







- Large-Margin Softmax Loss
参考:https://zhuanlan.zhihu.com/p/34044634
https://zhuanlan.zhihu.com/p/35027284
https://zhuanlan.zhihu.com/p/34404607
Liu W, Wen Y, Yu Z, et al. Large-Margin Softmax Loss for Convolutional Neural Networks [C]// ICML, 2016.
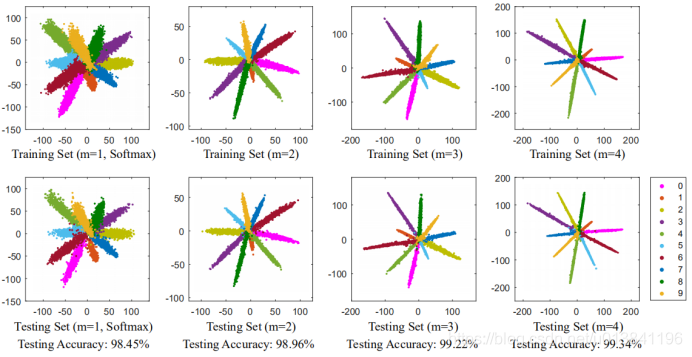
Large-Margin Softmax Loss被称为L-Softmax loss。我们先从一张图来理解下softmax loss,这张图显示的是不同softmax loss和L-Softmax loss学习到的cnn特征分布。第一列就是softmax,第2列是L-Softmax loss在参数m取不同值时的分布。通过可视化特征可知学习到的类间的特征是比较明显的,但是类内比较散。
而large-margin softmax loss则类内更加紧凑,怎么做到的呢?
最大间隔softmax loss,出发点也是类内压缩和类间分离,对于softmax loss,向量相乘可以转化为cos距离,可以改写为下式:
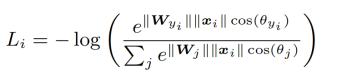
softmax loss的目的也是想让两个特征分开,但是设计上没有加强约束,其中m就是约束,是一个控制距离的变量,它越大训练会变得越困难,如下公式所示
看看二分类的情况,对于属于第1类的样本,我们希望
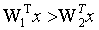
即: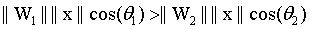
如果我们对它提出更高的要求呢? 由于cos函数在0~PI区间是递减函数,我们将要求改为

其中m>=1,
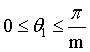 。
。
在这个条件下,原始的softmax条件仍然得到满足。
我们看下图,如果W1=W2,那么满足条件2,显然需要θ1与θ2之间的差距变得更大,原来的softmax的decision boundary只有一个,而现在类别1和类别2的decision boundary不相同,这样类间的距离进一步增加,类内更近紧凑。
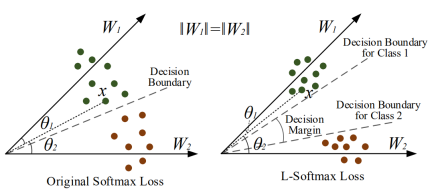
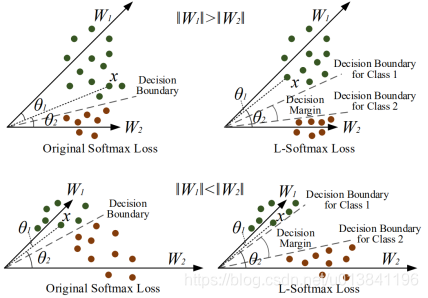
当W1和W2不等(以及x1和x2分布不均匀)时,分类会存在较大的径向偏差,L softmax 依然可以拉大类间的距离。
更具体的定义如下:
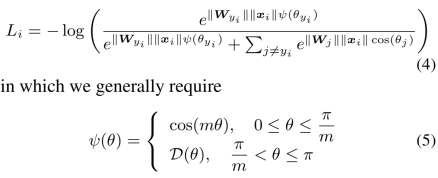
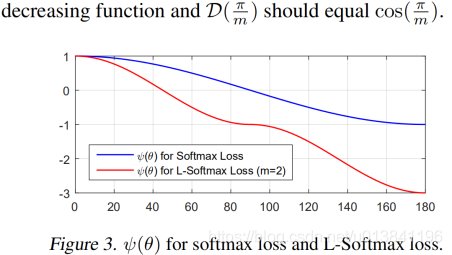
L-Softmax loss中,m是一个控制距离的变量,它越大训练会变得越困难,因为类内不可能无限紧凑。
作者的实现是通过一个LargeMargin全连接层+softmax loss来共同实现。
针对
φ
\varphi
φ函数可简化为:
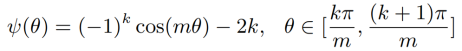
对于L-Softmax难以收敛的情况,本文进行了优化:

代码参考: https://github.com/wy1iu/LargeMargin_Softmax_Loss
注:博众家之所长,集群英之荟萃。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











