







转自:线程池详解_time Friend的博客-CSDN博客
略有改动
线程池(Thread Pool):把一个或多个线程通过统一的方式进行调度和重复使用的技术,避免了因为线程过多而带来使用上的开销。
为什么要使用线程池?
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。

线程池执行示意图
线程池使用
在JDK中rt.jar包下JUC(java.util.concurrent)创建线程池有两种方式:ThreadPoolExecutor 和 Executors,其中 Executors又可以创建 6 种不同的线程池类型。
ThreadPoolExecutor的使用
线程池使用代码如下:
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolDemo {
private static ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 10, 10L, TimeUnit.SECONDS, new LinkedBlockingQueue(100));
public static void main(String[] args) {
threadPoolExecutor.execute(new Runnable() {
@Override
public void run() {
System.out.println("田先生您好");
}
});
}
}
以上程序执行结果如下:
田先生您好
参数说明:
ThreadPoolExecutor中 构造方法有以下四个:
可以看到最后一个构造方法有 7 个构造参数,其实前面的三个构造方法只是对最后一个方法进行包装,并且前面三个构造方法最终都是调用最后那个构造方法,所以我们这里就来聊聊最后一个构造方法。
参数解释:
corePoolSize: 线程池中的核心线程数,默认情况下核心线程一直存活在线程池中,如果将 ThreadPoolExecutor 的 allowCoreThreadTimeOut 属性设为 true,如果线程池一直闲置并超过了 keepAliveTime 所指定的时间,核心线程就会被终止。
maximumPoolSize: 最大线程数,当线程不够时能够创建的最大线程数(包含核心线程数)
临时线程数 = 最大线程数 - 核心线程数
keepAliveTime: 线程池的闲置超时时间,默认情况下对非核心线程生效,如果闲置时间超过这个时间,非核心线程就会被回收。如果 ThreadPoolExecutor 的 allowCoreThreadTimeOut 设为 true 的时候,核心线程如果超过闲置时长也会被回收。
unit: 配合 keepAliveTime 使用,用来标识 keepAliveTime 的时间单位。
workQueue: 线程池中的任务队列,使用 execute() 或 submit() 方法提交的任务都会存储在此队列中。
threadFactory: 为线程池提供创建新线程的线程工厂。
rejectedExecutionHandler: 线程池任务队列超过最大值之后的拒绝策略, RejectedExecutionHandler 是一个接口,里面只有一个 rejectedExecution方法,可在此方法内添加任务超出最大值的事件处理;
拒绝策略定义
拒绝策略提供顶级接口 RejectedExecutionHandler ,其中方法 rejectedExecution 即定制具体的拒绝策略的执行逻辑。
jdk默认提供了四种拒绝策略:
- AbortPolicy - 抛出异常,中止任务。抛出拒绝执行 RejectedExecutionException 异常信息。线程池默认的拒绝策略。必须处理好抛出的异常,否则会打断当前的执行流程,影响后续的任务执行
- CallerRunsPolicy - 使用调用线程执行任务。当触发拒绝策略,只要线程池没有关闭的话,则使用调用线程直接运行任务。一般并发比较小,性能要求不高,不允许失败。但是,由于调用者自己运行任务,如果任务提交速度过快,可能导致程序阻塞,性能效率上必然的损失较大
- DiscardPolicy - 直接丢弃,其他啥都没有
- DiscardOldestPolicy - 丢弃队列最老任务,添加新任务。当触发拒绝策略,只要线程池没有关闭的话,丢弃阻塞队列 workQueue 中最老的一个任务,并将新任务加入
1. 临时线程什么时候创建?
新任务提交时发现核心线程都在忙,任务队列也满了,并且还可以创建临时线程, 此时才会创建临时线程;
2. 什么时候会开始拒绝任务?
