







一、查看所给的数据文件
Case 1:整个文件可以加载到内存中;
Case 2:文件太大不能加载到内存中,但<word, count>可以存放到内存中;
Case 3:文件太大无法加载到内存中,且<word, count>也不行;
二、问题规范化
将问题范化为:有一批文件(规模为TB级或者 PB级),如何统计这些文件中所有单词出现的次数;
方案:首先,分别统计每个文件中单词出现次数,然后累加不同文件中同一个单词出现次数;
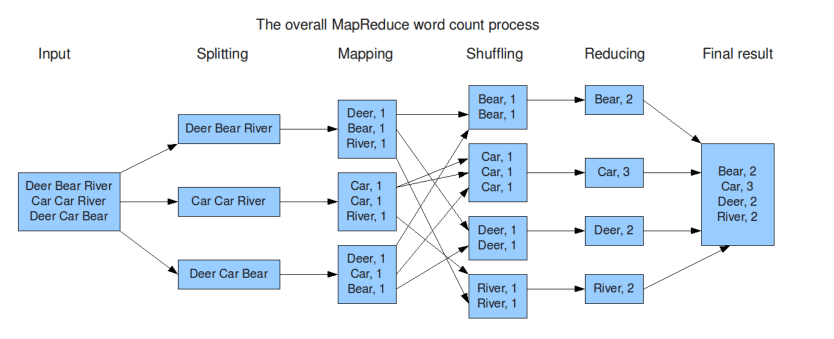
典型的MapReduce过程。
三、MapReduce编程模型—WordCount















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









