:8-22
ARM编译中的RO、RW和ZI DATA区段
ARM程序(指在ARM系统中正在执行的程序,而非保存在ROM中的bin文件)的组成:
一个ARM程序包含3部分:RO段,RW段和ZI段
RO----是程序中的指令和常量
RW---是程序中的已初始化变量
ZI------是程序中的未初始化的变量
由以上3点说明可以理解为:-
RO就是readonly,
RW就是read/write,
ZI就是zero
ARM映像文件的组成:
所谓ARM映像文件就是指烧录到ROM中的bin文件,也成为image文件。以下用Image文件来称呼它。
Image文件包含了RO和RW数据。之所以Image文件不包含ZI数据,是因为ZI数据都是0,没必要包含,只要程序运行之前将ZI数据所在的区域一律清零即可。包含进去反而浪费存储空间。
所以,对于如下编译器给出的信息,image占用FLASH的空间大小为:Size = Code + RO-data + RW-data。
程序运行时,占用内部RAM的空间大小为:Size = RW-data + ZI-data
Program Size: Code=24756 RO-data=1084 RW-data=152 ZI-data=12584代码只用指定两个段开始地址, RO段的起始地址和RW段的起始地址, ZI段紧接在RW段之后。
图示如下:
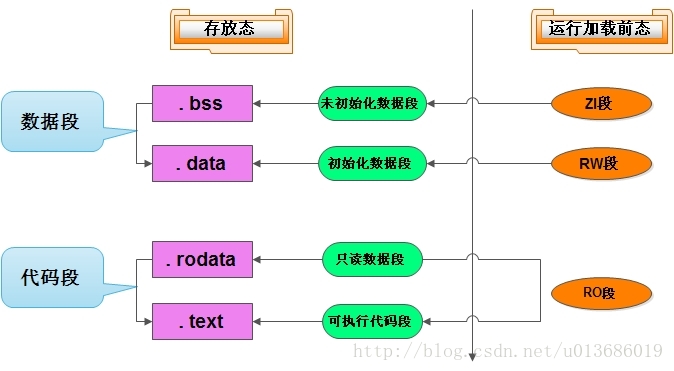
Q:为什么Image中必须包含RO和RW?
A:因为RO中的指令和常量以及RW中初始化过的变量是不能像ZI那样“无中生有”的。
总结:
1; C中的指令以及常量被编译后是RO类型数据。
2; C中的未被初始化或初始化为0的变量编译后是ZI类型数据。
3; C中的已被初始化成非0值的变量编译后市RW类型数据。
简单的说就是在烧写完的时候是:FLASH中:Code+RO Data+RW Data,运行的时候RAM: RW Data + ZI Data,当然还要有堆栈的空间。
DATA:8-23
指针的指针极其应用:
一.回顾指针概念:
今天我们又要学习一个叫做指向另一指针地址的指针。让我们先回顾一下指针的概念吧!
当我们程序如下声明变量:
short int i;
char a;
short int * pi; 程序会在内存某地址空间上为各变量开辟空间,如下图所示。
内存地址→6 7 8 9 10 11 12 13 14 15
-------------------------------------------------------------------------------------------------------------
… | | | | | | | | | |
-------------------------------------------------------------------------------------------------------------
|short int i |char a| |short int * pi|
图中所示中可看出:
i 变量在内存地址6的位置,占两个字节。
a变量在内存地址7的位置,占一个字节。
pi变量在内存地址9的位置,占两个字节。(注:pi是指针,我这里指针的宽度只有两个字节,32位系统是四个字节)
接下来如下赋值:
i = 50;
pi = &i;
经过上在两句的赋值,变量的内存映象如下:
内存地址→6 7 8 9 10 11 12 13 14 15
---------------------------------------------------------------------------------------------------------------
… | 50 | | | 6 | | | |
----------------------------------------------------------------------------------------------------------------
|short int i |char a| |short int * pi|
看到没有:短整型指针变量pi的值为6,它就是I变量的内存起始地址。所以,这是当我们对*pi进行读写操作时,其实就是对i变量的读写操作。如:
*pi=5; //就是等价于I=5;
二.指针的地址与指向另一指针地址的指针:
在上一节中,我们看到,指针变量本身与其它变量一样也是在某个内存地址中的,如pi的内存起始地址是10。同样的,我们也可能让某个指针指向这个地址。
看下面代码:
shortint * * ppi; //这是一个指向指针的指针,注意有两个*号
ppi = π第一句:shortint * * ppi;——申明了一个指针变量ppi,这个ppi是用来存储(或称指向)一个short int * 类型指针变量的地址。
第二句:&pi那就是取pi的地址,ppi=π就是把pi的地址赋给了ppi。即将地址值10赋值给ppi。如下图:
内存地址→6 7 8 9 10 11 12 13 14 15
----------------------------------------------------------------------------------------------------------------
… | 50 | | | 6 | 10 | |
----------------------------------------------------------------------------------------------------------------
