




文章目录
ElasticSearch - 快速入门之核心概念知多少
1.核心概念介绍
首先我们先回顾一下我们在使用Mysql时进行数据存储一般我们都会是这样一个流程:
建立数据库-建表-插入/更新数据-查询。
ElasticSearch的使用其实也大体类似,在使用之前需要先对其有一个大致的了解,这里我们就先来了解一下几个核心概念。
索引(Index)
类似于Mysql中的Database。在Es中被视为单独的一个索引(index)。在分布式体系中,ElasticSearch会用到分片(shards)和备份(replicas)机制将一个索引(index)存储多份。类型(Type)
类似于Mysql数据库中的Table表,Es中可以在Index中建立Type,通过Mapping进行映射。需要注意的是,ES 7.x之后已移除Type概念。文档(Document)
由于Es存储的数据是文档型,一条数据对应一个文档即相当于Mysql中的一行数据。一个文档可以有多个字段即Mysql中一行可以有多列。字段(Field)
相当于Mysql中表的字段。映射(Mapping)
定义了每个字段的类型等信息,相当于关系型数据库中的表结构。
有些文档(Document)在存储前必须经过分析(Analyze)流程。用户可以配置输入文本分解成Token的方式;哪些Token应该被过滤掉;或其它的处理流程,比如去除HTML标签等。
此外,Es提供的各种特性,比如排序的相关信息。如何根据上述配置信息对数据进行保存,这就是参数映射(Mapping)在Es中扮演的角色。
尽管Es可以根据域的值自动识别域的类型(Field/Type)。但在生产应用中,都需要自己配置这些信息以避免一些奇怪的问题发生。要保证应用的可控性。建立索引(Indexed)
Mysql中一般会对经常使用的列增加相应的索引用于提高查询速度。而在Es中默认都会加上索引,除非特殊制定不建立索引只是进行存储用于展示。查询语句(Query DSL)
类似于Mysql数据库中的Sql语句,只不过在Es中是使用的Json格式查询语句。集群(Cluster)
集群由一个或多个节点组成节点(Node)
集群的节点,一台机器或一个进程分片和副本(Shard/Replica)
副本是分⽚的副本。分⽚有主分⽚(Primary Shard)和副本分⽚(Replica Shard)之分。
⼀个Index数据在物理上被分布在多个主分⽚中,每个主分⽚只存放部分数据。
每个主分⽚可以有多个副本,叫副本分⽚,是主分⽚的复制。
2.RESTful API
RESTful是一种架构风格,是一种规范、约束和设计原则而不是标准。主要用于客户端和服务端交互类应用,基于该风格设计的应用可以更简洁、更有层次、更易于实现缓存等机制。目前主流的三种Web服务交互方案中,REST相比于SOAP以及XML-RPC更加简洁明。
Representational State Transfer是指表达性状态传递,它使用典型的HTTP方法,例如GET/POST/DELETE/PUT来实现资源获取/添加/修改/删除等操作。即通过HTTP动词来实现资源的状态传递:
资源是REST系统的核心概念,所有设计都是以资源为中心。ES就是使用RESTful风格API来进行设计的。
| action | description |
|---|---|
| HEAD | 获取某个资源头部信息 |
| GET | 获取资源 |
| POST | 创建或更新资源 |
