







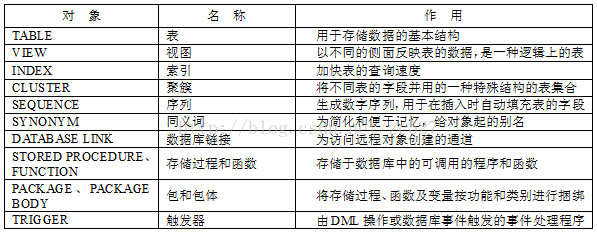
其他数据库对象
1 数据库模式对象
Oracle数据库的模式对象
2 索引
2.1 Oracle数据库的索引
索引(INDEX)是为了加快数据的查找而创建的数据库对象,特别是对大表,索引可以有效地提高查找速度,也可以保证数据的惟一性。索引是由Oracle自动使用和维护的,一旦创建成功,用户不必对索引进行直接的操作。索引是独立于表的数据库结构,即表和索引是分开存放的,当删除索引时,对拥有索引的表的数据没有影响。
在创建PRIMARY KEY和UNIQUE约束条件时,系统将自动为相应的列创建惟一(UNIQUE)索引。索引的名字同约束的名字一致。
索引有两种:B*树索引和位图(BITMAP)索引。
B*树索引是通常使用的索引,也是默认的索引类型。在这里主要讨论B*树索引。B*树是一种平衡2叉树,左右的查找路径一样。这种方法保证了对表的任何值的查找时间都相同。
B*树索引可分为:惟一索引、非惟一索引、一列简单索引和多列复合索引。
创建索引一般要掌握以下原则:只有较大的表才有必要建立索引,表的记录应该大于50条,查询数据小于总行数的2%~4%。虽然可以为表创建多个索引,但是无助于查询的索引不但不会提高效率,还会增加系统开销。因为当执行DML操作时,索引也要跟着更新,这时索引可能会降低系统的性能。一般在主键列或经常出现在WHERE子句或连接条件中的列建立索引,该列称为索引关键字。
2.2 索引的创建
创建索引不需要特定的系统权限。建立索引的语法如下:
CREATE [{UNIQUE|BITMAP}] INDEX 索引名 ON 表名(列名1[,列名2,...]);
其中:
UNIQUE代表创建惟一索引,不指明为创建非惟一索引。
BITMAP 代表创建位图索引,如果不指明该参数,则创建B*树索引。
列名是创建索引的关键字列,可以是一列或多列。
删除索引的语法是:
DROP INDEX 索引名;
删除索引的人应该是索引的创建者或拥有DROP ANY INDEX系统权限的用户。索引的删除对表没有影响。
【训练1】 创建和删除索引。
步骤1:创建索引:
CREATE INDEX EMP_ENAME ON EMP(ENAME);
执行结果:
索引已创建。
步骤2:查询中引用索引:
SELECT ENAME,JOB,SAL FROM EMP WHERE ENAME='SCOTT';
执行结果:
ENAME JOB SAL
------------ ------------------- --------------------
SCOTT ANALYST 3000
步骤3:删除索引:
DROP INDEX EMP_ENAME;
执行结果:
索引已丢弃。
说明:本例创建的是B*树非惟一简单索引。索引关键字列是ENAME。在步骤2中,因为WHERE条件中出现了索引关键字,所以查询中索引会被自动引用,
但是由于行数很少,因此不会感觉到查询速度的差别。
【训练2】 创建复合索引。
步骤1:创建复合索引:
CREATE INDEX EMP_JOBSAL ON EMP(JOB,SAL);
执行结果:
索引已创建。
步骤2:查询中引用索引:
SELECT ENAME,JOB,SAL FROM EMP WHERE JOB='MANAGER'AND SAL>2500;
执行结果:
ENAME JOB SAL
-------------- --------------------- -----------------
BLAKE MANAGER 2850
CLARK MANAGER 2850
JONES MANAGER 2975
说明:在本例中创建的是包含两列的复合索引。JOB是主键,SAL是次键。WHERE条件中引用了JOB和SAL,而且是按照索引关键字出现的顺序引用的,
所以在查询中,索引会被引用。
如下的查询也会引用索引:
SELECT ENAME,JOB,SAL FROM EMP WHERE JOB='CLERK';
但以下查询不会引用索引,因为没有先引用索引关键字的主键:
SELECT ENAME,JOB,SAL FROM EMP WHERE SAL>2500;
2.3 查看索引
通过查询数据字典USER_INDEXES可以检查创建的索引。
通过查询数据字典USER_IND_COLUMNS可以检查索引的列。
训练1】 显示emp表的索引:
SELECT INDEX_NAME, INDEX_TYPE, UNIQUENESS FROM USER_INDEXES WHERE TABLE_NAME='EMP';
执行结果:
INDEX_NAME