核心线程和临时线程都在忙,任务队列也满了,新的任务过来的时候才会开始拒绝任务;
ExecutorService 使用 Runnable的案例:
public class MyRunnable implements Runnable{
@Override
public void run() {
for (int i = 0; i < 5; i++) {
final String name = Thread.currentThread().getName();
System.out.println(name + " 执行了:HelloWOrld==>"+i);
}
try {
System.out.println(Thread.currentThread().getName()+"---睡眠了");
Thread.sleep(10000000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
public class ThreadPoolDemo1 {
public static void main(String[] args) {
//1.创建线程池
ExecutorService pool = new ThreadPoolExecutor(
3,
5,
8,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(5),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
//2. 给任务线程池处理
Runnable target = new MyRunnable();
//核心线程
pool.execute(target);
pool.execute(target);
pool.execute(target);
//下面再执行可以看到线程复用
pool.execute(target);
pool.execute(target);
pool.execute(target);
pool.execute(target);
pool.execute(target);
//下面可以看到 创建临时线程(执行任务中加入sleep)
pool.execute(target);
pool.execute(target);
// 不创建临时线程,执行配置的拒绝策略(丢弃任务并且抛出异常)
pool.execute(target);
}
}ExecutorService 使用 Callable的案例:
Future<T> submit(Callable<T> command)
public class MyCallable implements Callable<String> {
private int n;
public MyCallable(int n) {
this.n = n;
}
/**
* 重写call方法(任务方法)
* @return
* @throws Exception
*/
@Override
public String call() throws Exception {
int sum = 0;
for (int i = 0; i <= n; i++) {
sum += i;
}
return Thread.currentThread().getName() + "执行1-"+n+"的和,结果是:"+sum;
}
}
public class ThreadPoolDemo2 {
public static void main(String[] args) throws Exception{
//1.创建线程池
ExecutorService pool = new ThreadPoolExecutor(
3,
5,
8,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(5),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
//2. 给任务线程池处理
Future f1 = pool.submit(new MyCallable(100));
Future f2 = pool.submit(new MyCallable(200));
Future f3 = pool.submit(new MyCallable(300));
Future f4 = pool.submit(new MyCallable(400));
Future f5 = pool.submit(new MyCallable(500));
System.out.println(f1.get());
System.out.println(f2.get());
System.out.println(f3.get());
System.out.println(f4.get());
System.out.println(f5.get());
}
}从上面可以看到execute() 和 submit()的使用差异:
execute() 和 submit() 都是用来执行线程池的,区别在于 submit() 方法可以接收线程池执行的返回值。execute提交的是Runnable实例,submit提交的是Callable实例。
Executors 线程池工具类:






定时器:
public class TimerDemo1 {
public static void main(String[] args) {
//1.创建timer定时器(定时器本身是一个单线程)
Timer timer = new Timer();
//2.调用方法,处理定时任务
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "执行一次");
}
}, 3000, 2000);
}
}
public class TimerDemo2 {
public static void main(String[] args) {
//1.创建ScheduledExecutorService线程池,做定时器
ScheduledExecutorService pool = Executors.newScheduledThreadPool(3);
//2. 开启定时任务
pool.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "执行输出:AAA");
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}, 0, 2, TimeUnit.SECONDS);
pool.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "执行输出:BBB");
//BBB挂了,不影响CCC的执行
System.out.println(10/0);
}
}, 0, 2, TimeUnit.SECONDS);
pool.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "执行输出:CCC");
}
}, 0, 2, TimeUnit.SECONDS);
}
}Executors
Executors 执行器创建线程池很多基本上都是在 ThreadPoolExecutor 构造方法上进行简单的封装,特殊场景根据需要自行创建。可以把Executors理解成一个工厂类。Executors可以创建6 种不同的线程池类型。
下面对这六个方法进行简要的说明:
- newFixedThreadPool: 创建一个数量固定的线程池,超出的任务会在队列中等待空闲的线程,可用于控制程序的最大并发数。
- newCacheThreadPool: 短时间内处理大量工作的线程池,会根据任务数量产生对应的线程,并试图缓存线程以便重复使用,如果限制 60 秒没被使用,则会被移除缓存。如果现有线程没有可用的,则创建一个新线程并添加到池中,如果有被使用完但是还没销毁的线程,就复用该线程。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。因此,长时间保持空闲的线程池不会使用任何资源。
- newScheduledThreadPool: 创建一个数量固定的线程池,支持执行定时性或周期性任务。
- newWorkStealingPool: Java 8 新增创建线程池的方法,创建时如果不设置任何参数,则以当前机器CPU 处理器数作为线程个数,此线程池会并行处理任务,不能保证执行顺序。
- newSingleThreadExecutor: 创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
- newSingleThreadScheduledExecutor: 此线程池就是单线程的newScheduledThreadPool。
线程池如何关闭?