| PUT | 创建或更新资源 |
| DELETE | 删除资源 |
我们用一个简单的例子让大家更简单感受一下。
- GET => /user : 列出所有用户
- POST => /user : 新建一个用户
- PUT => /user : 更新某个用户的信息
- DELETE => /user/{userId} : 删除某个用户
3.Curl命令
在真正安装使用ElasticSearch前,我们先稍回顾一下Curl命令。这个命令相信大部分同学都早就已经使用甚至很熟练,这里只做简单带过一下基本使用。
curl是以命令的方式执行HTTP协议的请求 GET/POST/PUT/DELETE
- 例如访问一个网页
curl www.baidu.com
curl -o example.html www.baidu.com- 显示响应头部信息
curl -i www.example.com- 显示一次HTTP请求的通信过程
curl -v www.example.com- 执行GET/POST/PUT/DELETE请求
curl -X GET www.example.com
我们可以通过curl的方式去对ES进行操作,但是现在工具这么方便的情况下,大家应该还是用工具较多。curl指令大家有兴趣可以自己尝试一下。
4.索引的介绍和使用
4.1 新建索引
我们开始介绍了,索引就类似我们Mysql里面的数据库。这里我会介绍一些常用的命令,先来新建一个索引感受一下。
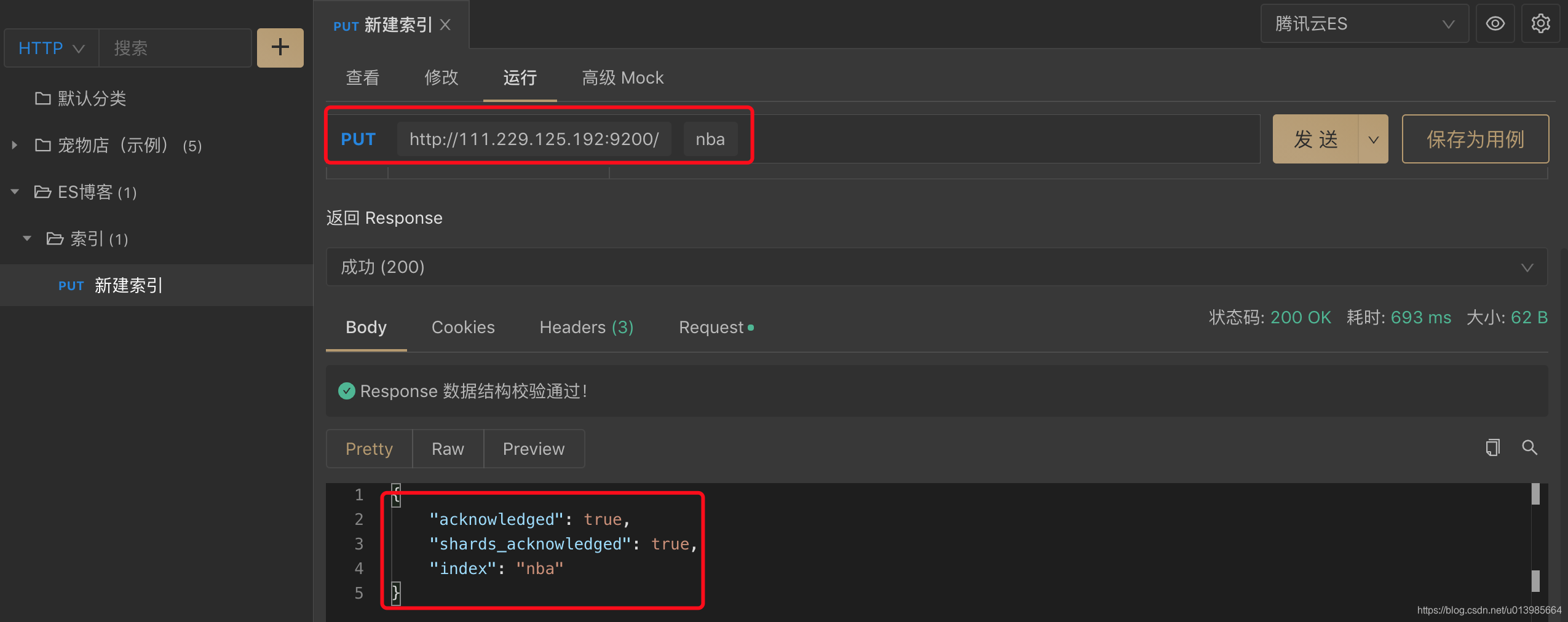
我们可以通过开始说的curl -X PUT "ip:9200/nba"命令;也可以通过一些工具,类似Postman、Apifox。
从相应"acknowledged": true来可以看到,我们的索引这就新建成功了,十分简单。
我这里本身是想使用Apifox进行后续所有操作的管理,然后导出来方便给到大家。但是想了一下还是希望如果大家是刚接触ES的话还是最好自己去动手敲一敲,所以后面我统一使用之前我们搭的Kibana进行操作,没有搭好的同学可以看之前博客。
4.2 获取索引
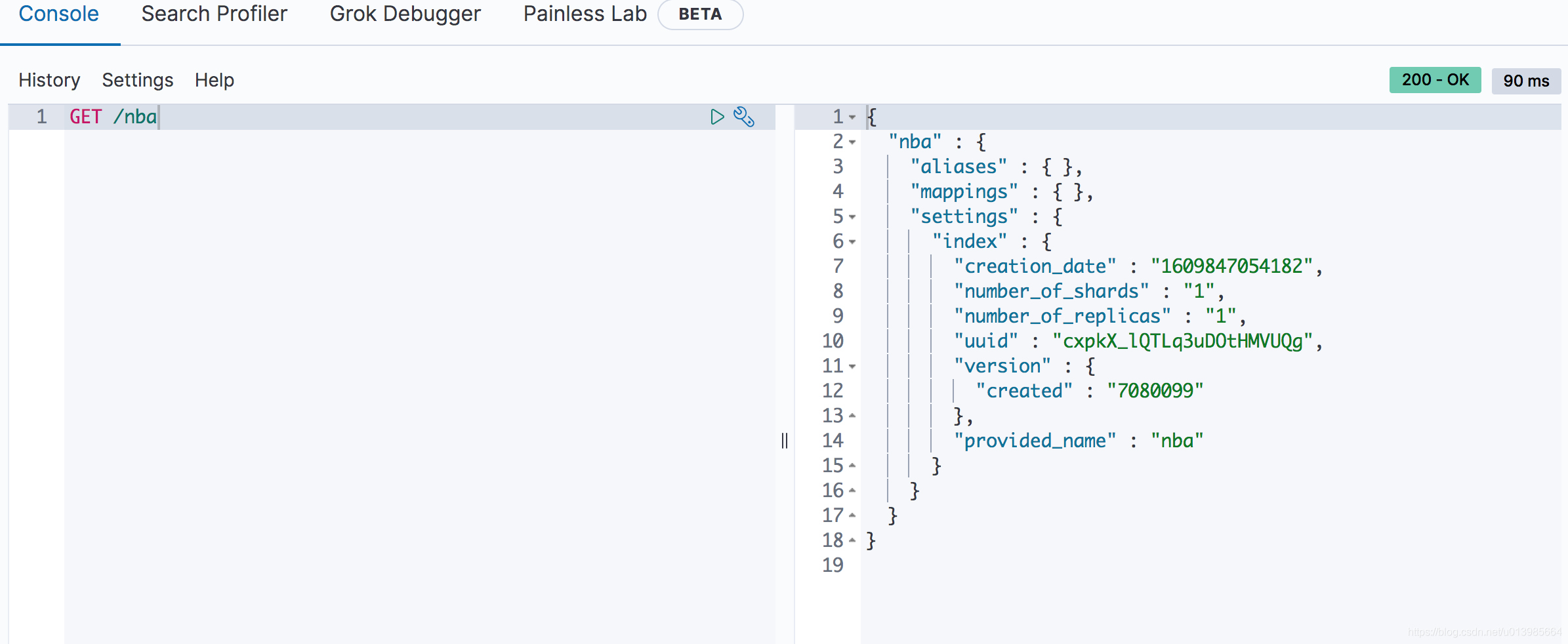
上面我们很轻松就新建了一个索引。通过我们之前的了解,只需要将请求方式修改为
GET就能获取索引了。
这里我们无需每次都去输入完整的ip:port,在搭建kibana时我们就已经配置好了。
这里从响应结果我们可以看到nba这个索引的一些基本信息,这里面包括一些别名、映射、配置、索引的分片和副本、版本等各种信息。这里我们先不关心这些信息具体是什么,后面使用到了会详细介绍。
4.3 删除索引
删除索引也十分简单,改成
DELETE请求即可。

4.4 批量获取索引
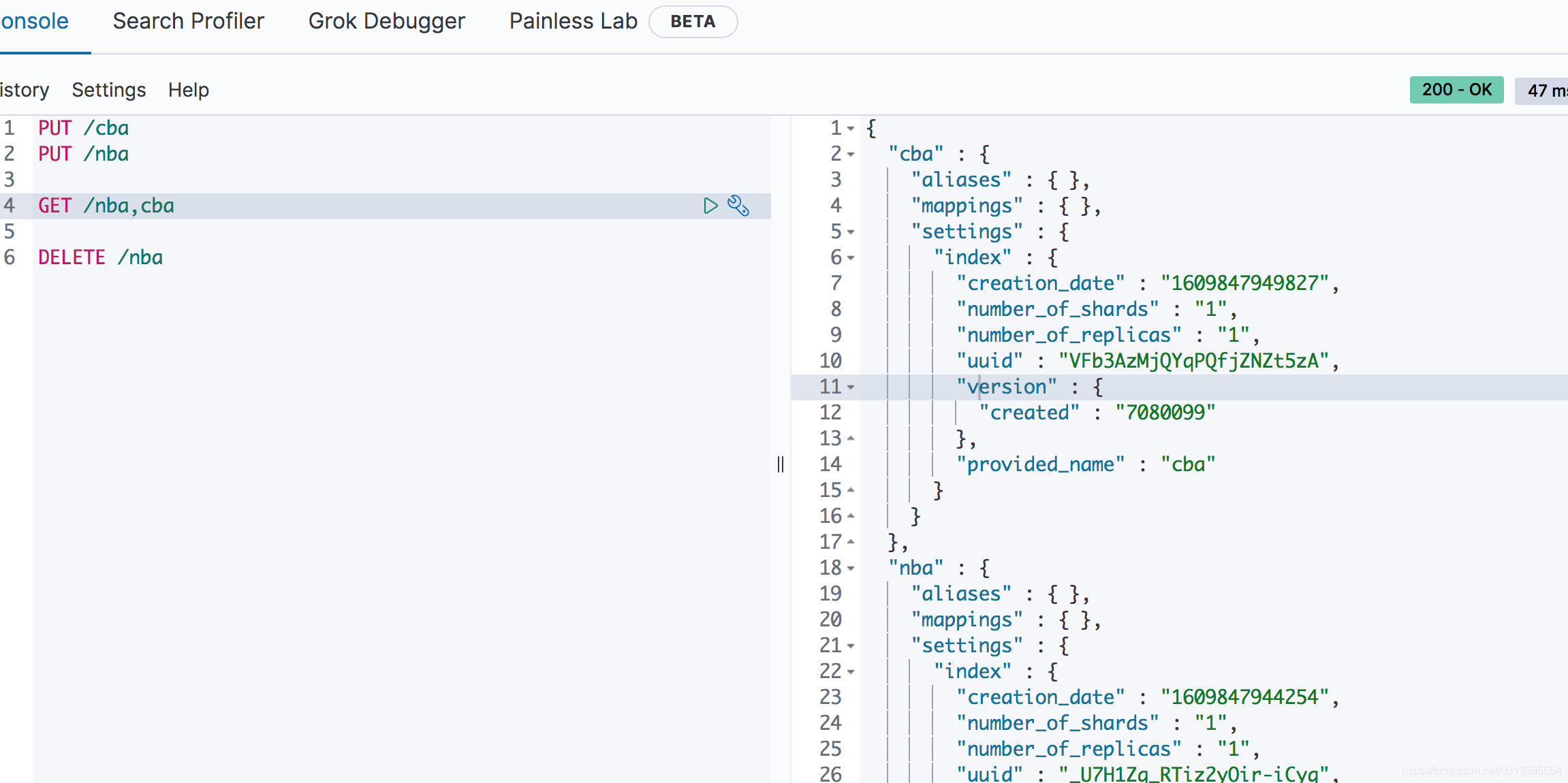
我们还可以通过
/nba,cba多个索引名同时获取多个索引信息。
4.5 获取所有索引
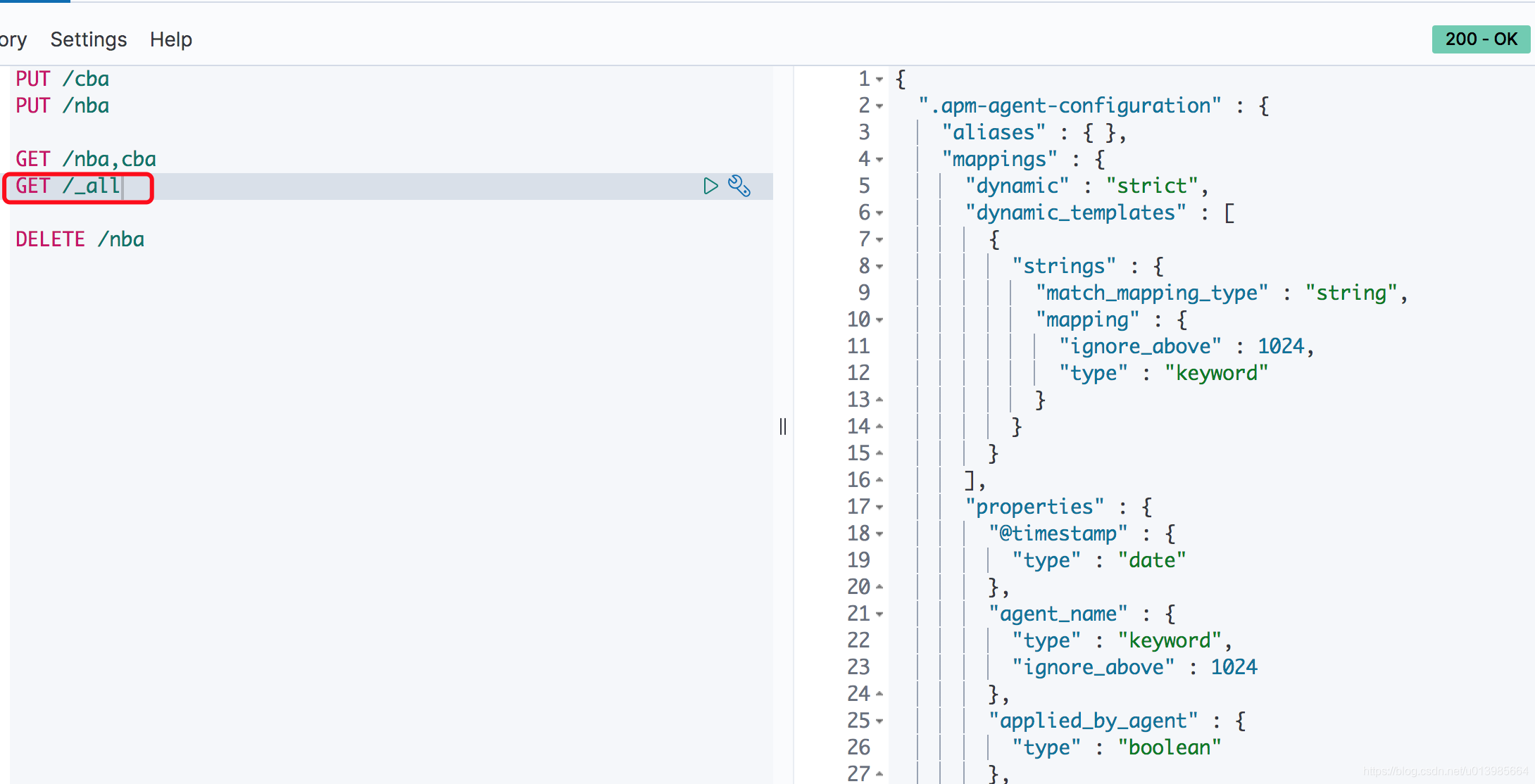
我们还可以通过
/_all获取所有的索引。不过需要注意的是这里不但会获取我们自建的索引,还会返回一些其他和配置相关或和其他工具相关的索引,例如kibana启动时就会向ES中新建索引。
4.6 查看ES状态
除了对索引操作的一些命令以外,我们还可以通过
/_cat/indices?v查看ES的运行状态。