-------------------------------------- ---------------------------------------- -----------------------------------
EMP_JOBSAL NORMAL NONUNIQUE
PK_EMP NORMAL UNIQUE
说明:由本训练可见,emp表共有两个索引,其中EMP_JOBSAL是刚刚创建的,属于非惟一索引。PK_EMP为生成主键时系统创建的索引,属于惟一索引。
【训练2】 显示索引的列。
SELECT COLUMN_NAME FROM USER_IND_COLUMNS
WHERE INDEX_NAME='EMP_JOBSAL';
执行结果:
COLUMN_NAME
--------------------------------------------------------------------------------
JOB
SAL
说明:该查询显示出索引“EMP_JOBSAL”拥有两列:JOB和SAL。
3 序列
3.1 序列的创建
序列(SEQUENCE)是序列号生成器,可以为表中的行自动生成序列号,产生一组等间隔的数值(类型为数字)。其主要的用途是生成表的主键值,可以在插入语句中引用,也可以通过查询检查当前值,或使序列增至下一个值。
创建序列需要CREATE SEQUENCE系统权限。 序列的创建语法如下:
CREATE SEQUENCE 序列名
[INCREMENT BY n]
[START WITH n]
[{MAXVALUE n|NOMAXVALUE}]
[{MINVALUE n|NOMINVALUE}]
[{CYCLE|NOCYCLE}]
[{CACHE n|NOCACHE}];
其中:
INCREMENT BY 用于定义序列的步长,如果省略,则默认为1,如果出现负值,则代表序列的值是按照此步长递减的。
START WITH 定义序列的初始值(即产生的第一个值),默认为1。
MAXVALUE 定义序列生成器能产生的最大值。选项NOMAXVALUE是默认选项,代表没有最大值定义,这时对于递增序列,系统能够产生的最大值是10的27次方;对于递减序列,最大值是-1。
MINVALUE定义序列生成器能产生的最小值。选项NOMAXVALUE是默认选项,代表没有最小值定义,这时对于递减序列,系统能够产生的最小值是?10的-26次方;对于递增序列,最小值是1。
CYCLE和NOCYCLE 表示当序列生成器的值达到限制值后是否循环。CYCLE代表循环,NOCYCLE代表不循环。如果循环,则当递增序列达到最大值时,循环到最小值;对于递减序列达到最小值时,循环到最大值。如果不循环,达到限制值后,继续产生新值就会发生错误。
CACHE(缓冲)定义存放序列的内存块的大小,默认为20。NOCACHE表示不对序列进行内存缓冲。对序列进行内存缓冲,可以改善序列的性能。
删除序列的语法是:
DROP SEQUENCE 序列名;
删除序列的人应该是序列的创建者或拥有DROP ANY SEQUENCE系统权限的用户。序列一旦删除就不能被引用了。
序列的某些部分也可以在使用中进行修改,但不能修改SATRT WITH选项。对序列的修改只影响随后产生的序号,已经产生的序号不变。
修改序列的语法如下:
ALTER SEQUENCE 序列名 [INCREMENT BY n][{MAXVALUE n|NOMAXVALUE}][{MINVALUE n|NOMINVALUE}][{CYCLE|NOCYCLE}]
[{CACHE n|NOCACHE}];
【训练1】 创建和删除序列。
步骤1:创建序列:
CREATE SEQUENCE ABC INCREMENT BY 1 START WITH 10 MAXVALUE 9999999 NOCYCLE NOCACHE;
执行结果:
序列已创建。
步骤2:删除序列:
DROP SEQUENCE ABC;
执行结果:
序列已丢弃。
说明:以上创建的序列名为ABC,是递增序列,增量为1,初始值为10。该序列不循环,不使用内存。没有定义最小值,默认最小值为1,最大值为9 999 999。
3.2 序列的使用
如果已经创建了序列,怎样才能引用序列呢?方法是使用CURRVAL和NEXTVAL来引用序列的值。
调用NEXTVAL将生成序列中的下一个序列号,调用时要指出序列名,即用以下方式调用:
序列名.NEXTVAL
CURRVAL用于产生序列的当前值,无论调用多少次都不会产生序列的下一个值。如果序列还没有通过调用NEXTVAL产生过序列的下一个值,先引用CURRVAL没有意义。调用CURRVAL的方法同上,要指出序列名,即用以下方式调用:
序列名.CURRVAL.