|short int I|char a| |short int * pi|short int ** ppi|
从图中看出,指针变量ppi的内容就是指针变量pi的起始地址。于是……
ppi的值是多少呢?——10。
*ppi的值是多少呢?——6,即pi的值。
**ppi的值是多少呢?——50,即I的值,也是*pi的值。
三.一个应用实例
1.设计一个函数:void find1(char array[], char search, char *pi)
要求:这个函数参数中的数组array是以0值为结束的字符串,要求在字符串array中查找字符是参数search里的字符。如果找到,函数通过第三个参数(pa)返回值为array字符串中第一个找到的字符的地址。如果没找到,则为pa为0。
设计:依题意,实现代码如下。
void find1(char []array,char search,char * pa)
{
int i;
for (i=0;*(array+i)!=0;i++) {
if (*(array+i)==search) {
pa=array+i
break;
}
else if (*(array+i)==0) {
pa=0;
break;
}
}
}调试:我下面调用这个函数试试。
void main()
{
char str[]={“afsdfsdfdf\0”}; //待查找的字符串
char a=’d’; //设置要查找的字符
char *p=0; //如果查找到后指针p将指向字符串中查找到的第一个字符的地址 find1(str,a,p); //调用函数以实现所要操作。
if (0==p ) {
printf ("没找到!\n");
}
else {
printf("找到了,p=%d",p);
}
} 唉!怎么输出的是:没有找到!
而不是:找到了,……。
明明a值为’d’,而str字符串的第四个字符是’d’,应该找得到呀!
再看函数定义处:void find1(char [] array, char search, char * pa)
看调用处:find1(str,a,p);
函数调用时会对每一个参数进行一个隐含的赋值操作。
整个调用如下:
array = str;
earch = a;
pa=p; //请注意:以上三句是调用时隐含的动作。
int i;
for (i=0;*(array+i)!=0;i++)
{
if (*(array+i)==search) {
pa=array+i
break;
}
else if (*(array+i)==0) {
pa=0;
break;
}
}
哦!参数pa与参数search的传递并没有什么不同,都是值传递嘛(小语:地址传递其实就是地址值传递嘛)!所以对形参变量pa值(当然值是一个地址值)的修改并不会改变实参变量p值,因此p的值并没有改变(即p的指向并没有被改变)。
修正:
void find2(char []array,char search,char ** ppa)
{
int i;
for (i=0;*(array+i)!=0;i++)
{
if (*(array+i)==search){
*ppa=array+i
break;
}
else if (*(array+i)==0){
*ppa=0;
break;
}
}
}主函数的调用处改如下:
find2(str,a,&p); //调用函数以实现所要操作。再分析:
这样调用函数时的整个操作变成如下:
array = str;
search = a;
ppa = &p; //请注意:以上三句是调用时隐含的动作。
int i;
for (i=0;*(array+i)!=0;i++)
{
if (*(array+i)==search) {
*ppa=array+i
break;
}
else if (*(array+i)==0) {
*ppa=0;
break;
}
}ppa指向指针p的地址。
对*ppa的修改就是对p值的修改。
经过修改后的程序就可以完成所要的功能了。
DATA:8-26
类、对象、继承、属性、方法、静态、重载、隐藏、重构、声明、定义、初始化、赋值
函数重载是指在同一作用域内,可以有一组具有相同函数名,不同参数列表的函数,这组函数被称为重载函数。重载函数通常用来命名一组功能相似的函数,这样做减少了函数名的数量,避免了名字空间的污染,对于程序的可读性有很大的好处。
一篇极好文章:http://www.cnblogs.com/skynet/archive/2010/09/05/1818636.html
DATA:8-27
当今,电子类工程师空缺量都很大,对拥有五年及以上工作经验、英语流利的资深工程技术人员的需求尤其迫切。
“工程师是科学家;工程师是艺术家;工程师也是思想家。”一位伟大的工程师曾经提出过这样的一段感言。
作为工程师和科学家想取得成功并不是比赛谁花的时间最多,而是看谁付出了更多的“思考”。
“勤奋”是大脑的勤奋,而不是身体和和形式上的勤奋。
一次别人问我你每天花多长时间来工作。我回答他:“每天除了吃饭睡觉几乎都在思考。”
一个工程师和科学家在生活中也是工程师和科学家。
工程师要有“自己的思想”。
我的意见是:不要以为拿着模电书学下去就能有本质的改变,一定要提高对事物的认识和对自然科学的理解,提高对模拟量的驾御能力。重要的是思维方式,和对概念的感性认识。
思考问题要有深度,思维的深度是一种习惯。
DATA:8-28
#define BIT3 (0x1 << 3) //每次用到记着加( )!!!!