这里看过去不是很清晰,我们单独拉出来看看。
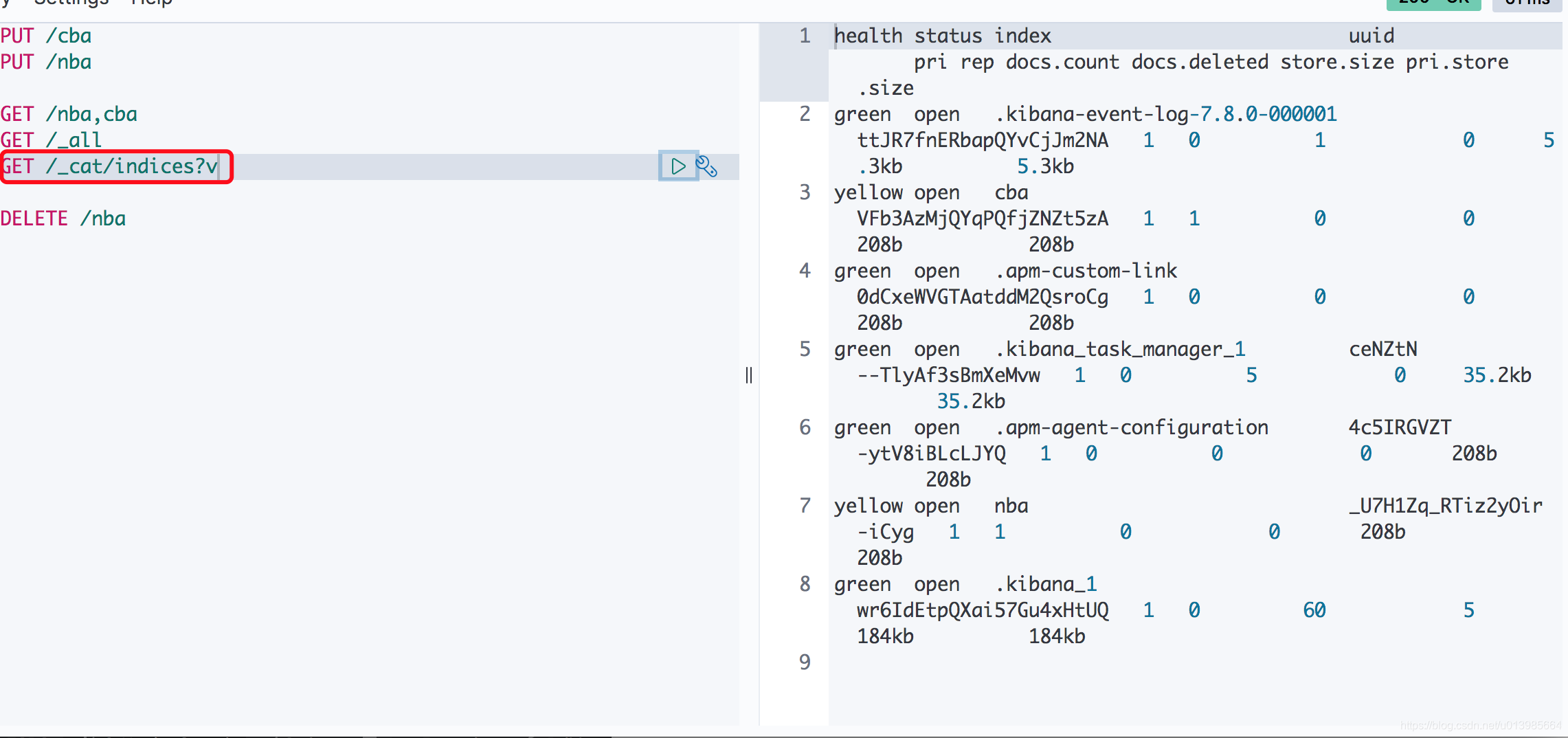
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana-event-log-7.8.0-000001 ttJR7fnERbapQYvCjJm2NA 1 0 1 0 5.3kb 5.3kb
yellow open cba VFb3AzMjQYqPQfjZNZt5zA 1 1 0 0 208b 208b
green open .apm-custom-link 0dCxeWVGTAatddM2QsroCg 1 0 0 0 208b 208b
green open .kibana_task_manager_1 ceNZtN--TlyAf3sBmXeMvw 1 0 5 0 35.2kb 35.2kb
green open .apm-agent-configuration 4c5IRGVZT-ytV8iBLcLJYQ 1 0 0 0 208b 208b
yellow open nba _U7H1Zq_RTiz2yOir-iCyg 1 1 0 0 208b 208b
green open .kibana_1 wr6IdEtpQXai57Gu4xHtUQ 1 0 58 3 167.1kb 167.1kb
这里可以看到会将每个索引的健康状态、文档大小等展示出来。加上
?v会将指标表头一同返回给我们。
4.7 打开/关闭索引
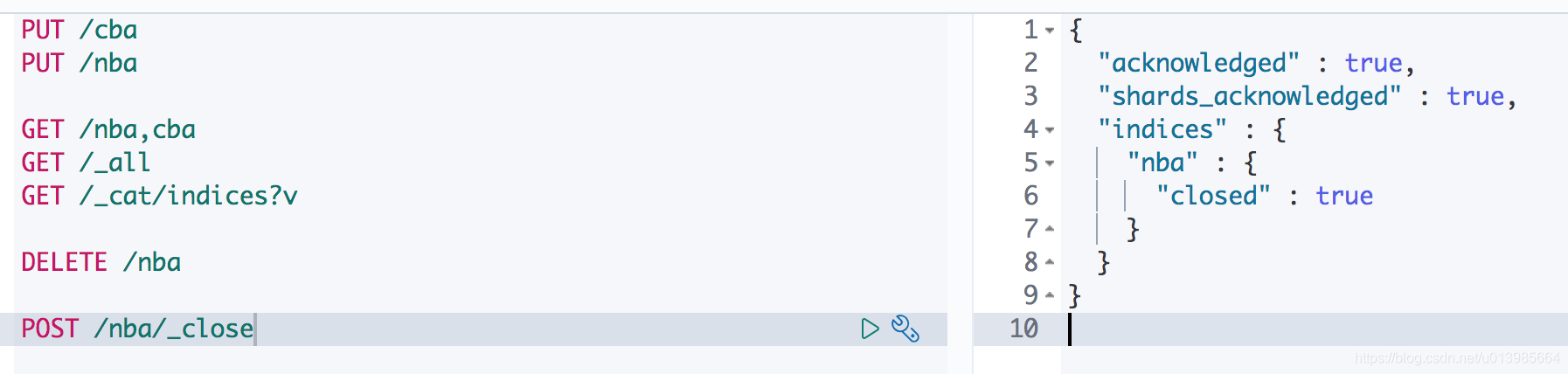
当有一些索引我们业务已经不需要又暂时不想删除的时候,我们还可以通过
/nba/_close和/nba/_open去打开关闭。关闭了之后对应索引将只会占用磁盘空间而不会占用内存空间。
5.映射的介绍和使用
上面我们给大家介绍了索引的一些操作,接下来我们来看看映射是如何操作的。这里我们暂时先不关心每个映射的类型,虽然大家看到声明大概就能猜出来。
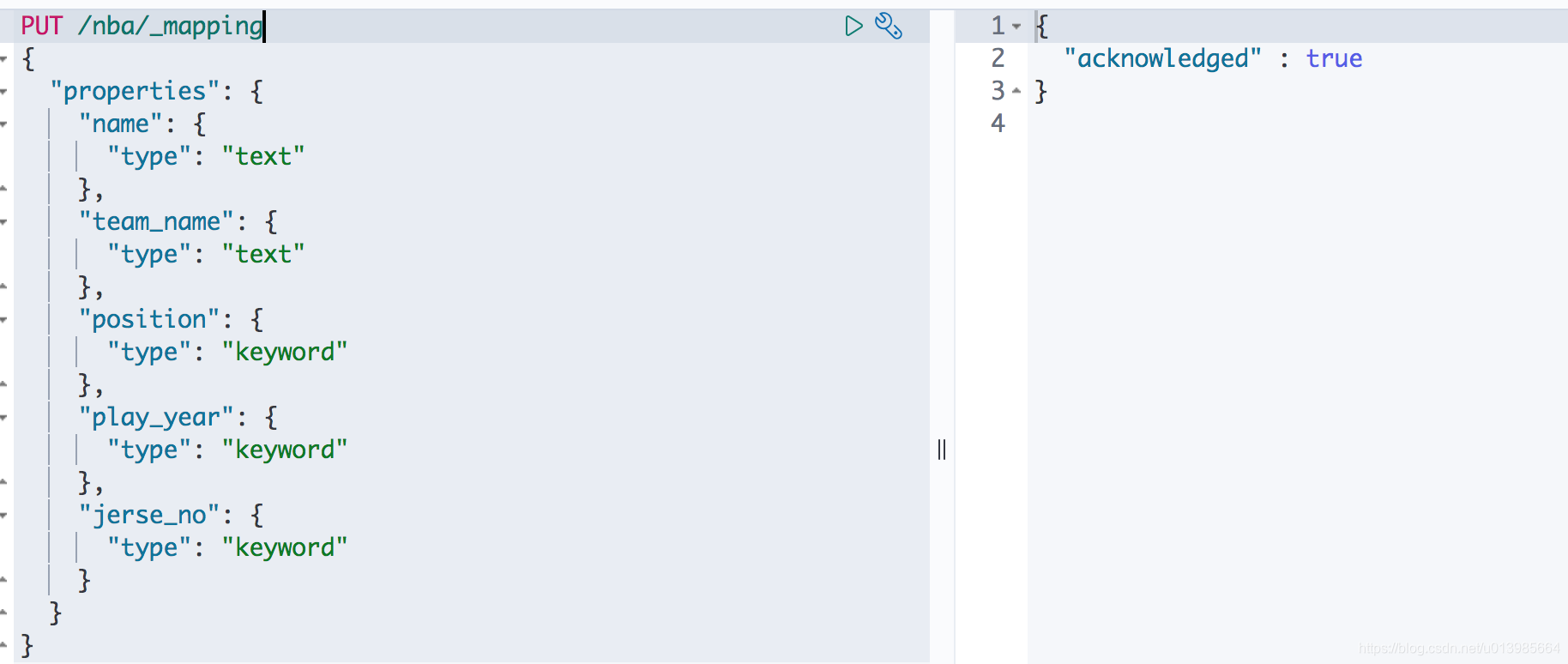
5.1 新建映射
新建映射也十分简单,之前我们建立索引后并未进行其他命令的操作。这里我们通过
PUT /nba/_mapping,然后使用一段json来声明映射的每个属性的类型即可。
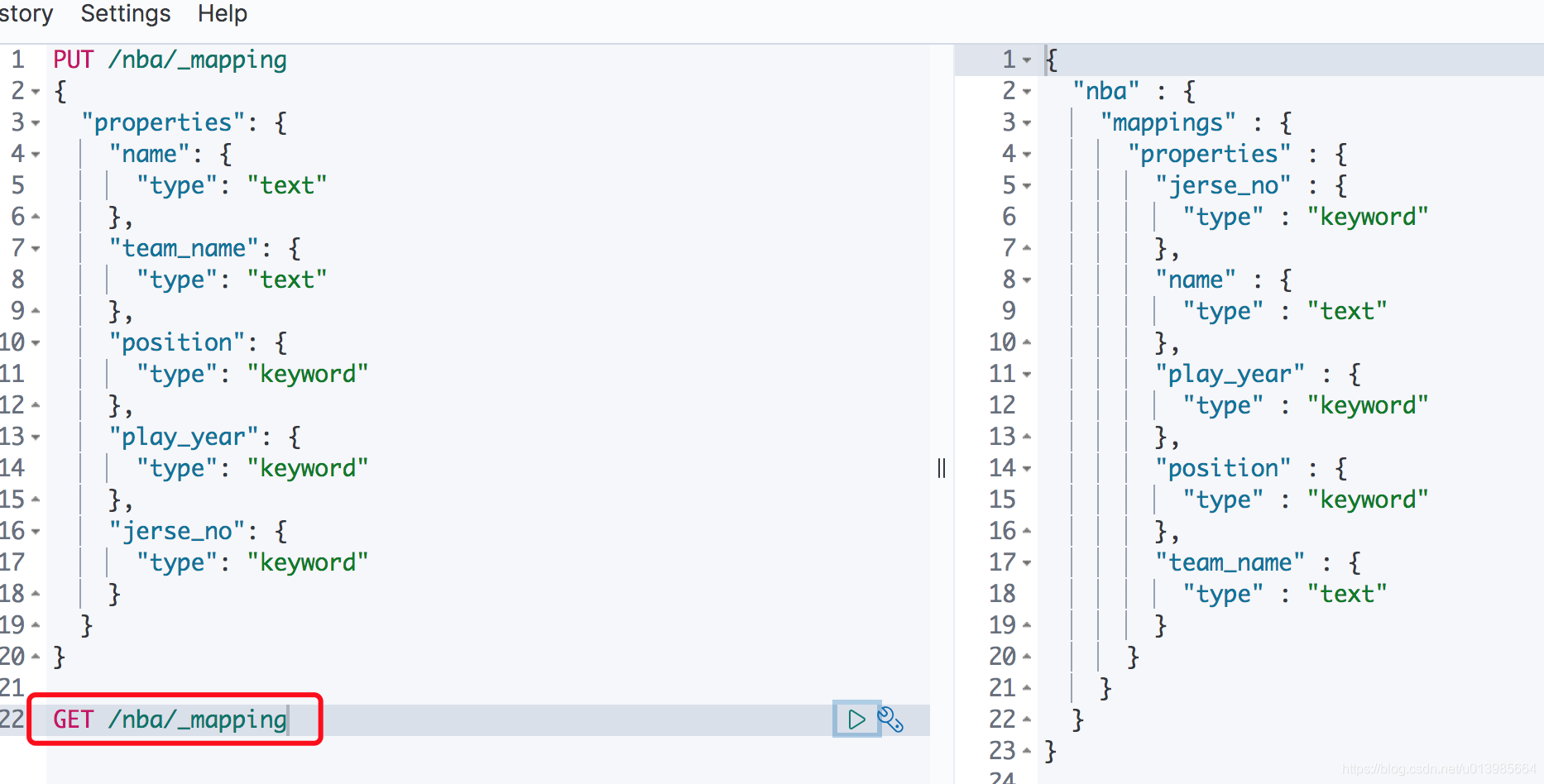
5.2 获取映射
获取映射信息就十分简单了,直接通过
GET /nba/_mapping就可以看到我们刚才为索引建立的映射关系。
这里我们通过GET /nba/_mapping可以看到没有手动添加映射关系的索引是什么样子的。

5.3 批量获取映射
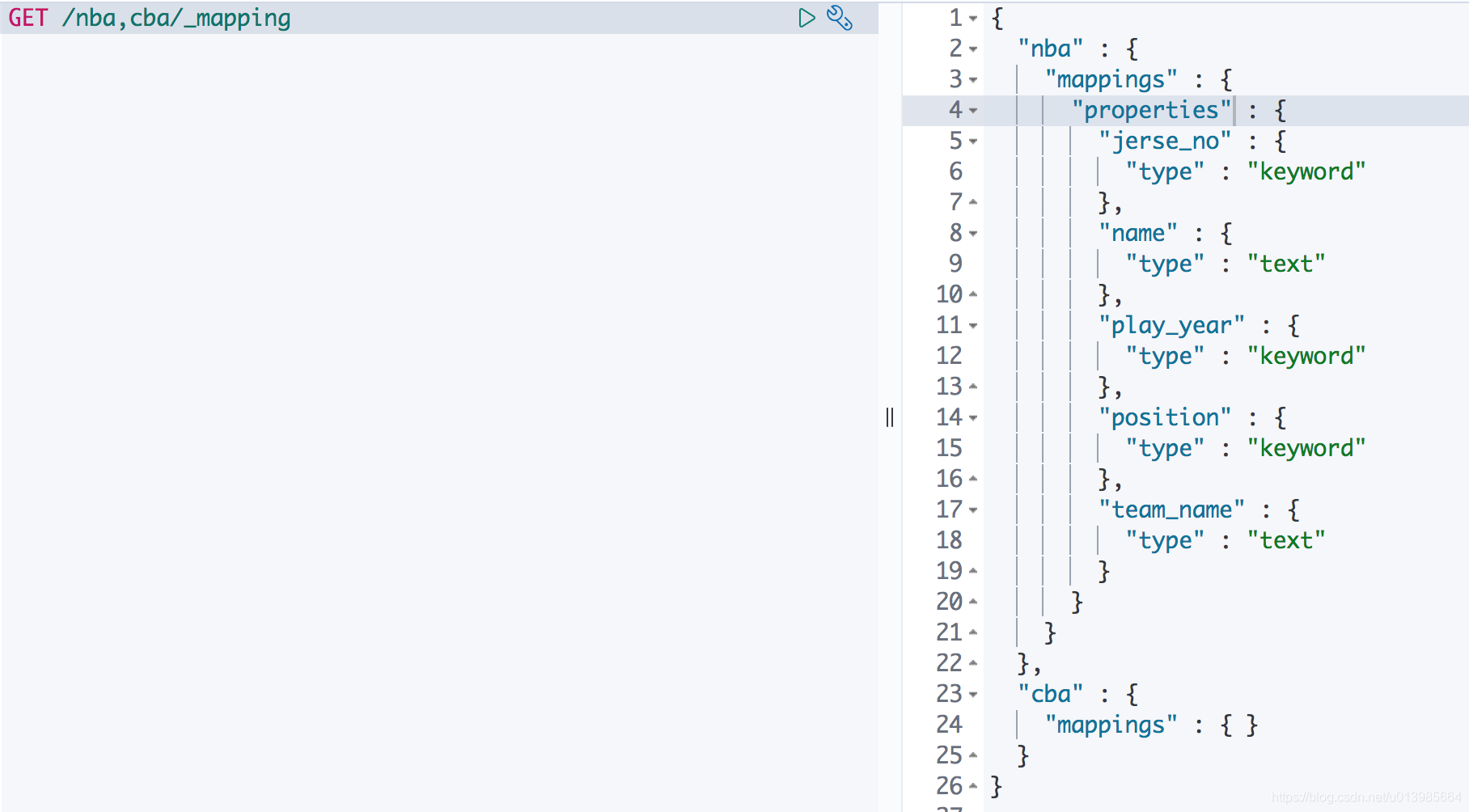
同样,我们也可以通过
GET /nba,cba/_mapping去批量获取多个索引的信息。
5.4 获取所有映射
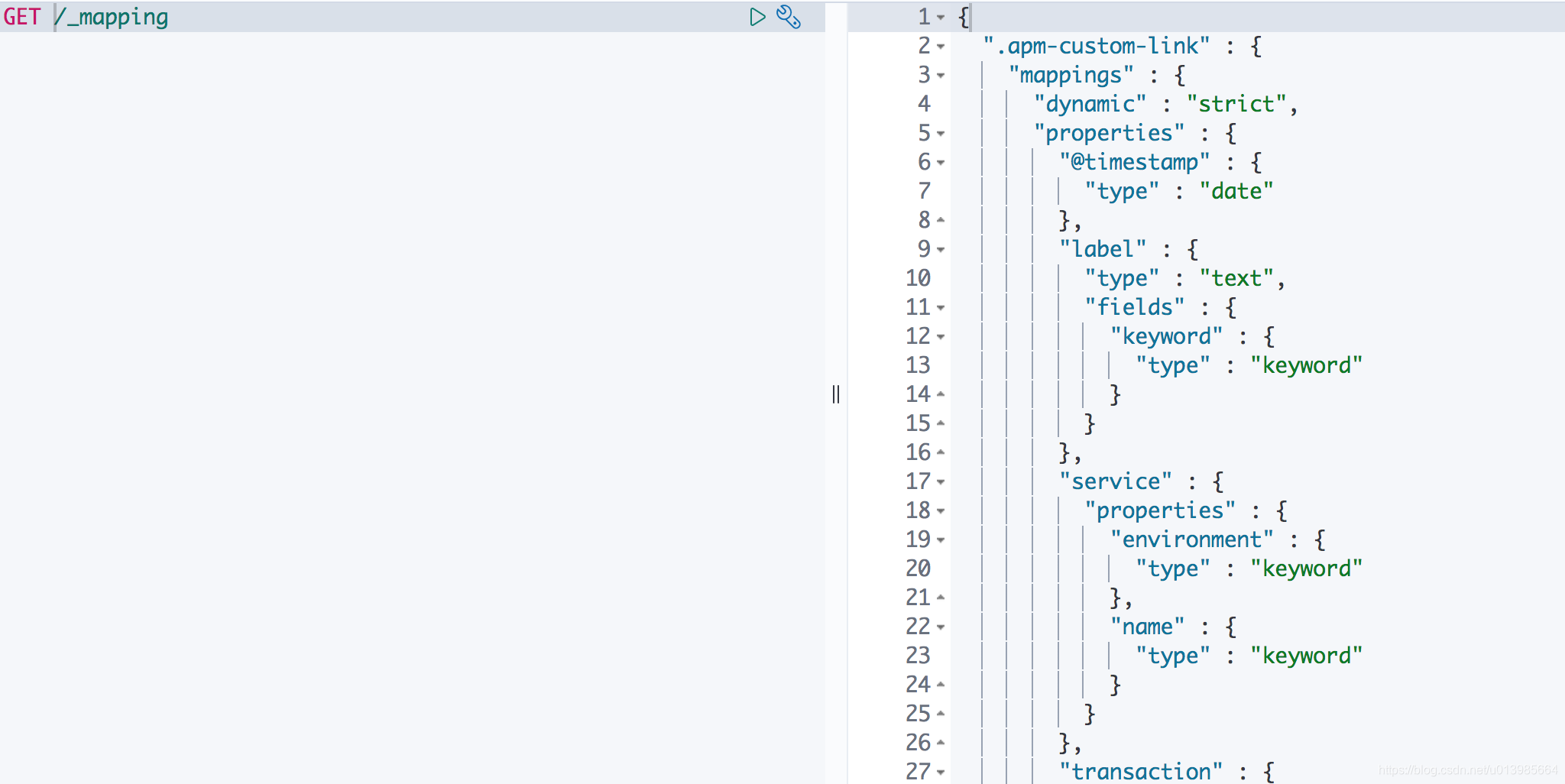
我们还可以通过
/_mapping和/_all/_mapping去获取所有的映射关系,这点和获取所有的索引也非常相似。
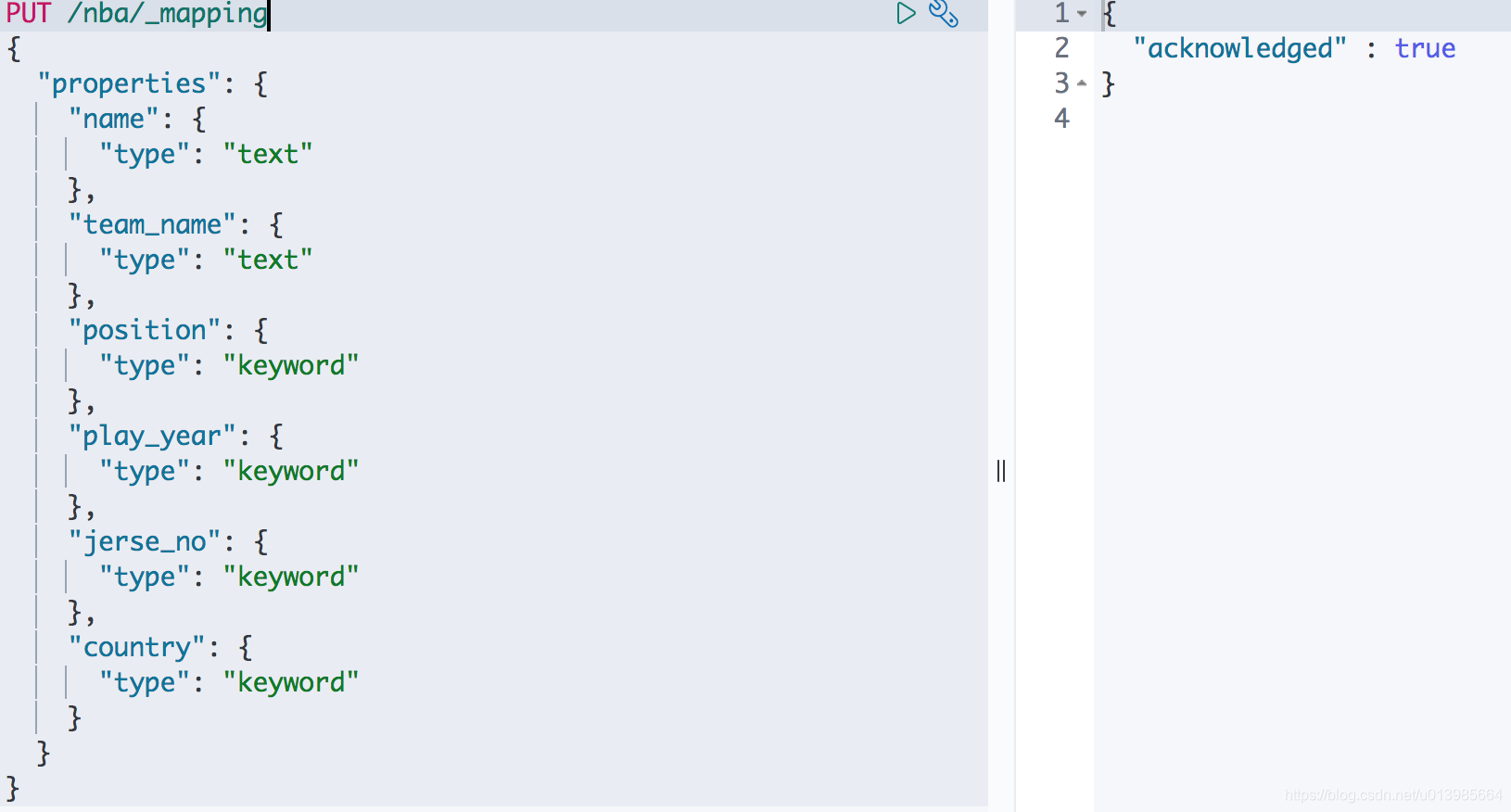
5.5 更新映射
在使用Mysql的时候想必大家也经常会遇到需要加字段的时候。以上面我们新建的映射为例,假如我们需要添加一个新的字段
country需要怎么做呢?