【训练1】 产生序列的值。
步骤1:产生序列的第一个值:
SELECT ABC.NEXTVAL FROM DUAL;
执行结果:
NEXTVAL
------------------
10
步骤2:产生序列的下一个值:
SELECT ABC.NEXTVAL FROM DUAL;
执行结果:
NEXTVAL
-------------------
11
步骤3:产生序列的当前值:
SELECT ABC.CURRVAL FROM DUAL;
执行结果:
CURRVAL
--------------------
11
说明:第一次调用NEXTVAL产生序列的初始值,根据定义知道初始值为10。第二次调用产生11,因为序列的步长为1。
调用CURRVAL,显示当前值11,不产生新值。
【训练2】 序列的应用:产生图书序列号。
步骤1:创建序列:
CREATE SEQUENCE BOOKID INCREMENT BY 1 START WITH 10 MAXVALUE 9999999 NOCYCLE NOCACHE;
执行结果:
序列已创建。
步骤2:使用序列生成新的图书编号:
INSERT INTO 图书 VALUES('A'||TO_CHAR(BOOKID.NEXTVAL, 'fm0000'), '多媒体制作', '01', '高建',3,28.00);
INSERT INTO 图书 VALUES(‘A’||TO_CHAR(BOOKID.NEXTVAL, ‘fm0000’), ‘网页制作精选’,‘01’,‘刘莹’,4,26.50);
执行结果:
已创建 1 行。
已创建 1 行。
步骤2:显示插入结果:
SELECT * FROM 图书;
执行结果:
图书 图书名称 出 作者 数量 单价
------- --------------------------------------------- ------------------------ ------------------- -----------
A0001 计算机原理 01 刘勇 5 25.3
A0002 C语言程序设计 02 马丽 1 18.75
A0003 汇编语言程序设计 02 黄海明 15 20.18
A0005 软件工程 01 冯娟 5 27.3
A0010 多媒体制作 01 高建 3 28
A0011 网页制作精选 01 刘莹 4 26.5
说明:根据序列定义可知,序列产生的初始值为10,函数TO_CHAR将数字10转换为字符。格式字符串“fm0000”表示转换为4位的字符串,
空位用0填充。fm表示去掉转换结果的空格。故10将被转换成为字符串“0010”。连接运算后的图书编号为“A0010”。第二次调用则产生“A0011”,
以此类推。
注意:通过查询看到插入的序号是连续的,但如果在插入的过程中使用了回退或发生了系统崩溃等情况,可能会产生序号的间隔。
3.3 查看序列
同过数据字典USER_OBJECTS可以查看用户拥有的序列。
通过数据字典USER_SEQUENCES可以查看序列的设置。
【训练1】 查看用户的序列:
SELECT SEQUENCE_NAME,MIN_VALUE,MAX_VALUE,INCREMENT_BY,LAST_NUMBER FROM
USER_SEQUENCES;
执行结果:
SEQUENCE_NAME MIN_VALUE MAX_VALUE INCREMENT_BY LAST_NUMBER
------------------------------------ ------------------- --------------------- ----------------------- ----------------------
ABC 1 9999999 1 12
BOOKID 1 9999999 1 12
说明:当前用户拥有两个序列:ABC和BOOKID。
4 同义词
4.1 模式对象的同义词
同义词(SYNONYM)是为模式对象起的别名,可以为表、视图、序列、过程、函数和包等数据库模式对象创建同义词。同义词有两种:公有同义词和私有同义词。公有同义词是对所有用户都可用的。创建公有同义词必须拥有系统权限CREATE PUBLIC SYNONYM;创建私有同义词需要CREATE SYNONYM系统权限。私有同义词只对拥有同义词的账户有效,但私有同义词也可以通过授权,使其对其他用户有效。同义词通过给本地或远程对象分配一个通用或简单的名称,隐藏了对象的拥有者和对象的真实名称,也简化了SQL语句。
如果同义词同对象名称重名,私有同义词又同公有同义词重名,那么,识别的顺序是怎样的呢?如果存在对象名,则优先识别,其次识别私有同义词,最后识别公有同义词。比如,执行以下的SELECT语句:
