







SQL基础
select food from diet where species='orange';一句话就能将表diet中的’orange’类的food全部选取出来,也是很神奇的!
查询操作的实现
那么SQL的查询(query)操作是如何实现的呢?
下图给出了很好的解释:
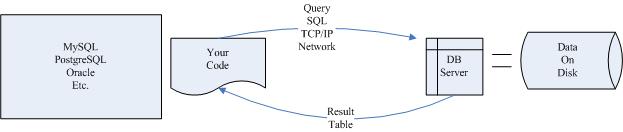
自己写的SQL语句通过网络访问数据库服务器,服务器根据这一指令进行直接查询,结果形成一个表作为返回值。也就是说,SQL语句也只不过是间接查询的途径罢了。
唯一性(uniqueness)
表中的每一个条目都是唯一的,那么如何区分呢?数据库中可以使用id进行区分不同的条目。如果每个条目是一个人的话,那么id就是人的身份证,它是区分人是否不同的权威标准。
Join Table
表animals
| name | species | birthday |
|---|---|---|
| Max | gorilla | 2001-04-13 |
| Max | moose | 2012-02-22 |
| Sue | gorilla | 1998-06-12 |
表diet
| name | food |
|---|---|
| llama | plants |
| brown bear | fish |
| brown bear | meat |
select animals.name,animals.species,diet.food from animals join diet on animals.species=diet.species where food ='fish';通常由on引导join的条件,也就是将两个表animals和diet关联起来的语句,这里要求的是animals.species 与diet.species相同。这条语句的意思就是查询吃鱼的动物的名字,种类,还有习惯的食物。
SQL中的数据类型
| 字符串类 | 数值类型 |
|---|---|
| char(n) 表示 有n 个字符的字符串 | integer 整数 |
| varchar(n) 表示 <=n个字符的字符串 | real 实数 |
| text 表示任意长度的字符串 | double precision 双精度 15位小数 |
| date 日期 | |
| time 一天的时间 | |
| timestamp 时间戳 既有日期又有时间 |
比较运算
select .... from table where statements;statements表示的是过滤条件(row restriction)
这时写这些条件语句的时候边涉及到了比较运算。
| 比较运算符 | 含义 |
|---|---|
| = | 相等 |
| < | 小于 |
| > | 大于 |
| <= | 小于等于 |
| >= | 大于等于 |
| != | 不等于 |
很简单跟编程语言一样。
常用的keywords
max 函数
select max(name) from animals;max函数返回最大值,对字符串而言,大小的比较是首先比较头字母的大小。‘a’->’z’从大到小。如果首字母相同,依次比较下一位字母,直到比较出大小,”空字符最小。
select * from animals limit 10;limit value表示显示前value个条目。
select name from animals where species='orangutan' order by birthdate;order by col 表示依据col列的值进行升序排序。
select name from animals where species='orangutan' order by birthdate desc;order by col desc 表示按col列的值降序排列。
select name, birthdate from animals order by name limit 10 offset 20;offset value 表示偏移值,这个sql语句的含义就是:按name排序得到第位20-30个含有name,birthdate的条目。
select species,min(birthdate) from animals gruop by species;group by col 表示按col列的值进行聚类,所有col列的值相同的条目算一类。
本sql语句的含义是:得到animals的种类以及每个种类中最小的生日值(年龄最大的)。
select name,count(*) as num from animals gruop by name order by num desc limit 5;count()函数统计数量
统计animals中的重名动物,并按重名的数量降序排列,得到重名数最多的前五个名字,及其数量。
插入新的行到表中
insert into tablename values(42,’staff’);
if the new values aren’t in the same order as the table’s columns:
insert into tablename(col2,col1) values(‘staff’,42);
比如在animals中插入一行2014-11-11日出生的叫wibble的oppssum类动物:
insert into animals values(‘wibble’,’oppssum’,’2014-11-11’);
Join the Table (simple join)
join 操作往往能被where替代:
比如:
假设T,S是两个表
1. select T.thing , S.stuff from T join S on T.target = S.match;
T.target 与 S.match 就像是桥梁将表T与表S连接起来了。
2. select T.thing , S.stuff from T, S where T.target = S.match;
语句1与语句2可以达到同样的效果
再举个例子:
select name from animals,diet where animals.species = diet.species and diet.food=’fish’;
select animals.name from animals join diet on animals.species = diet.species where diet.food=’fish’;
表示得到吃鱼的动物的名字。
练习时间
question1:which species does the zoo have only one of?
select species,count(*) as num from animals group by species where num=1;好吧,上面的语句是显而易见的答案,但是如果你这么认为的话,你就错了!
因为 where引导的过滤条件在count开始之前就进行过滤了,但是过滤的时候还没有num产生,这时找不到num必然报错。
用英文说一遍就是:the value of num comes from count and group by.
But where always runs before aggregations.