线程池关闭,可以使用 shutdown() 或 shutdownNow() 方法,它们的区别是:
- shutdown():不会立即终止线程池,而是要等所有任务队列中的任务都执行完后才会终止。执行完 shutdown 方法之后,线程池就不会再接受新任务了。
- shutdownNow():执行该方法,线程池的状态立刻变成 STOP 状态,并试图停止所有正在执行的线程,不再处理还在池队列中等待的任务,执行此方法会返回未执行的任务。
面试题
1. ThreadPoolExecutor 有哪些常用的方法?
ThreadPoolExecutor有如下常用方法:
- submit()/execute():执行线程池
- shutdown()/shutdownNow():终止线程池
- isShutdown():判断线程是否终止
- getActiveCount():正在运行的线程数
- getCorePoolSize():获取核心线程数
- getMaximumPoolSize():获取最大线程数
- getQueue():获取线程池中的任务队列
- allowCoreThreadTimeOut(boolean):设置空闲时是否回收核心线程
这些方法可以用来终止线程池、线程池监控。
2. 说说submit(和 execute两个方法有什么区别?
submit() 和 execute() 都是用来执行线程池的,只不过使用 execute() 执行线程池不能有返回方法,而使用 submit() 可以使用 Future 接收线程池执行的返回值。
3. 说说线程池创建需要的那几个核心参数的含义
ThreadPoolExecutor 最多包含以下七个参数:
- corePoolSize:线程池中的核心线程数
- maximumPoolSize:线程池中最大线程数
- keepAliveTime:闲置超时时间
- unit:keepAliveTime 超时时间的单位(时/分/秒等)
- workQueue:线程池中的任务队列
- threadFactory:为线程池提供创建新线程的线程工厂
- rejectedExecutionHandler:线程池任务队列超过最大值之后的拒绝策略
4. shutdownNow() 和 shutdown() 两个方法有什么区别?
shutdownNow() 和 shutdown() 都是用来终止线程池的,它们的区别是,使用 shutdown() 程序不会报错,也不会立即终止线程,它会等待线程池中的缓存任务执行完之后再退出,执行了 shutdown() 之后就不能给线程池添加新任务了;shutdownNow() 会试图立马停止任务,如果线程池中还有缓存任务正在执行,则会抛出 java.lang.InterruptedException: sleep interrupted 异常。
5. 了解过线程池的工作原理吗?
当线程池中有任务需要执行时,线程池会判断如果线程数量没有超过核心数量就会新建线程池进行任务执行,如果线程池中的线程数量已经超过核心线程数,这时候任务就会被放入任务队列中排队等待执行;如果任务队列超过最大队列数,并且线程池没有达到最大线程数,就会新建线程来执行任务;如果超过了最大线程数,就会执行拒绝执行策略。
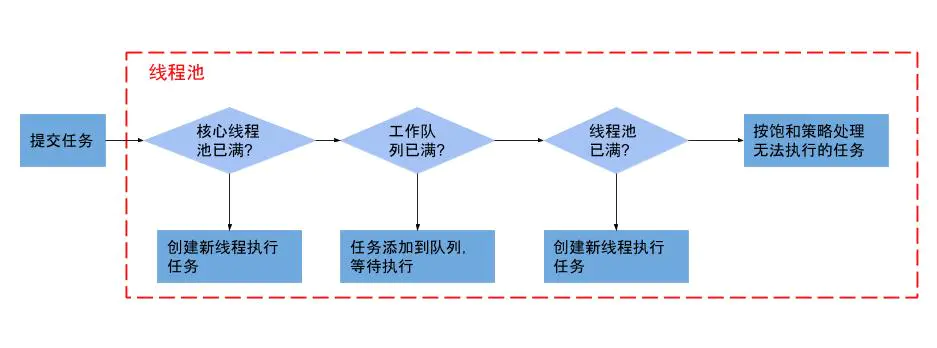
6. 线程池中核心线程数量大小怎么设置?