SELECT * FROM ABC;
如果存在表ABC,就对表ABC执行查询语句;如果不存在表ABC,就去查看是否有私有同义词ABC,如果有就对ABC执行查询(此时ABC是另外一个表的同义词);如果没有私有同义词ABC,则去查找公有同义词;如果找不到,则查询失败。
4.2 同义词的创建和使用
同义词的创建语法如下:
CREATE [PUBLIC] SYNONYM 同义词名 FOR [模式名.]对象名[@数据库链路名];
其中:
PUBLIC代表创建公有同义词,若省略则代表创建私有同义词。
模式名代表拥有对象的模式账户名。
数据库链路名是指向远程对象的数据库链接。
删除同义词的语法如下
DROP SYNONYM 同义词名;
删除同义词的人必须是同义词的拥有者或有DROP ANY SYNONYM权限的人。删除同义词不会删除对应的对象。
【训练1】 创建同义词。
步骤1:创建私有同义词:
CREATE SYNONYM BOOK FOR 图书;
执行结果:
同义词已创建。
步骤2:创建公有同义词(先要获得创建公有同义词的权限):
CREATE PUBLIC SYNONYM BOOK FOR SCOTT.图书;
执行结果:
同义词已创建。
Oracle数据库模式对象

【训练1】 查看用户拥有的表:
SELECT TABLE_NAME FROM TABS;
执行结果:
TABLE_NAME
------------------------------
BONUS
DEPT
EMP
步骤3:使用同义词:
SELECT * FROM BOOK;
执行结果:
图书 图书名称 出 作者 数量 单价
-------- ---------------------------------------------- --- --------------- ------------- -----------
A0001 计算机原理 01 刘勇 5 25.3
A0002 C语言程序设计 02 马丽 1 18.75
A0003 汇编语言程序设计 02 黄海明 15 20.18
A0005 软件工程 01 冯娟 5 27.3
A0010 多媒体制作 01 高建 3 28
A0011 网页制作精选 01 刘莹 4 26.5
说明:对“BOOK”的查询等效于对“图书”的查询。如果同义词只是用户自己使用,则对象名前的模式名可以省略,如步骤1。
如果是为其他用户使用,则必须添加模式名,如步骤2。
4.3 同义词的查看
通过查询数据字典USER_OBJECTS和USER_SYNONYMS,可以查看同义词信息。
【训练1】 查看用户拥有的同义词:
SELECT OBJECT_NAME FROM USER_OBJECTS WHERE OBJECT_TYPE='SYNONYM';
执行结果:
OBJECT_NAME
--------------------------------------------------------------------------------
BOOK
QHBOOK
4.4 系统定义同义词
系统为常用的对象预定义了一些同义词,利用它们可以方便地访问用户的常用对象。
5 聚簇
所谓聚簇(CLUSTER),形象地说,就是生长在一起的表。聚簇包含一张或多张表,表的公共列被称为聚簇关键字,在公共列上具有同一值的列物理上存储在一起。那么在什么情况下需要创建聚簇呢?通常在多个表有共同的列时,应使用聚簇。比如有一张学生基本情况表,其中包含学生的学号、姓名、性别、住址等信息。另外,还设计了一张学生成绩表,其中除了包含学生成绩,也包含学生的学号、姓名、性别。那么这两张表共同的列就可以创建成聚簇。这样两张表的共同的学号、姓名和性别,就存放在了一起,相同的值只存放一次。如果两个表通过聚簇列进行联合,则会大大提高查询的速度,但对于插入等操作则会降低效率。
创建聚簇后,要创建使用聚簇的表,对聚簇还应该建立索引。如果不对聚簇建立索引,则不能对聚簇表进行插入、修改和删除操作。
创建聚簇需要CREATE CLUSTER系统权限。创建聚簇的语法如下:
CREATE CLUSTER 聚簇名(列名1 [,列名2]...)SIZE nTABLESPACE 表空间名;
列名是构成聚簇关键字的列集合。
SIZE 指明存储所有含有相同聚簇关键字的行的平均存储空间数(聚簇逻辑块的大小)。
TABLESPACE定义聚簇使用的表空间。
删除聚簇使用如下语法:
DROP CLUSTER 聚簇名 [INCLUDING TABLES [CASCADE CONSTRAINTS]];
其中:
INCLUDING TABLES表示一同删除聚簇表。如果不指明此选项,则必须手工删除聚簇表后才能删除聚簇本身。