通过对上面错误答案的微小改动就能得到question1的正确答案。
答案是:
select species,count(*) as num from animals group by species having num=1;那么having与where的区别是?
where is a restriction on the source tables.
having is a restriction on the result after aggregation.
也就是where引导的条件表达式中的变量必须是源表(source table)中的。
question2:Find the one food the is eaten by only one animal.
answer1:
select food,count(*) as num from animals join diet on animals.species = diet group by food having num=1;answer2:
select food,count(animals.name) as num from diet,animals where nimals.species = diet group by food having num=1;Normalized Design
in a normalized database, the relationships among the tables match the relationships that are really there among the data.
| Normalized Design |
|---|
| 1.Every row has the same number of columns. |
| 2.There is a unique key, and everything in a row says something about the key. |
| 3.Facts that didn’t relate to the key belong in differnt tables. |
| 4.Tables shouldn’t imply relationship that don’t exist. |
Greate Table and Types
创建 table 的方法是:
create table tablename(
column1 type [constrains],
column2 type [constains],
…,
…,
[row constrains]);
some systems support abbreviations for long type names.
for example,
timestamptz(PostgreSQL only) = timestamp with time zone (SQL standard type name)
In generally, user facing code doesn’t usually create new tables.
日常生活中,我们一般只是在已有数据库的情况下,对数据库的表进行增删改查操作,并不会直接接触到创建数据库中的表的操作。
Creating and Dropping
Create database name[options];
drop database name[options];
drop table name[options];
在psql中具体进行的就是如下操作:
1.打开terminal:$psql
2.psql=> create database fishies;
3.psql=> \c fishies
4.psql=> create table fish(name text,id serial);
5.psql=> insert into fish values(‘papapa’,1);
Declaring Primary Keys
primary key: a column or columns that uniquely identify what each row in a table is about.
for example,
psql=> create table students(
id serial primary key,
name text,
birthdate date);
有时,也有两个key同时组成primary key.
比如,
psql=> create table post_places(
postal_code text,
country text,
name text,
primary key (post_code,country));
一旦primarykey确定了,当我们输入数据时,如果我们输入的数据中有两个item的primary key 相同,数据库会throws error。
Declaring Relationships
psql=> create table sales(
sku text references products,
sale_date date,
count integer);
products 是一个表
psql=> create table sales(
sku text references products(sku),
sale_date date,
count integer );
products(sku)是一个列
references provides referential integrity-columns that are supporsed to refer to each other are guaranteed to do so.
Foreign Keys
A foreign key is a column or set of columns in one table that uniquely identifies rows in another table.
用法举例
create table students(id serial primary key, name text);
create table courses(id text primary key,name text);
create table grades(student integer references student (id),course text references courses (id), garde text);
下面三个表中哪些列是primary key,哪些列是foreign key?
表users
| username | fullname |
|---|---|
| PrinceUtenu | TenjoUtenu |
| AvachnidGrip | ViskaSerket |
| DavFalken | DogFootal |
表posts:
| content | author | id |
|---|---|---|
| Hello! | AvachnidGrip | 1 |
| I miss u! | DavFalken | 2 |
表votes:
| post_id | voter | vote |
|---|---|---|
| 2 | DavFalken | -1 |
| 1 | AvachnidGrip | 1 |
表1中,username是作为primary key的。
表2中,id 作为primary key,author作为foreign key 并参考表1的primary key: username
表3中,post_id 作为foreign key并参考表2的primary key:id;voter作为foreign key参考表1的primary key: username.
self joins
table residences
| id | building | room |
|---|---|---|
| 413001 | crosby | 10 |
| 116128 | dolliver | 7 |
| 881256 | crosby | 10 |
create table residences(id integer references students, building text references buildings(naem), room text);question:find roommate.
select a.id,b.id from residences as a, residences as b where a.building=b.building and a.room = b.room and a.id<b.id order by a.building, a.room;left join
**A regular(inner) join returns only those rows where the two tables have entries matching the join condition.
A left join returns all those rows plus the row where the left table has an entry but the right table does not **
create table programs(name text,filename text);
create table bugs(filename text,description text,id serial primary key);question: count the number of bugs of each program.
select programs.name,count(bugs.id) as num from programs left join bugs on programs.name = bugs.filename group by programs.name order by num;Subqueries
select avg(bigscore) from (select max(score) as bigscore from mooseball group by team ) as maxer;the principle is one query, not two!
select name from players,(select avg(weight) as av from players) where weight < av;or
select name,weight from players,(select avg(weight) as av from players) as subq where weight < av;Views
A view is a select query stored in the database in a way that lets you use it like a table.
create view viewname as select ......;create view course_size as select course_id,count(*) as num from enrollment group by course_id;use view
select * from viewname where ....;delte view
drop view view_name;
















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