CPU密集型任务:比如像加解密,压缩、计算等一系列需要大量耗费 CPU 资源的任务,大部分场景下都是纯 CPU 计算。尽量使用较小的线程池,一般为CPU核心数+1。 因为CPU密集型任务使得CPU使用率很高,若开过多的线程数,会造成CPU过度切换。
IO密集型任务: 比如像 MySQL 数据库、文件的读写、网络通信等任务,这类任务不会特别消耗 CPU 资源,但是 IO 操作比较耗时,会占用比较多时间。 可以使用稍大的线程池,一般为2*CPU核心数。 IO密集型任务CPU使用率并不高,因此可以让CPU在等待IO的时候有其他线程去处理别的任务,充分利用CPU时间。
另外:线程的平均工作时间所占比例越高,就需要越少的线程;线程的平均等待时间所占比例越高,就需要越多的线程;
以上只是理论值,实际项目中建议在本地或者测试环境进行多次调优,找到相对理想的值大小。
7. 线程池为什么需要使用(阻塞)队列?
- 因为线程若是无限制的创建,可能会导致内存占用过多而产生OOM,并且会造成cpu过度切换。
- 创建线程池的消耗较高。
8. 线程池为什么要使用阻塞队列而不使用非阻塞队列?
阻塞队列可以保证任务队列中没有任务时阻塞获取任务的线程,使得线程进入wait状态,释放cpu资源。 当队列中有任务时才唤醒对应线程从队列中取出消息进行执行。 使得在线程不至于一直占用cpu资源。
(线程执行完任务后通过循环再次从任务队列中取出任务进行执行,代码片段如下 while (task != null || (task = getTask()) != null) {})。
9. 不用阻塞队列也是可以的,不过实现起来比较麻烦而已,有好用的为啥不用呢?
10. 了解线程池状态吗?
通过获取线程池状态,可以判断线程池是否是运行状态、可否添加新的任务以及优雅地关闭线程池等。
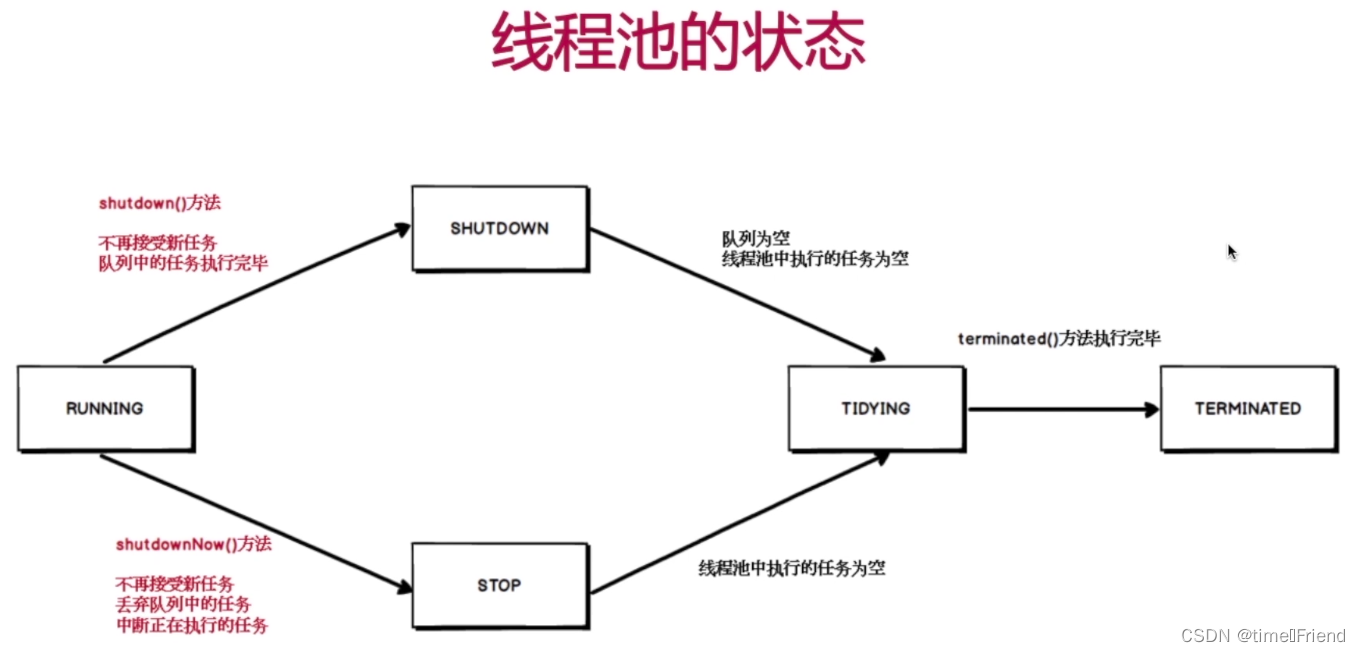
- RUNNING: 线程池的初始化状态,可以添加待执行的任务。
- SHUTDOWN:线程池处于待关闭状态,不接收新任务仅处理已经接收的任务。
- STOP:线程池立即关闭,不接收新的任务,放弃缓存队列中的任务并且中断正在处理的任务。
- TIDYING:线程池自主整理状态,调用 terminated() 方法进行线程池整理。
- TERMINATED:线程池终止状态。
11. 知道线程池中线程复用原理吗?