这里其实和我们之前新建一样的方式即可。
6.文档的介绍与使用
文档就相当于我们Mysql中的一行数据了,也就是说我们其实使用Es真正最终接触最多的就是文档。更多的操作也是基于文档的操作,这里我们就来看一下文档是怎么玩的。
6.1 新增文档
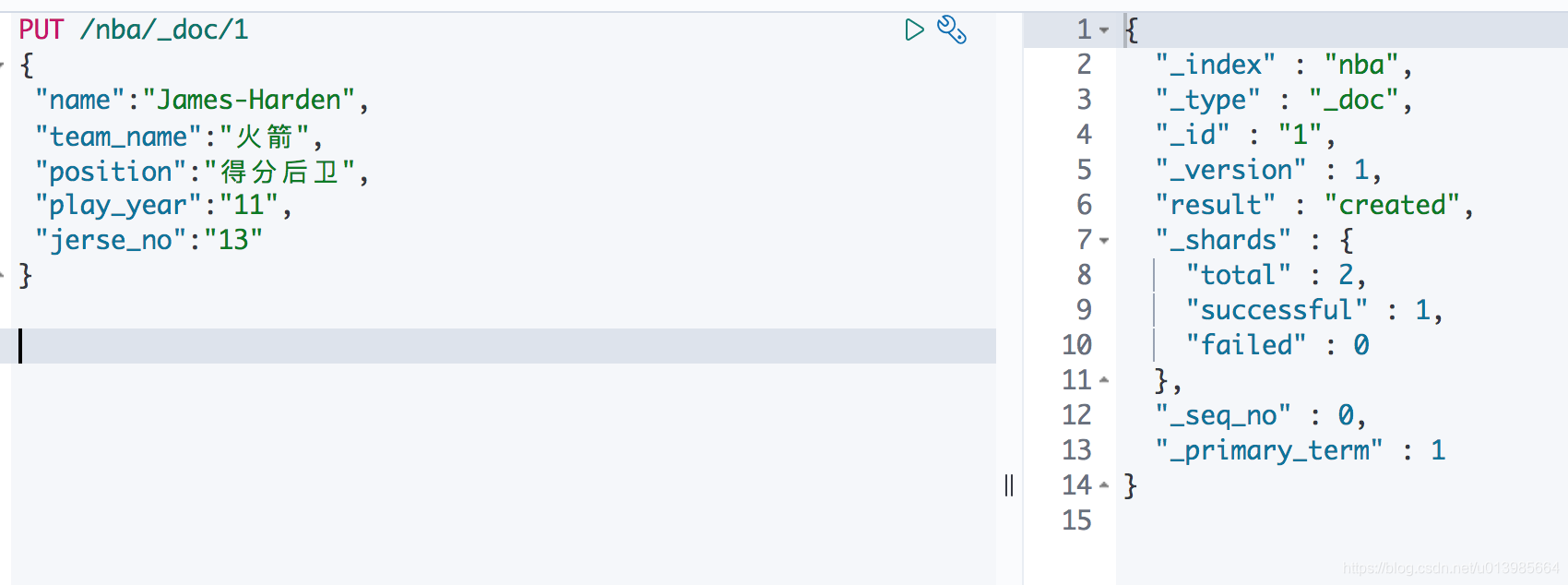
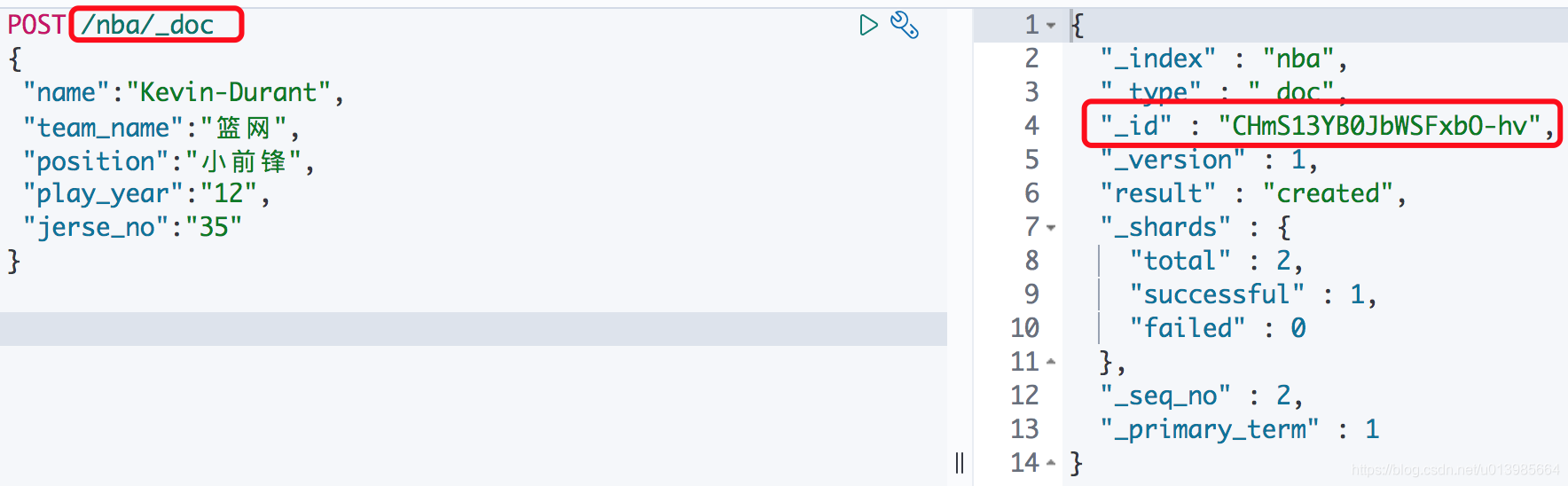
要想操作文档,那我们首先肯定得有数据。第一种方式我们可以通过
PUT /nba/_doc/1创建文档。这里我们给该文档指定了ID=1,在响应结果里面也可以看到。这里采用POST和PUT方式都行。
第二种就是直接通过POST /nba/_doc的方式创建,这种的话可以看到响应里面会给我们生成一个ID。需要注意的是这种不指定ID的方式只能通过POST请求。而上面使用指定ID的命令可以使用PUT是由于他实际上属于更新操作,如果数据不存在则创建。
6.2 自动创建索引(auto_create_index)
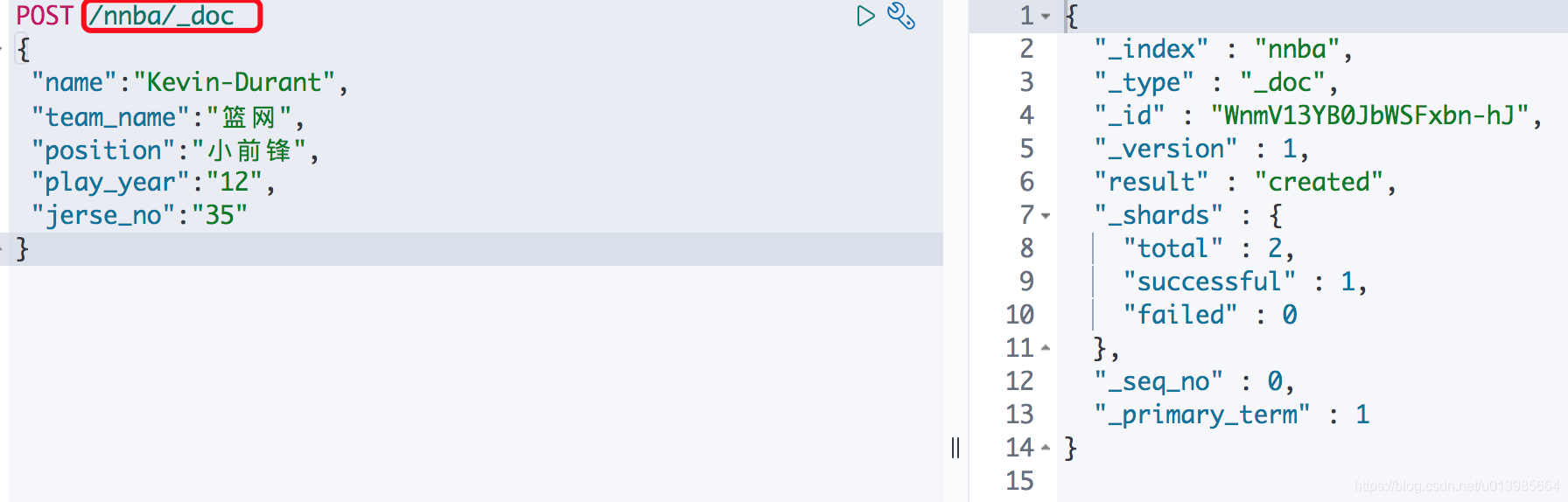
既然介绍到了文档的创建,那我们来玩一个骚操作。这里我们使用命令
POST /nnba/_doc去给nnba这个不存在的索引新建文档看看会怎么样。
神奇的是他居然成功了,而且我们也可以通过ID去获取文档信息。这是因为ES有一个配置auto_create_index,这个配置会在索引不存在时自动创建索引并且是默认开启的。
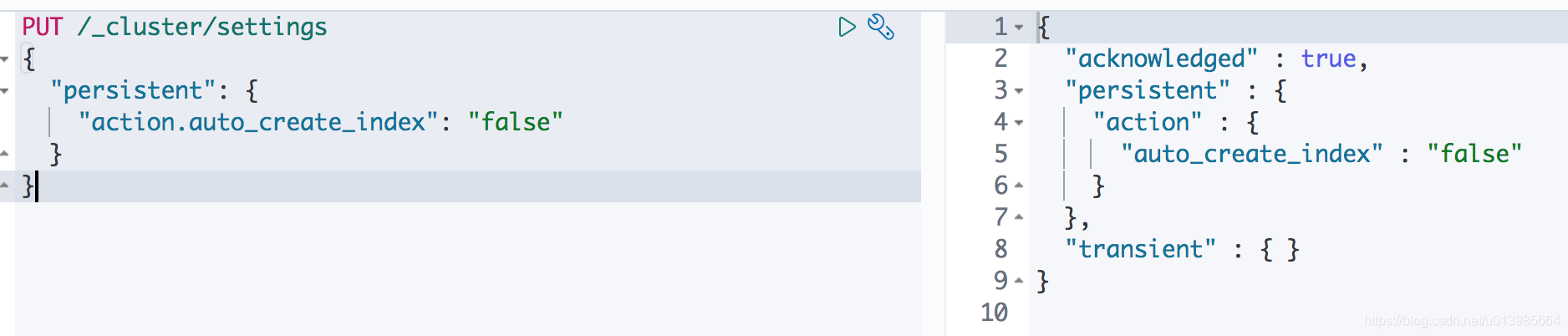
这里我们可以通过GET /_cluster/settings查看ES集群的部分属性配置。这里可以看到好像什么都没有?这就对了,默认是开启的嘛。那我们就来把他改成false看看。