CASCADE CONSTRAINTS表示删除聚簇表时,一起删除同其他表之间的约束关系。
【训练1】 创建和使用聚簇。
步骤1:创建聚簇:
CREATE CLUSTER COMM(STUNO NUMBER(5),STUNAME VARCHAR2(10),SEX VARCHAR2(2))
SIZE 500
TABLESPACE USERS;
执行结果:
已创建数据簇。
步骤2:创建第一张聚簇表:
CREATE TABLE STUDENT(
STUNO NUMBER(5),
STUNAME VARCHAR2(10),
SEX VARCHAR2(2),
ADDRESS VARCHAR2(20),
E_MAIL VARCHAR2(20)
)
CLUSTER COMM(STUNO,STUNAME,SEX);
执行结果:
表已创建。
步骤3:创建第二张聚簇表:
CREATE TABLE SCORE(
STUNO NUMBER(5),
STUNAME VARCHAR2(10),
SEX VARCHAR2(2),
CHINESE NUMBER(3),
MATH NUMBER(3),
ENGLISH NUMBER(3) )
CLUSTER COMM(STUNO,STUNAME,SEX);
执行结果:
表已创建。
步骤4:为聚簇创建索引:
CREATE INDEX INX_COMM ON CLUSTER COMM;
步骤5:向表中插入数据:
INSERT INTO STUDENT VALUES(10001,'黄凯','男','宝安','HK123@163.COM');
INSERT INTO STUDENT VALUES(10002,'苏丽','女','罗湖','SL99@163.COM');
INSERT INTO STUDENT VALUES(10003,'刘平平','男','南山','PP2003@SHOU.COM');
INSERT INTO SCORE VALUES(10001,'黄凯','男',70,85,93);
INSERT INTO SCORE VALUES(10002,'苏丽','女',65,74,83);
INSERT INTO SCORE VALUES(10003,'刘平平','男',88,75,69);
步骤6:删除聚簇及聚簇表:
DROP CLUSTER COMM INCLUDING TABLES CASCADE CONSTRAINTS;
执行结果:
数据簇已丢弃。
说明:在本例的两个表中,为其三个共同列STUNO、STUNAME和SEX创建了聚簇,在创建表时说明了使用的聚簇,创建聚簇后为其创建了索引,
然后插入了一些数据。
6 数据库链接
数据库链接(DATABASE LINK)是在分布式环境下,为了访问远程数据库而创建的数据通信链路。数据库链接隐藏了对远程数据库访问的复杂性。通常,我们把正在登录的数据库称为本地数据库,另外的一个数据库称为远程数据库。有了数据库链接,可以直接通过数据库链接来访问远程数据库的表。常见的形式是访问远程数据库固定用户的链接,即链接到指定的用户, 创建这种形式的数据库链接的语句如下:
CREATE DATABASE LINK 链接名 CONNECT TO 账户 IDENTIFIED BY 口令 USING 服务名;
创建数据库链接,需要CREATE DATABASE LINK系统权限。
数据库链接一旦建立并测试成功,就可以使用以下形式来访问远程用户的表。
表名@数据库链接名
【训练1】 在局域网上创建和使用数据库链接。
步骤1:创建远程数据库的服务名,假定局域网上另一个数据库服务名为MYDB_REMOTE。
步骤2:登录本地数据库SCOTT账户,创建数据库链接:
CONNECT SCOTT/TIGER@MYDB
CREATE DATABASE LINK abc CONNECT TO scott IDENTIFIED BY tiger USING 'MYDB_REMOTE';
执行结果为:
数据库链接已创建。
步骤3:查询远程数据库的数据:
SELECT * FROM emp@abc;
结果略。
步骤4:一个分布查询:
SELECT ename,dname FROM emp@abc e,dept d WHERE e.deptno=d.deptno;
结果略。
说明:在本例中,远程数据库服务名是MYDB_REMOTE,创建的数据库链接名称是abc.emp@abc表示远程数据库的emp表。步骤4是一个联合查询,
数据来自本地服务器的dept表和远程服务器的emp表















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









