







一、什么是Zookeeper?
Zookeeper 是 Google 的 Chubby一个开源的实现,是 Hadoop 的分布式协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。
二、为什么使用Zookeeper?
1.大部分分布式应用需要一个主控、协调器或控制器来管理物理分布的子进程(如资源、任务分配等)
2.目前,大部分应用需要开发私有的协调程序,缺乏一个通用的机制
3.协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器
4.ZooKeeper:提供通用的分布式锁服务,用以协调分布式应用
三、Zookeeper能帮我们做什么?
1. Hadoop2.0,使用Zookeeper的事件处理确保整个集群只有一个活跃的NameNode,存储配置信息等.
2.HBase,使用Zookeeper的事件处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等.
四、Zookeeper的特性
1.Zookeeper是简单的,使用方便,修改配置文件即可,无需编写代码。
2.Zookeeper是富有表现力的,功能强大
3.Zookeeper具有高可用性
4.Zookeeper采用松耦合交互方式
5.Zookeeper是一个资源库
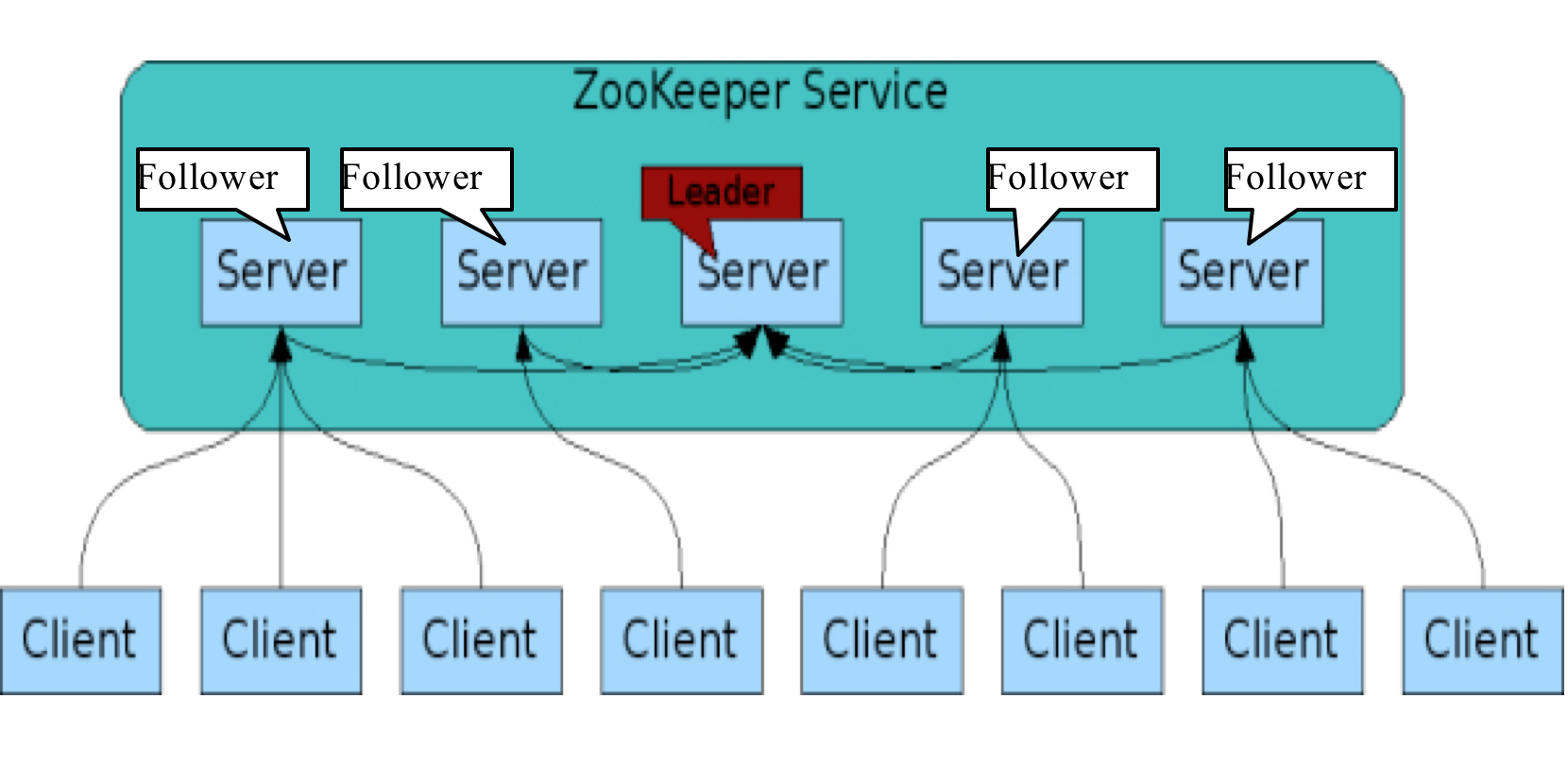
五、Zookeeper部署架构图
六、Zookeeper的安装和配置
6.1 单机模式
1.上传zk安装包(WinSCP)
2.解压
6.2 集群模式
1.上传zk安装包
2.解压
3.配置(先在一台节点上配置)
3.1添加一个zoo.cfg配置文件
$ZOOKEEPER/conf
mv zoo_sample.cfg zoo.cfg
3.2修改配置文件(zoo.cfg)
dataDir=/itcast/zookeeper-3.4.5/data
server.5=hadoop04:2888:3888
server.6=hadoop05:2888:3888
server.7=hadoop06:2888:3888
3.3在(dataDir=/cloud/zookeeper-3.4.5/data)创建一个myid文件,里面内容是server.N中的N(server.2里面内容为2)
echo "4" > myid
3.4将配置好的zk拷贝到其他节点
scp -r /itcast/zookeeper-3.4.5/ hadoop04:/cloud/
scp -r /itcast/zookeeper-3.4.5/ hadoop05:/cloud/
3.5注意:在其他节点上一定要修改myid的内容
在itcast05应该讲myid的内容改为5 (echo "5" > myid)
在itcast06应该讲myid的内容改为6 (echo "6" > myid)
4.启动集群
在每台节点上分别启动zk
./zkServer.sh start
在每台节点上分别查看zk的状态
./zkServer.sh status
【注:安装Zookeeper集群之前要确保集群中的节点防火墙彻底关闭,否则Zookeeper集群无法通信!!!】
七、Zookeeper的数据模型
1.层次化的目录结构,命名符合常规文件系统规范
2.每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
3.节点Znode可以包含数据和子节点,但是EPHEMERAL类型的节点不能有子节点【没试验】
4.Znode中的数据可以有多个版本,比如某一个路径下存有多个数据版本,那么查询这个路径下的数据就需要带上版本
5.客户端应用可以在节点上设置监视器【没试验】
6.节点不支持部分读写,而是一次性完整读写
八、Zookeeper的角色
领导者(leader),负责进行投票的发起和决议,更新系统状态。
学习者(learner),包括跟随者(follower)和观察者(observer),follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票
Observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度
客户端(client),请求发起方。
九、Zookeeper的读写机制
Zookeeper是一个由多个server组成的集群
一个leader,多个follower
每个server保存一份数据副本
全局数据一致
分布式读写
更新请求转发,由leader实施
十、Zookeeper的保证
更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行
数据更新原子性,一次数据更新要么成功,要么失败
全局唯一数据视图,client无论连接到哪个server,数据视图都是一致的
实时性,在一定事件范围内,client能读到最新数据















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