对于如何修改配置属性,不过经过上面一系列的组合拳其实我们已经摸清楚了ES的套路了。这里我们只需要在官网文档里找到对应配置名称即可。
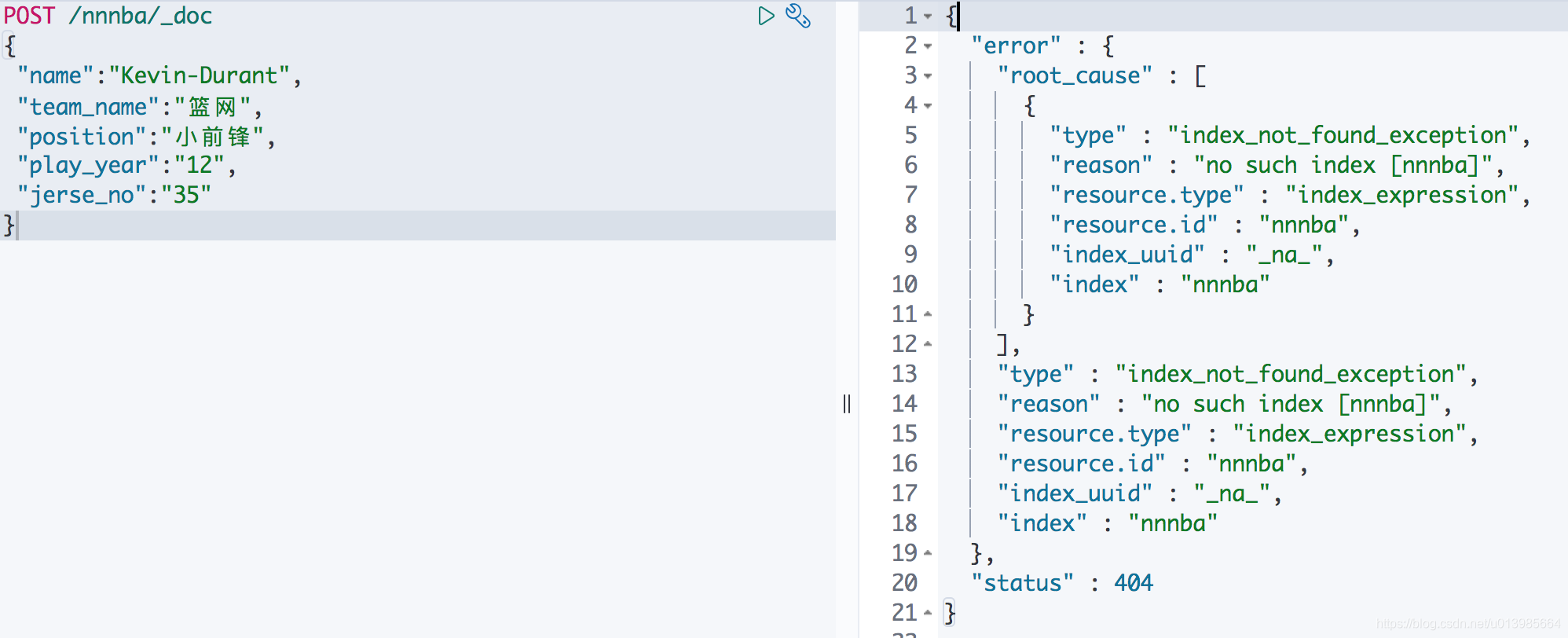
请求方式改成PUT,加上请求内容,大功告成。这里我们再来试试看往不存在的索引里添加文档。
果不其然,我们成功地阻止了ES自动创建索引。

6.3 指定操作类型(op_type)
上面我们知道了不管是通过
POST还是PUT请求,其实ES都会根据文档ID和version版本号去校验是新增还是更新。当然如果我们的场景确实不需要他这么智能,就是需要坚定本次操作的行为是新增还是更新的话也是有办法的。
这里我们在操作文档的时候加上op_type=create就可以指定本次就是创建操作,那么如果该数据已存在的话就会操作失败。
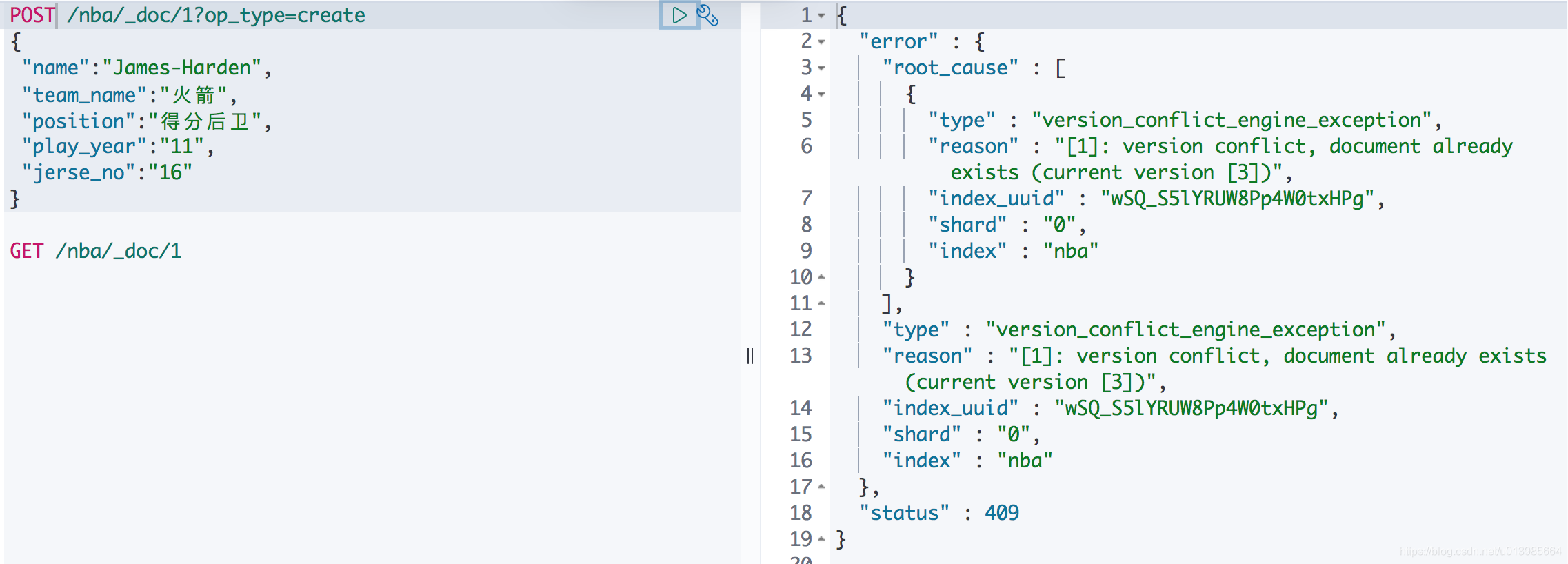
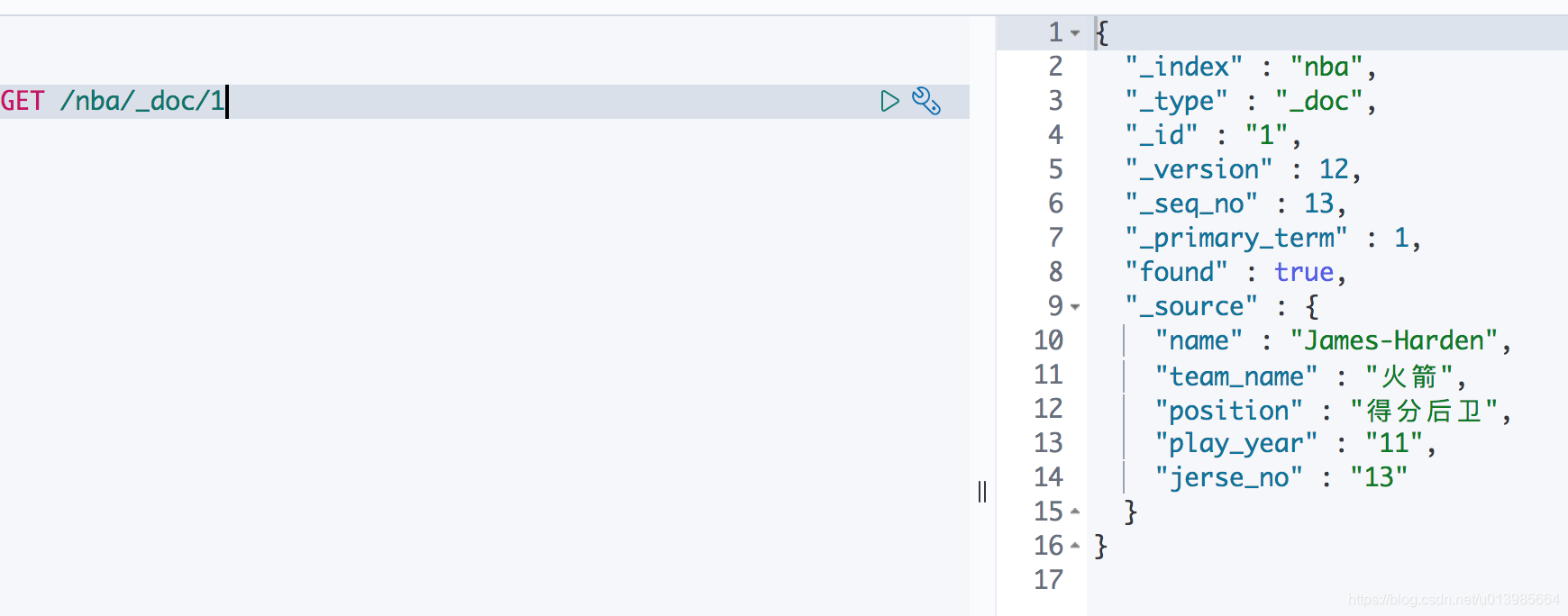
6.4 获取文档
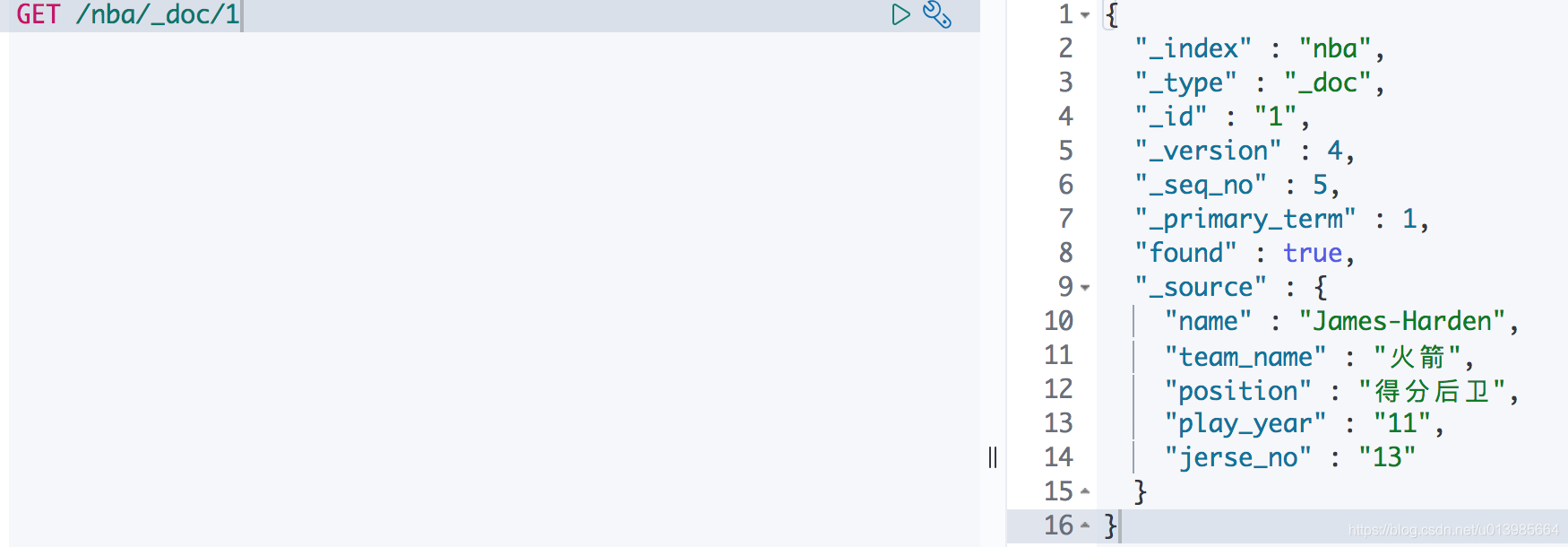
这里我们直接通过
GET /nba/_doc/1就可以了获取nba索引中ID为1的文档信息。
6.5 批量获取文档
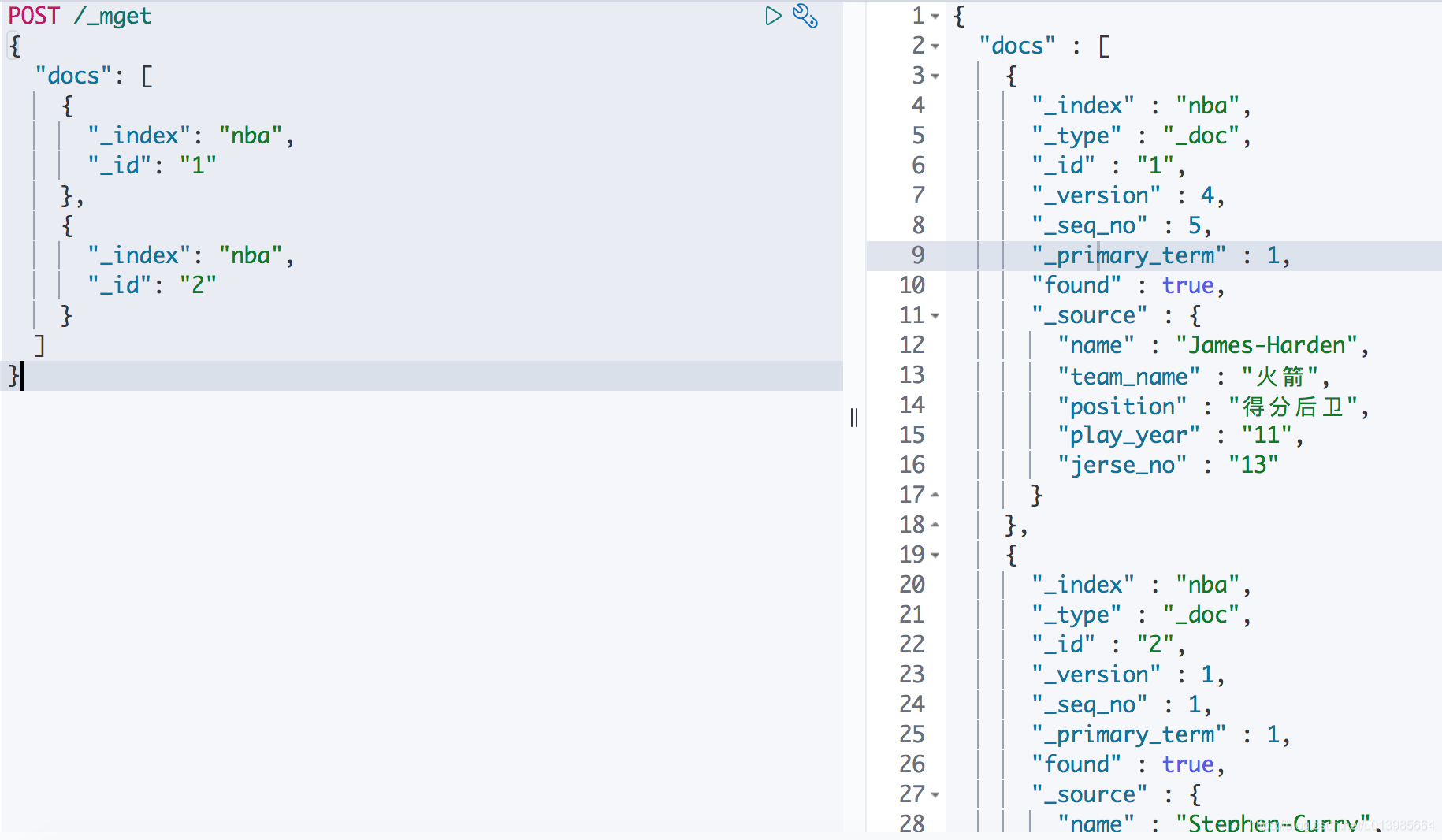
这里我们可以直接通过
POST /_mget然后搭配上请求内容找到对应的多个文档。
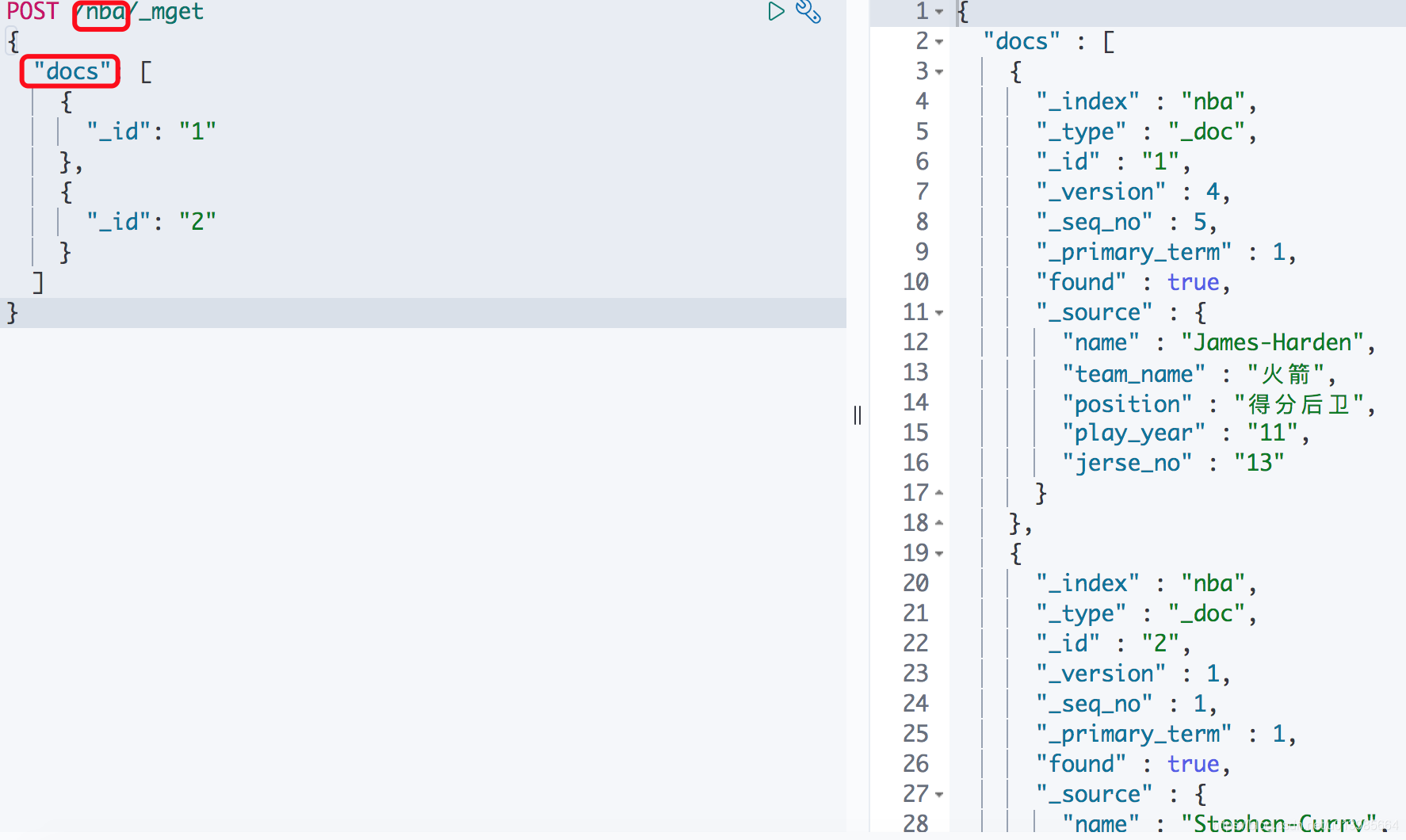
我们如果在URL上加上索引名称的话,那请求内容中就可以省略_index的指定。
ES的识别十分智能,所以我们还可以更简单就能去达到同样的效果。这里请求内容里只需要指定ids即可。