线程池将线程和任务进行解耦,线程是线程,任务是任务,摆脱了之前通过 Thread 创建线程时的一个线程必须对应一个任务的限制。
在线程池中,同一个线程可以从阻塞队列中不断获取新任务来执行,其核心原理在于线程池对 Thread 进行了封装,并不是每次执行任务都会调用 Thread.start() 来创建新线程,而是让每个线程去执行一个“循环任务”,在这个“循环任务”中不停的检查是否有任务需要被执行,如果有则直接执行,也就是调用任务中的 run 方法,将 run 方法当成一个普通的方法执行,通过这种方式将只使用固定的线程就将所有任务的 run 方法串联起来。
12. 你的线程池参数是如何设置的?答:一般线程池是要根据业务场景来设置线程池中的各个参数的,具体的几个重要的参数:
1、corePoolSize: 核心线程数 这个应该是最重要的参数,核心线程会一直存活,及时没有任务需要执行。 当线程数小于核心线程数时,即使有线程空闲,线程池也会优先创建新线程处理。 设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时关闭。
如何设置好需要根据项目业务是CPU密集型和IO密集型的区别。
(1)、CPU密集型 CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading 很高。 在多重程序系统中,大部分时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中绝大部分时间用在三角函数和开根号的计算,便是属于CPU bound的程序。 CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。
(2)、IO密集型 IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU Loading并不高。 I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而pipeline做得不是很好,没有充分利用处理器能力。
(3)、先看下机器的CPU核数,然后在设定具体参数: 自己测一下自己机器的核数 System.out.println(Runtime.getRuntime().availableProcessors()); 即CPU核数 = Runtime.getRuntime().availableProcessors()
(4)、分析下线程池处理的程序是CPU密集型还是IO密集型 CPU密集型:corePoolSize = CPU核数 + 1 IO密集型:corePoolSize = CPU核数 * 2
2、maximumPoolSize:最大线程数 当线程数>=corePoolSize,且任务队列已满时。线程池会创建新线程来处理任务。 当线程数=maxPoolSize,且任务队列已满时,线程池会拒绝处理任务而抛出异常。
3、keepAliveTime:线程空闲时间 当线程空闲时间达到keepAliveTime时,线程会退出,直到线程数量=corePoolSize。 如果allowCoreThreadTimeout=true,则会直到线程数量=0。
4、queueCapacity:任务队列容量(阻塞队列) 当核心线程数达到最大时,新任务会放在队列中排队等待执行
5、allowCoreThreadTimeout:允许核心线程超时
6、rejectedExecutionHandler:任务拒绝处理器
两种情况会拒绝处理任务:
当线程数已经达到maxPoolSize,且队列已满,会拒绝新任务。
当线程池被调用shutdown()后,会等待线程池里的任务执行完毕再shutdown。
如果在调用shutdown()和线程池真正shutdown之间提交任务,会拒绝新任务。 线程池会调用rejectedExecutionHandler来处理这个任务。如果没有设置默认是AbortPolicy,会抛出异常。
ThreadPoolExecutor 采用了策略的设计模式来处理拒绝任务的几种场景。
这几种策略模式都实现了RejectedExecutionHandler 接口:
- AbortPolicy - 抛出异常,中止任务。抛出拒绝执行 RejectedExecutionException 异常信息。线程池默认的拒绝策略。必须处理好抛出的异常,否则会打断当前的执行流程,影响后续的任务执行
- CallerRunsPolicy - 使用调用线程执行任务。当触发拒绝策略,只要线程池没有关闭的话,则使用调用线程直接运行任务。一般并发比较小,性能要求不高,不允许失败。但是,由于调用者自己运行任务,如果任务提交速度过快,可能导致程序阻塞,性能效率上必然的损失较大
- DiscardPolicy - 直接丢弃,其他啥都没有
- DiscardOldestPolicy - 丢弃队列最老任务,添加新任务。当触发拒绝策略,只要线程池没有关闭的话,丢弃阻塞队列 workQueue 中最老的一个任务,并将新任务加入
三、如何设置参数,线程池的默认值如下:
corePoolSize = 1
maxPoolSize = Integer.MAX_VALUE
queueCapacity = Integer.MAX_VALUE
keepAliveTime = 60s
allowCoreThreadTimeout = false
rejectedExecutionHandler = AbortPolicy()
如何来设置呢?需要根据几个值来决定:
tasks :每秒的任务数,假设为500~1000
taskcost:每个任务花费时间,假设为0.1s
responsetime:系统允许容忍的最大响应时间,假设为1s 做几个计算corePoolSize = 每秒需要多少个线程处理?