中断服务程序需要满足如下要求:
(1)不能返回值;
(2)不能向 ISR传递参数;
(3)ISR 应该尽可能的短小精悍;
(4)printf(char* lpFormatString,…)函数会带来重入和性能问题,不能在 ISR 中采用。
多任务 OS的核心是系统调度器,它使用任务控制块(TCB)来管理任务调度功能。TCB包括任务的当前状态、优先级、要等待的事件或资源、任务程序码的起始地址、初始堆栈指针等信息。调度器在任务被激活时,要用到这些信息。此外,TCB还被用来存放任务的"上下文"(context)。任务的上下文就是当一个执行中的任务被停止时,所要保存的所有信息。通常,上下文就是计算机当前的状态,也即各个寄存器的内容。当发生任务切换时,当前运行的任务的上下文被存入 TCB,并将要被执行的任务的上下文从它的 TCB中取出,放入各个寄存器中。
记住:CPU以字节为单位编址,而 C语言指针以指向的数据类型长度作自增和自减。
DATA:8-29
当注释掉大块代码时,使用"#if0"比使用"/**/"要好,因为用"/**/"做大段的注释要防止被注释掉的代码中有嵌套的"/**/",这会导致注释掉的代码区域不是你想要的范围,当被注释掉的代码很大时容易出现这种情况,特别是过一段时间后又修改该处代码时更是如此。
在这里顺便对条件编译(#ifdef, #else, #endif, #if等)进行说明。以下分3种情况:
1. 情况1:
#ifdef _XXXX
...程序段1...
#else
...程序段2...
#endif
这表明如果标识符_XXXX已被#define命令定义过则对程序段1进行编译;否则对程序段2进行编译。
例:
#define NUM
.............
#ifdef NUM
printf("之前NUM有过定义啦!:) \n");
#else
printf("之前NUM没有过定义!:( \n");
#endif
}
如果程序开头有#define NUM这行,即NUM有定义,碰到下面#ifdef NUM的时候,当然执行第一个printf。否则第二个printf将被执行。
用这种可以很方便的开启/关闭整个程序的某项特定功能。
2:情况2:
#ifndef _XXXX
...程序段1...
#else
...程序段2...
#endif
这里使用了#ifndef,表示的是if not def。当然是和#ifdef相反的状况(如果没有定义了标识符_XXXX,那么执行程序段1,否则执行程序段2)。例子就不举了。
3:情况3:
#if 常量
...程序段1...
#else
...程序段2...
#endif
这里表示,如果常量为真(非0,随便什么数字,只要不是0),
就执行程序段1,否则执行程序段2。
如果有#if需要顶格写
DATA:8-30
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)1. ((TYPE *)0)将零转型为TYPE类型指针;
2. ((TYPE*)0)->MEMBER 访问结构中的数据成员;
3.&(((TYPE *)0)->MEMBER)取出数据成员的地址;这个实现相当于获取到了MEMBER成员相对于其所在结构体的偏移,也就是其在对应结构体中的什么位置;
4.(size_t)(&(((TYPE*)0)->MEMBER))结果转换类型。巧妙之处在于将0转换成(TYPE*),结构以内存空间首地址0作为起始地址,则成员地址自然为偏移地址。
&操作如果是对一个表达式,而不是一个标识符,会取消操作,而不是添加。
比如&*a,会直接把a的地址求出来,不会访问*a。
&a->member,会把访问a->member的操作取消,只会计算出a->member的地址。
防御式编程是提高软件质量技术的有益辅助手段。防御式编程的主要思想是:子程序应该不因传入错误数据而被破坏,哪怕是由其他子程序产生的错误数据。这种思想是将可能出现的错误造成的影响控制在有限的范围内。
#include<assert.h>
void assert( int expression );assert的作用是现计算表达式 expression,如果其值为假(即为0),那么它先向stderr打印一条出错信息,然后通过调用 abort 来终止程序运行。














 735
735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