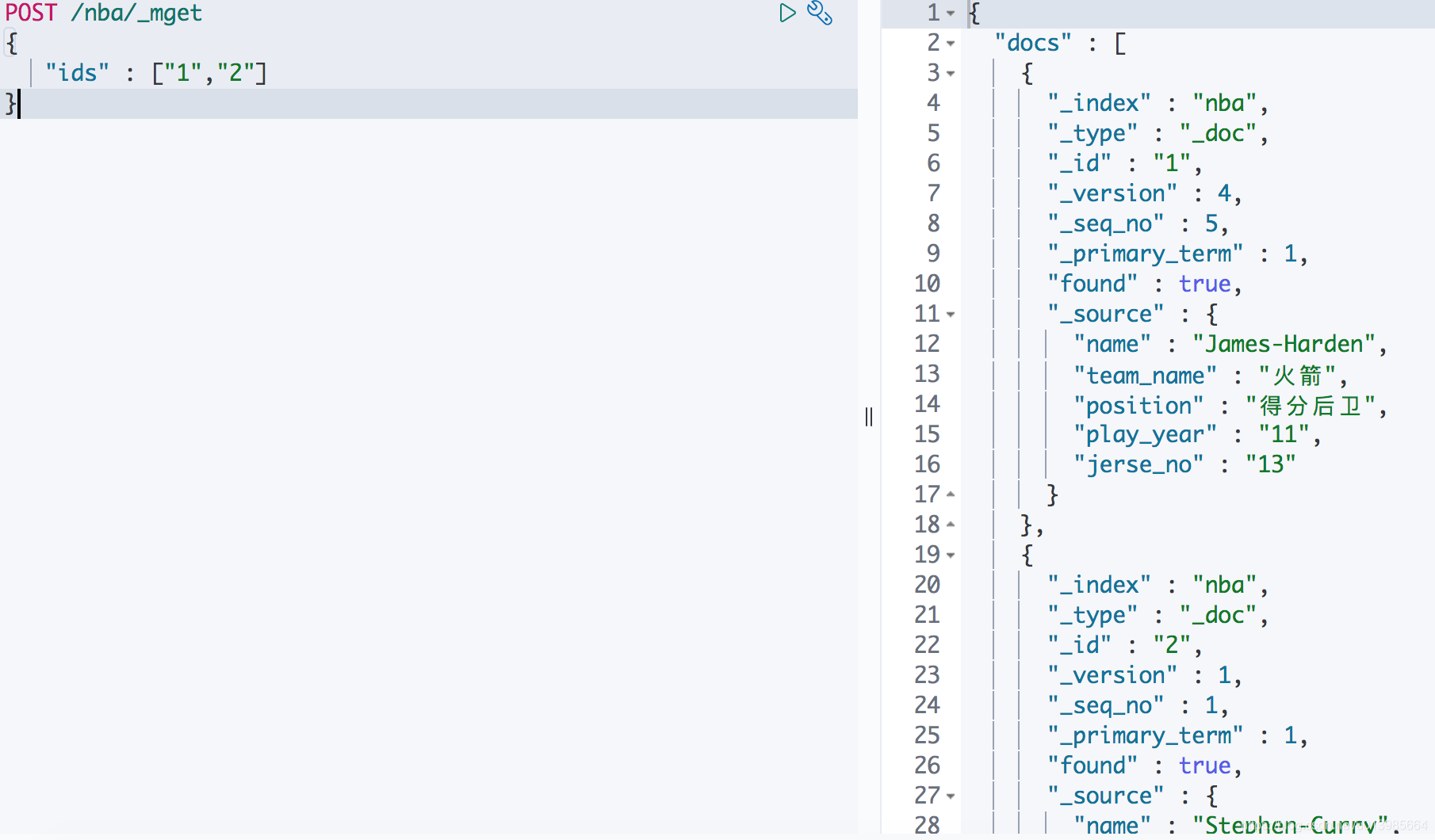
6.5 更新文档
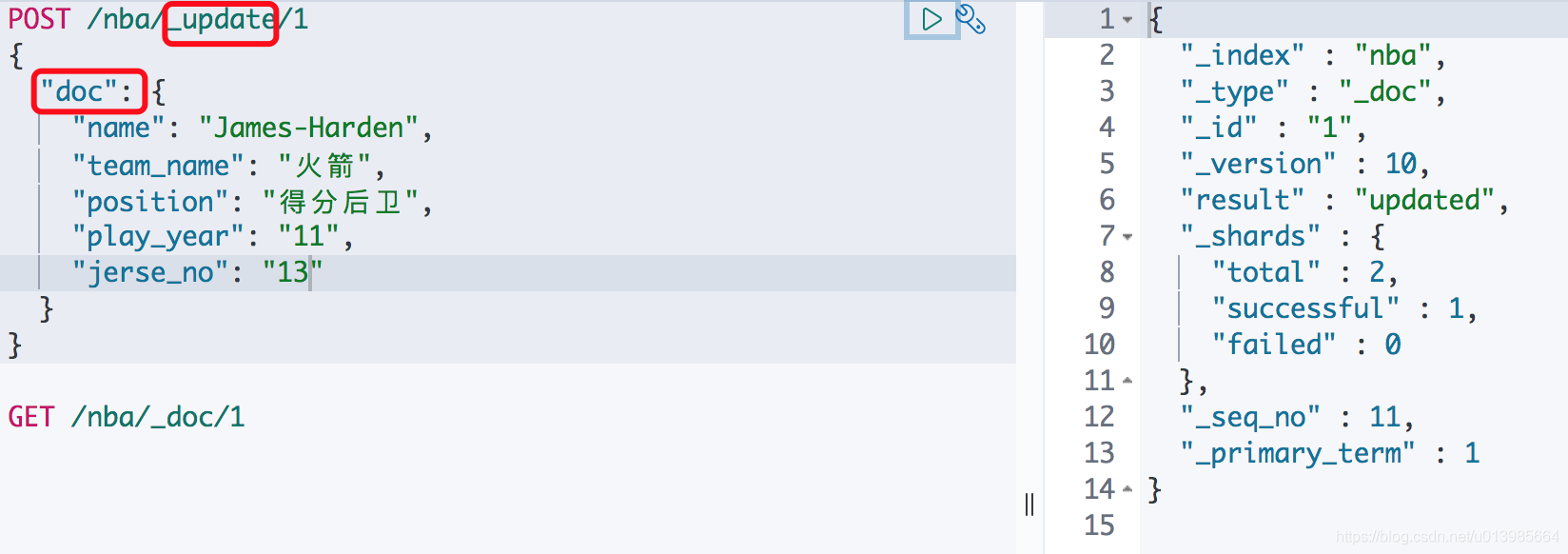
修改文档的方式也不止一种,ES确实十分灵活。第一种就类似我们之前添加文档时的方式类似,直接通过
POST /nba/_doc/{id}加上文档内容即可修改。
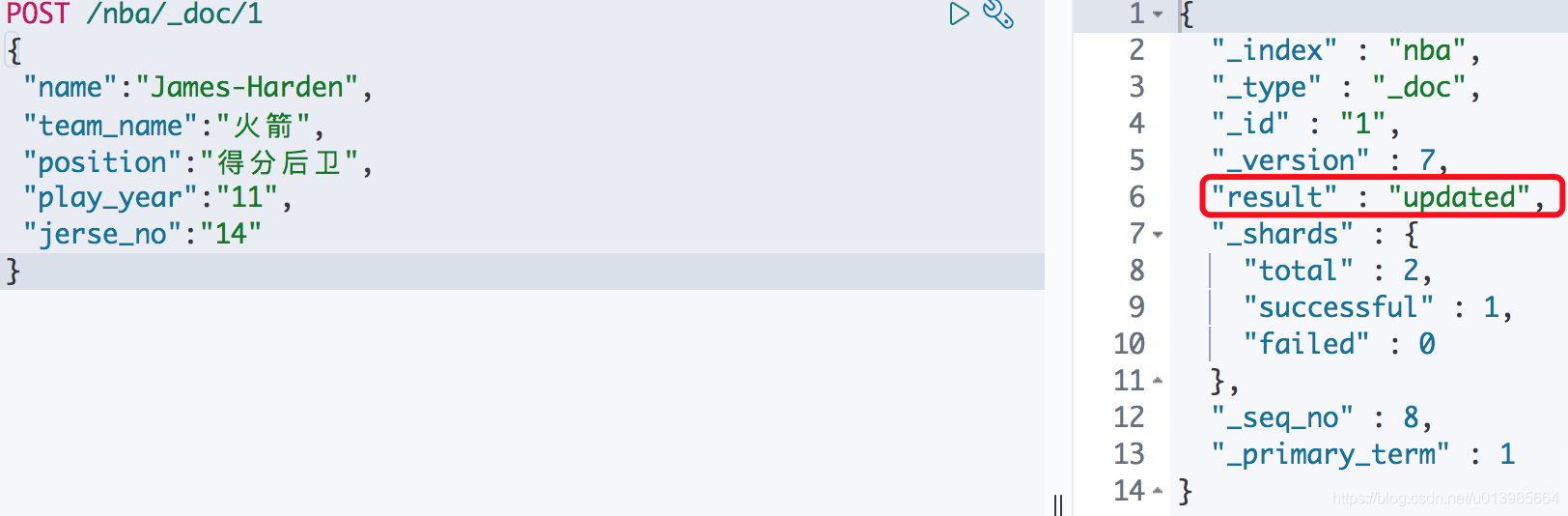
另外我们还可以通过POST /nba/_update/{id}的方式,在请求内容中指定更新的doc内容也可以实现同样的效果。
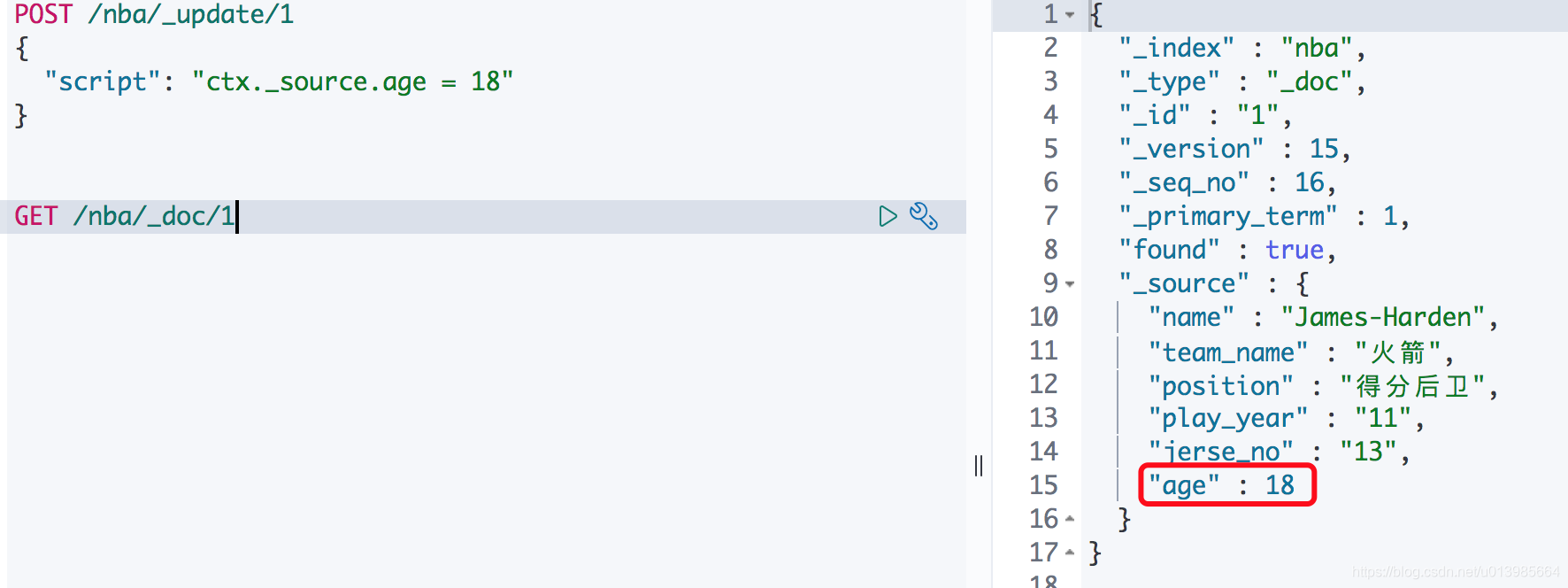
这里我们获取一下ID为1的索引信息,可以发现其实我们所添加的文档内容都在_source这个属性中,其他的都属于一些ES本身维护的信息。那么假如我们现在想要给_source中添加一个age的属性要怎么做呢?
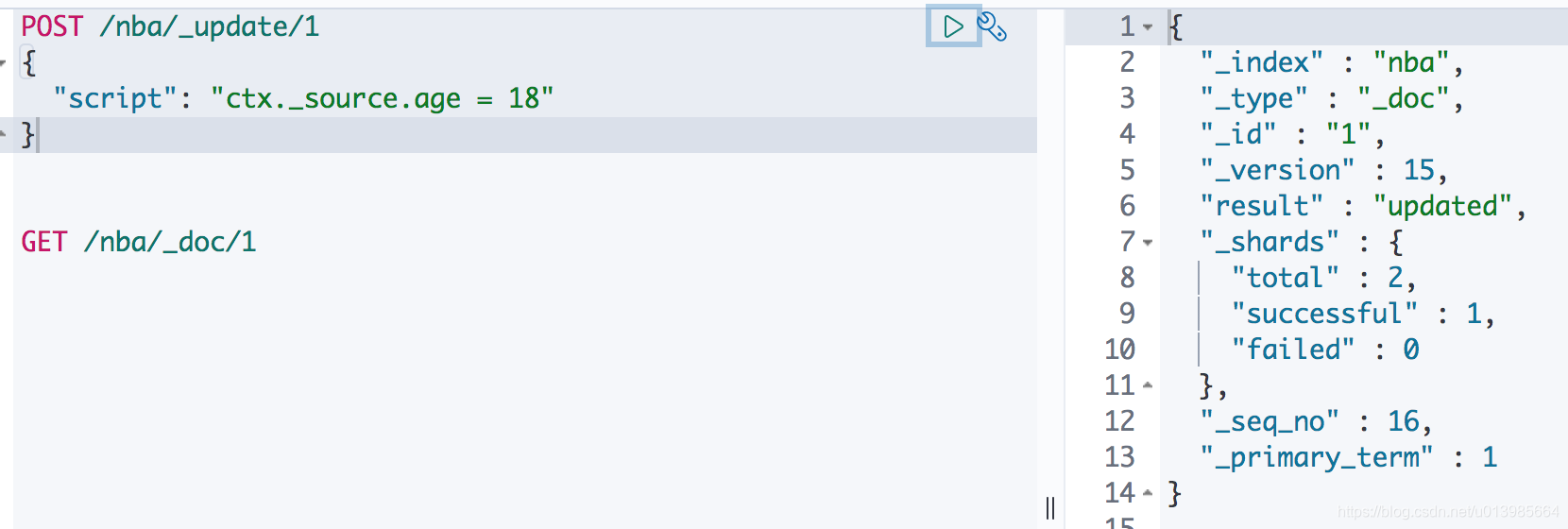
首先我们可以通过上面的方式去更新。我们还可以通过POST /nba/_update/{id},请求内容指定为"script": "ctx._source.age = 18"也可以往_source中添加属性。
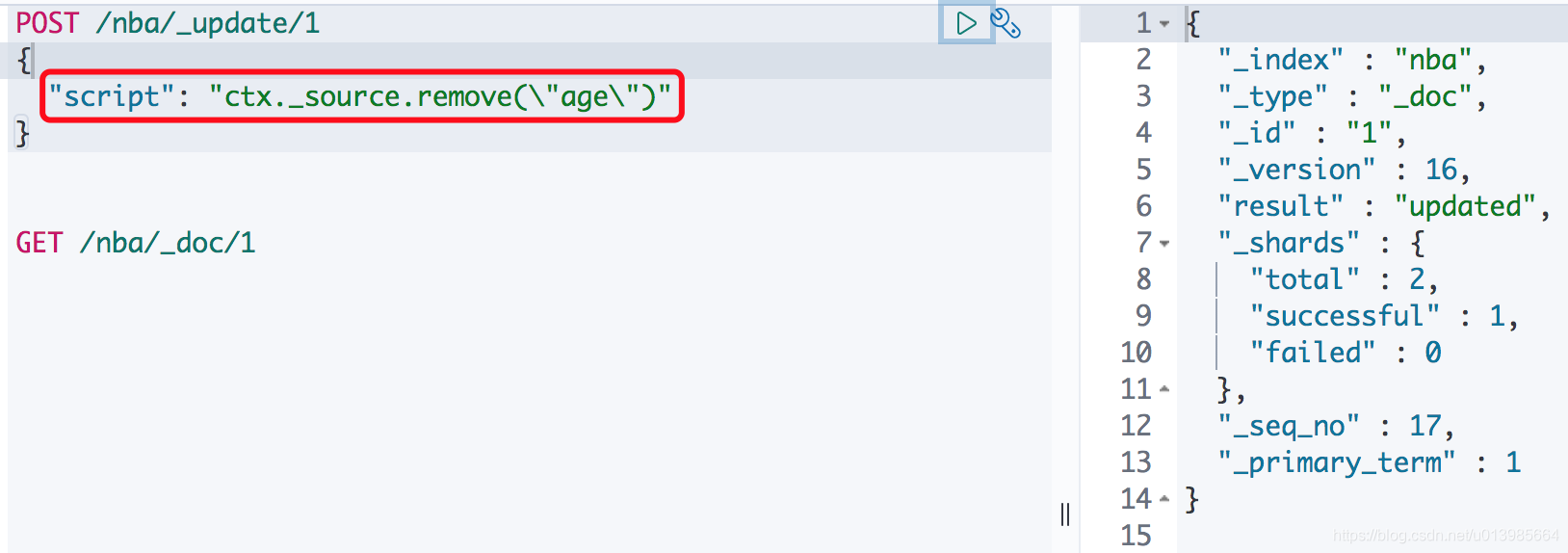
而我们要删除也只要通过"script": "ctx._source.remove(\"age\")"就可以删除该文档某个属性了。
6.6 更新文档(根据参数值)
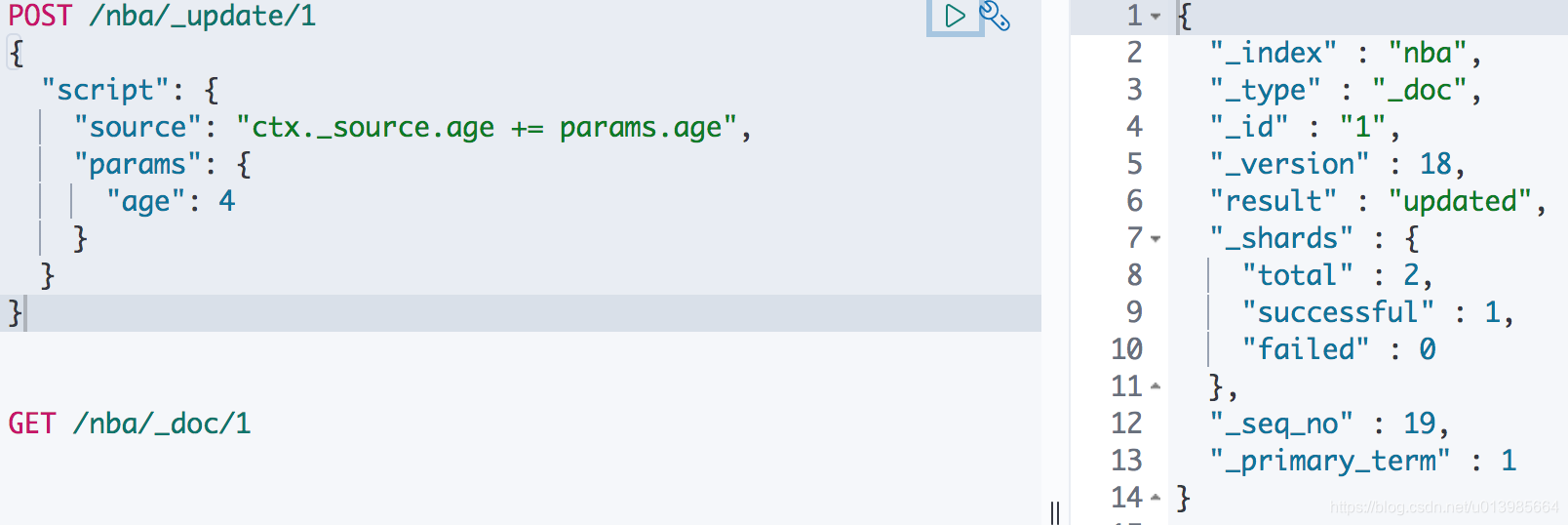
假设有一个这样的场景,我们需要给ID为1的文档数据年龄加上一个数值,我们需要怎么做?