threadcount = tasks/(1/taskcost) = tasks*taskcout = (500 ~ 1000)*0.1 = 50~100 个线程。
corePoolSize设置应该大于50。
根据8020原则,如果80%的每秒任务数小于800,
- 那么corePoolSize设置为80即可: queueCapacity = (coreSizePool/taskcost) responsetime
计算可得 queueCapacity = 80/0.11 = 800。
意思是队列里的线程可以等待1s,超过了的需要新开线程来执行。
切记不能设置为Integer.MAX_VALUE,这样队列会很大,线程数只会保持在corePoolSize大小,当任务陡增时,不能新开线程来执行,响应时间会随之陡增。
- maxPoolSize 最大线程数在生产环境上我们往往设置成corePoolSize一样,这样可以减少在处理过程中创建线程的开销。
- rejectedExecutionHandler:根据具体情况来决定,任务不重要可丢弃,任务重要则要利用一些缓冲机制来处理。
- keepAliveTime和allowCoreThreadTimeout采用默认通常能满足。
以上都是理想值,实际情况下要根据机器性能来决定。如果在未达到最大线程数的情况机器cpu load已经满了,则需要通过升级硬件和优化代码,降低taskcost来处理。
然后是线程池队列的选择:
- workQueue - 当线程数目超过核心线程数时用于保存任务的队列。主要有3种类型的BlockingQueue可供选择:
无界队列,
有界队列,
同步移交。
从参数中可以看到,此队列仅保存实现Runnable接口的任务。
这里再重复一下新任务进入时线程池的执行策略:
当正在运行的线程小于corePoolSize,线程池会创建新的线程。
当大于corePoolSize而任务队列未满时,就会将整个任务塞入队列。
当大于corePoolSize而且任务队列满时,并且小于maximumPoolSize时,就会创建新额线程执行任务。
当大于maximumPoolSize时,会根据handler策略处理线程。
1、无界队列; 队列大小无限制,常用的为无界的LinkedBlockingQueue,使用该队列作为阻塞队列时要尤其当心,当任务耗时较长时可能会导致大量新任务在队列中堆积最终导致OOM。 阅读代码发现,Executors.newFixedThreadPool 采用就是 LinkedBlockingQueue,而博主踩到的就是这个坑,当QPS很高,发送数据很大,大量的任务被添加到这个无界LinkedBlockingQueue 中,导致cpu和内存飙升服务器挂掉。 当然这种队列,maximumPoolSize 的值也就无效了。 当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web 页服务器中。 这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
2、有界队列; 当使用有限的 maximumPoolSizes 时,有界队列有助于防止资源耗尽,但是可能较难调整和控制。 常用的有两类,一类是遵循FIFO原则的队列如ArrayBlockingQueue,另一类是优先级队列如PriorityBlockingQueue。 PriorityBlockingQueue中的优先级由任务的Comparator决定。 使用有界队列时队列大小需和线程池大小互相配合,线程池较小有界队列较大时可减少内存消耗,降低cpu使用率和上下文切换,但是可能会限制系统吞吐量。
3、同步移交队列;如果不希望任务在队列中等待而是希望将任务直接移交给工作线程,可使用SynchronousQueue作为等待队列。 SynchronousQueue不是一个真正的队列,而是一种线程之间移交的机制。要将一个元素放入SynchronousQueue中,必须有另一个线程正在等待接收这个元素。 只有在使用无界线程池或者有饱和策略时才建议使用该队列。














 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