按照正常的思路,我们会先把ID为1的文档查询出来之后给年龄加上固定数值,然后再更新这个文档。但是这里我们有一种更方便的做法,我们上面用到的script其实相当于一种脚本,我们可以通过这种方式给某个属性加上一个我们指定的参数。
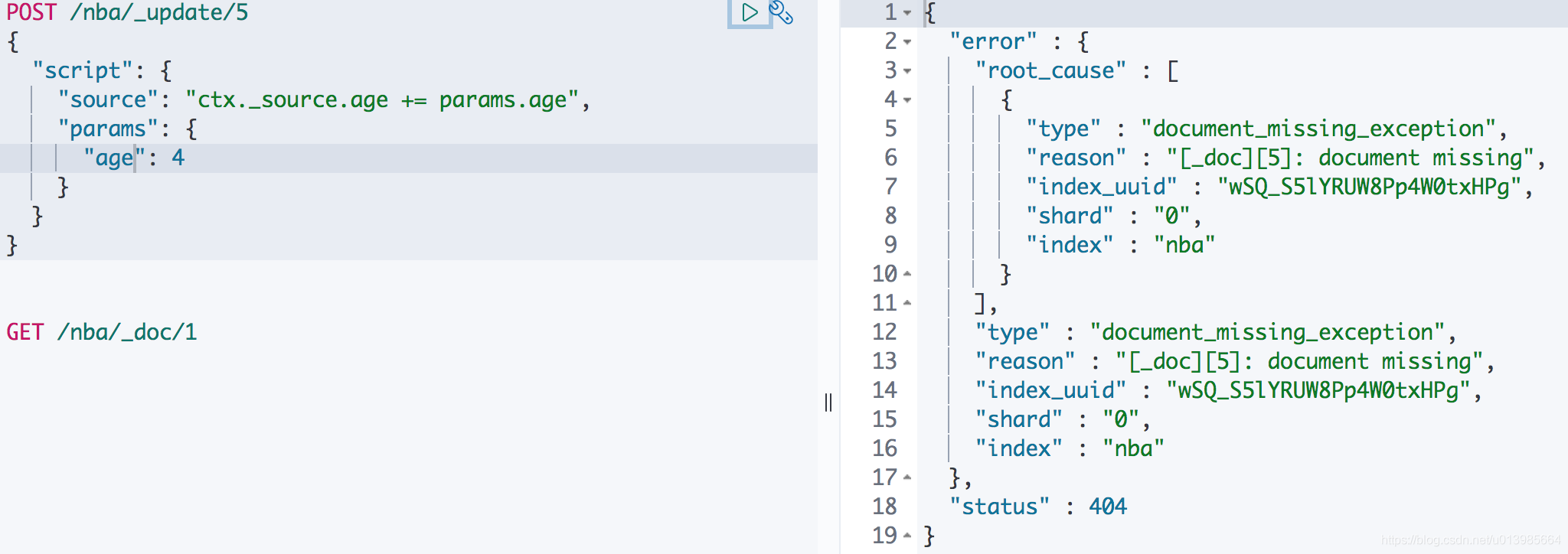
那么假设我们操作一个不存在的文档会怎么样呢?这里ES是会响应异常的,告诉我们文档不存在。
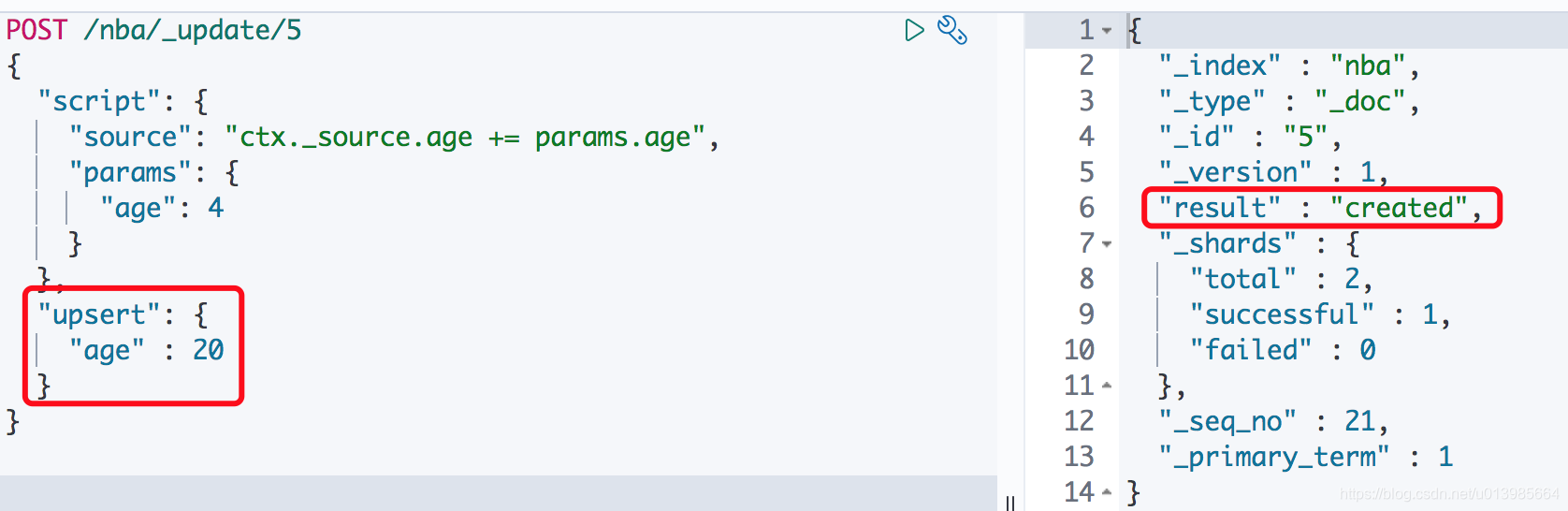
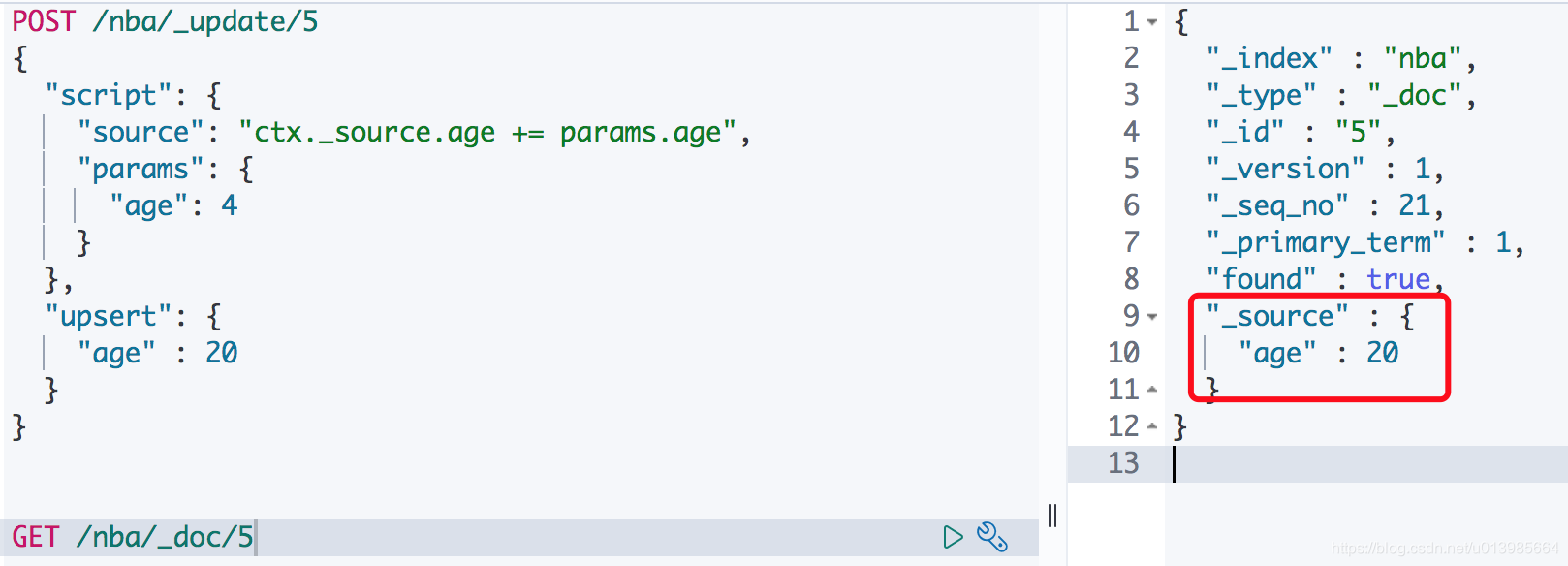
那么我们就是要给他更新行不行呢?也行。ES给了我们一个执着的机会,当然肯定也是因为有一些实际场景需要才会提供这种功能,这里我们只要加上upsert就可以了。
upsert当指定的⽂档不存在时,upsert参数包含的内容将会被插⼊到索引中,作为⼀个
新⽂档;如果指定的⽂档存在,ES引擎将会执⾏指定的更新逻辑。
6.7 删除文档
删除文档就没有那么多花样,和之前规则一样使用
DELETE /nba/_doc/{id}即可。

7.常见字段类型的介绍
不管是我们上面的铺垫还是我们使用ES的初衷都离不开
搜索这个核心,但是在使用搜索之前我们将先来了解一下常见的字段类型有一些什么。
这里我们介绍一下平常使用比较频繁的字段类型,更详细的大家可以移步【ES官网-映射类型】。
7.1 核心数据类型
这一类数据其实就是我们平时用的比较多的几种类型了,如果大家有编程基础的话其实还是十分容易理解的。
- 字符串
- text : ⽤于全⽂索引,该类型的字段将通过分词器进⾏分词。如果一个字段要被全文搜索,比如电影名称、电影描述、文章内容等就应该使用该类型。text类型字段一般也不会用于排序和聚合。
- keyword : 不分词,只能通过精确值搜索。适用于索引结构化的字段,比如状态、标签等就可以使用该类型。
- 数值型
- long、integer、short、byte、double、float、half_float、scaled_float : 这一部分类型主要区别在于范围和精度,根据所需场景尽可能选择最接近业务范围的字段检索效率越高。
- 布尔 - boolean
- 二进制
- binary : 该字段是指用base64来表示索引中存储的二进制数据,可用来存储二进制形式的数据,例如图像。默认情况下,该类型的字段只存储不索引。
- 范围类型
- 范围类型表示值为一个范围区间,而不是一个具体的值。
- integer_range, float_range, long_range, double_range, date_range都属于这一类的字段。
- 例如 age 的类型是
integer_range,那么值可以是 {“gte” : 20, “lte” : 40};搜索 “term” :{“age”: 21} 可以搜索到该值。
- 日期 - date
- 由于Json没有date类型,所以es通过识别字符串是否符合format定义的格式来判断是否为date类型。例如
2021-01-01、2021-01-01 12:00:00。 - format默认为:strict_date_optional_time || epoch_millis
- epoch就是指UNIX诞生的UTC时间1970年1月1日0时0分0秒
- 由于Json没有date类型,所以es通过识别字符串是否符合format定义的格式来判断是否为date类型。例如
7.2 复杂数据类型
- 数据类型 - Array
- ES中没有专⻔的数组类型, 直接使⽤[]定义即可。
- 例如 : 字符串数组 [ “McGrady”, “James” ] ;整数数组 [ 66, 88 ];Object对象数组 [ { “name”: “Louis”, “age”: 18 }, { “name”: “Daniel”, “age”: 17 }]。
- 数组中所有的值必须是同⼀种数据类型, 不⽀持混合数据类型的数组。例如 : [ 18, “Curry” ] 就是错误的。
- 对象类型 - Object
- JSON对象,文档可以包含嵌套对象。
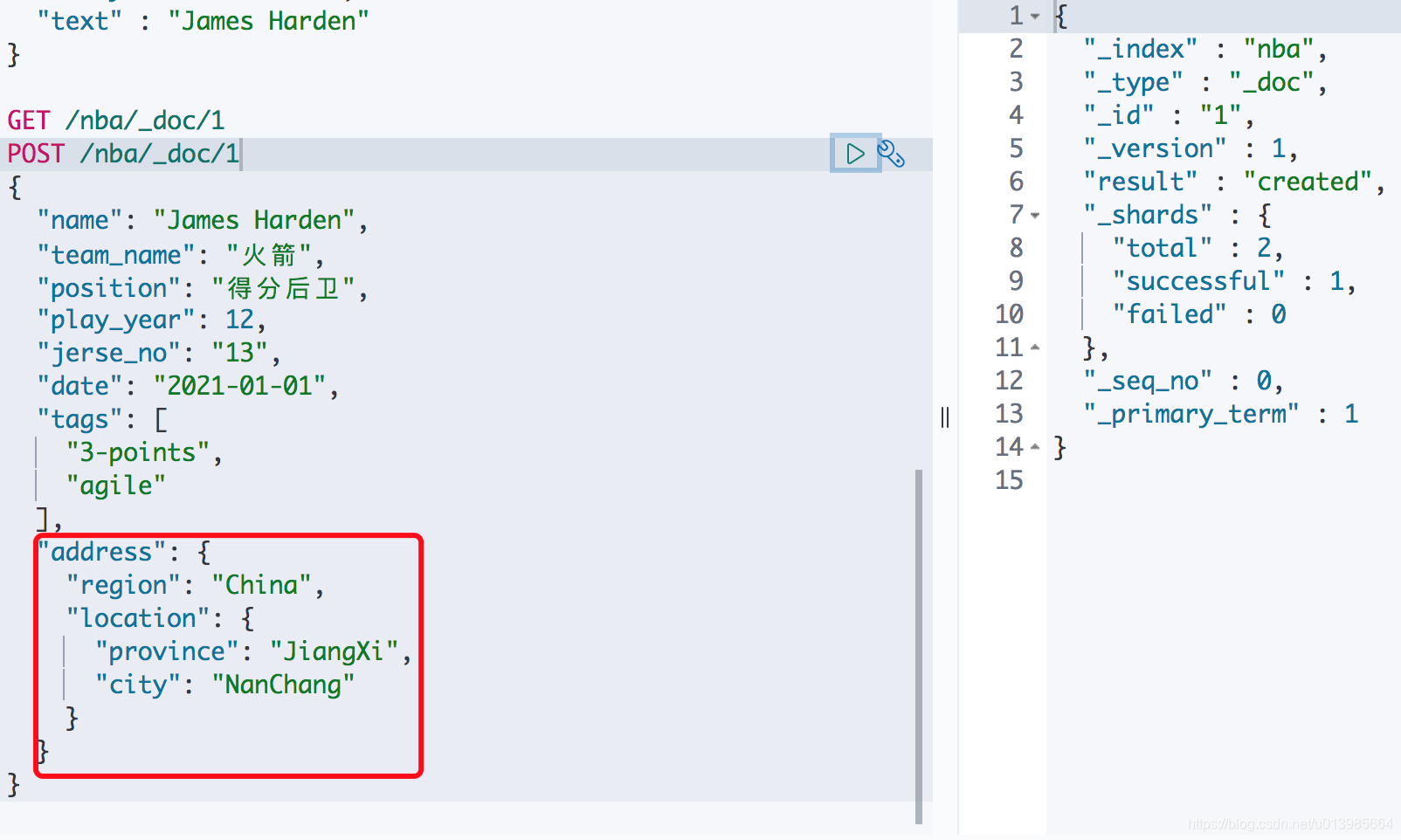
- 这里如果我们需要根据对象里面属性检索也是可以的。语法如下:
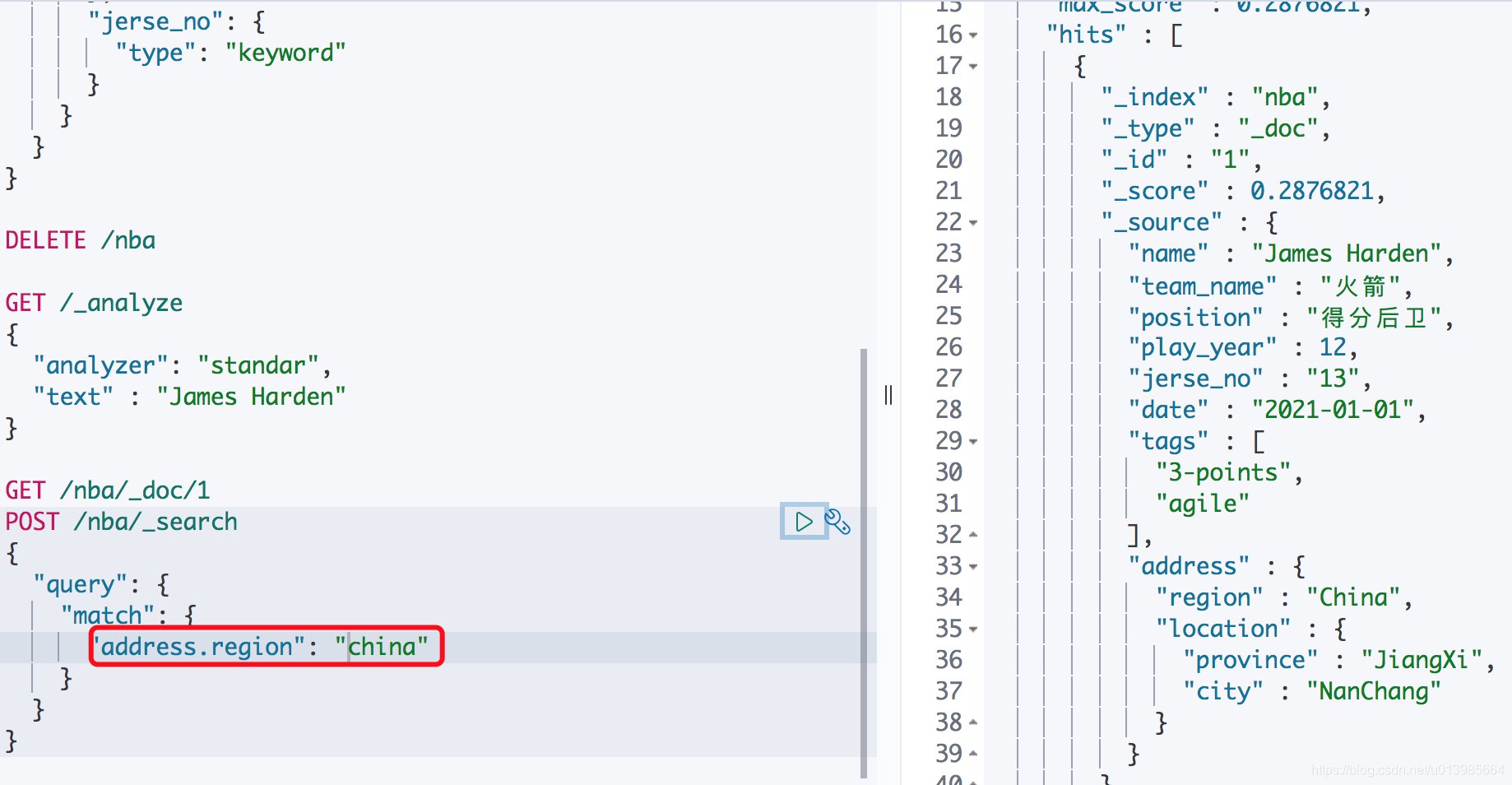
- JSON对象,文档可以包含嵌套对象。
7.3 专用数据类型
- IP类型
- IP类型的字段⽤于存储IPv4或IPv6的地址, 本质上是⼀个⻓整型字段。
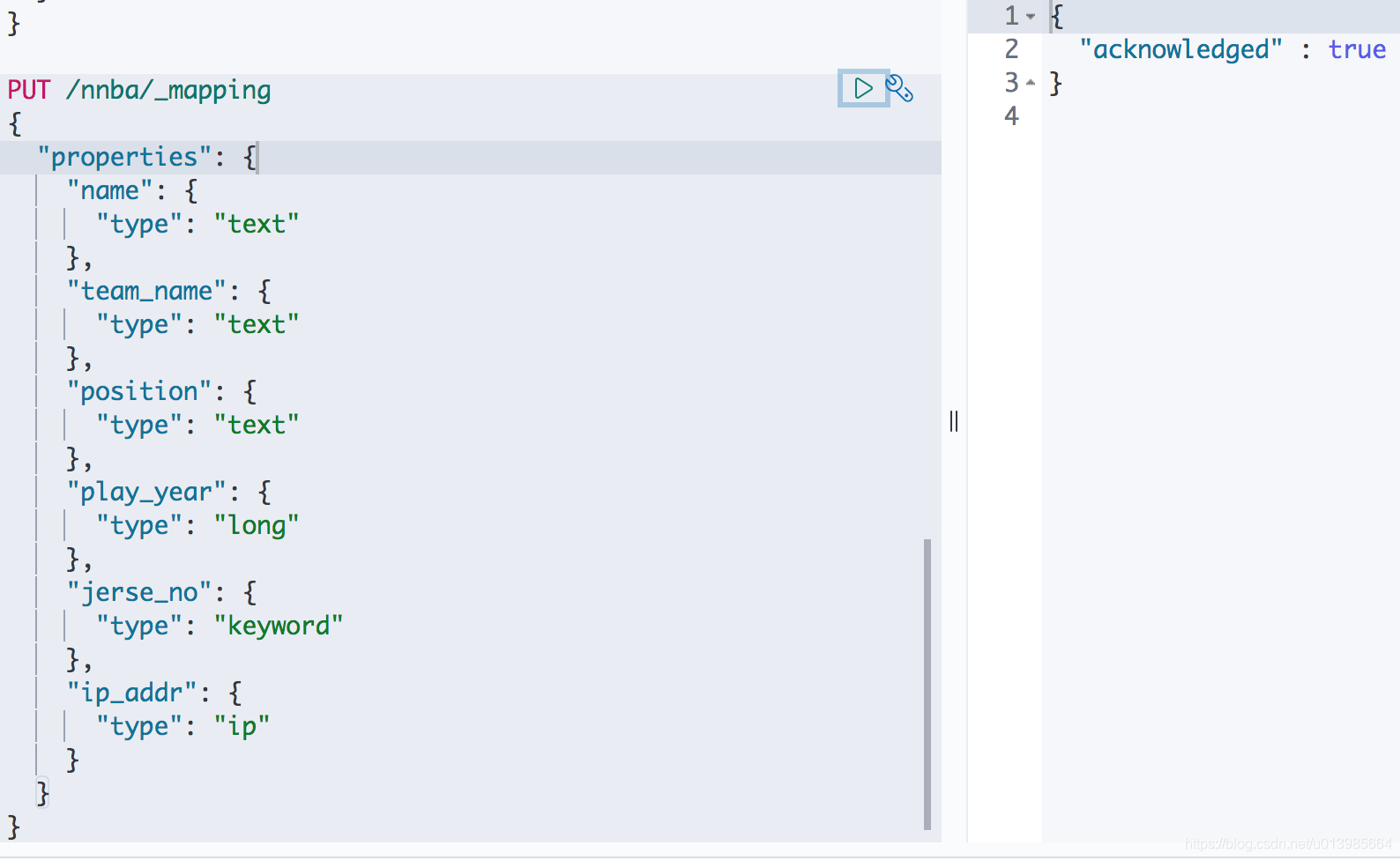
- 这里我们做一个演示大家就能感受到IP类型的作用了,首先我们给
nnba建立一个IP类型的索引。
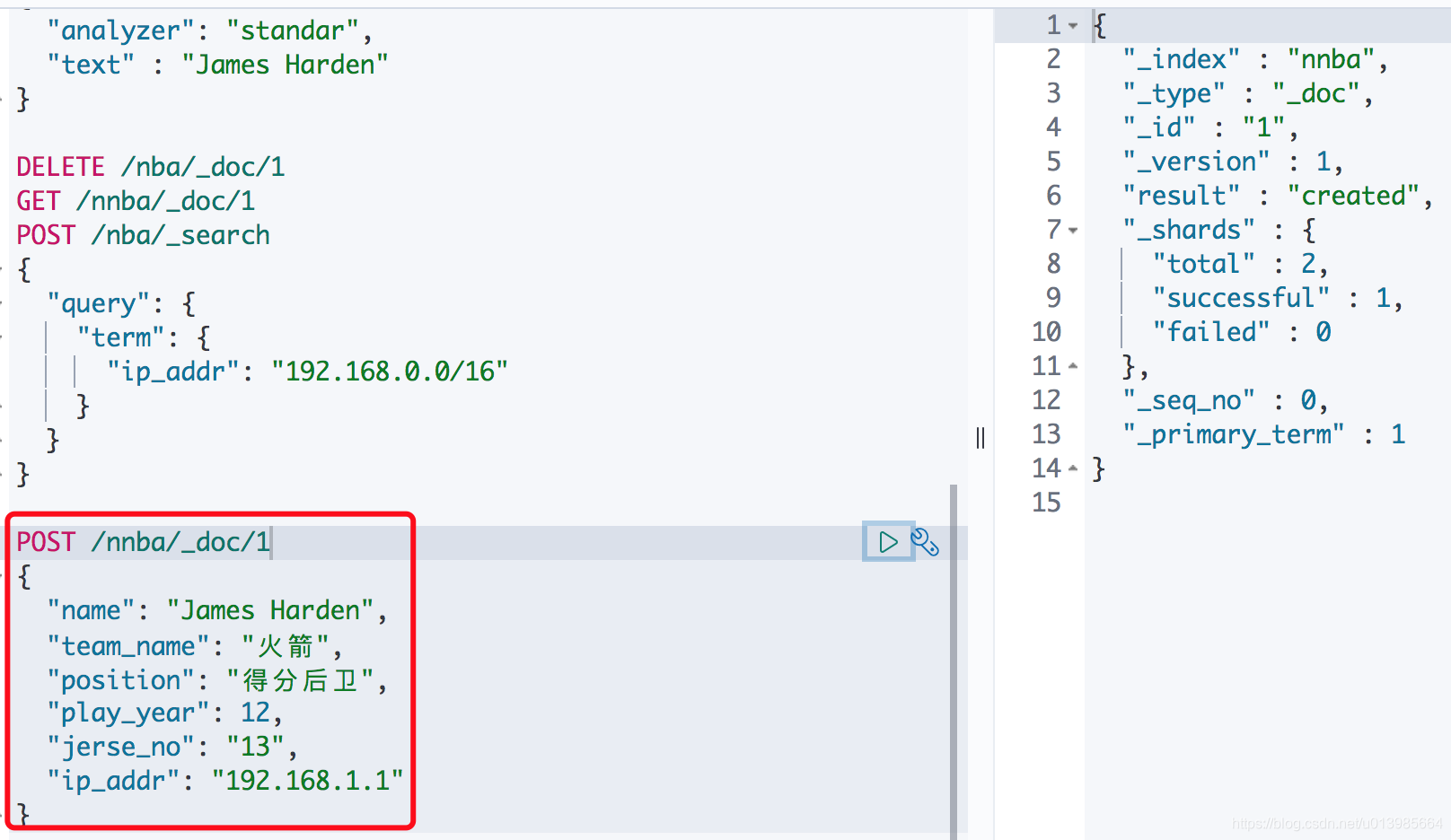
- 这里我们插入一条合适的数据。
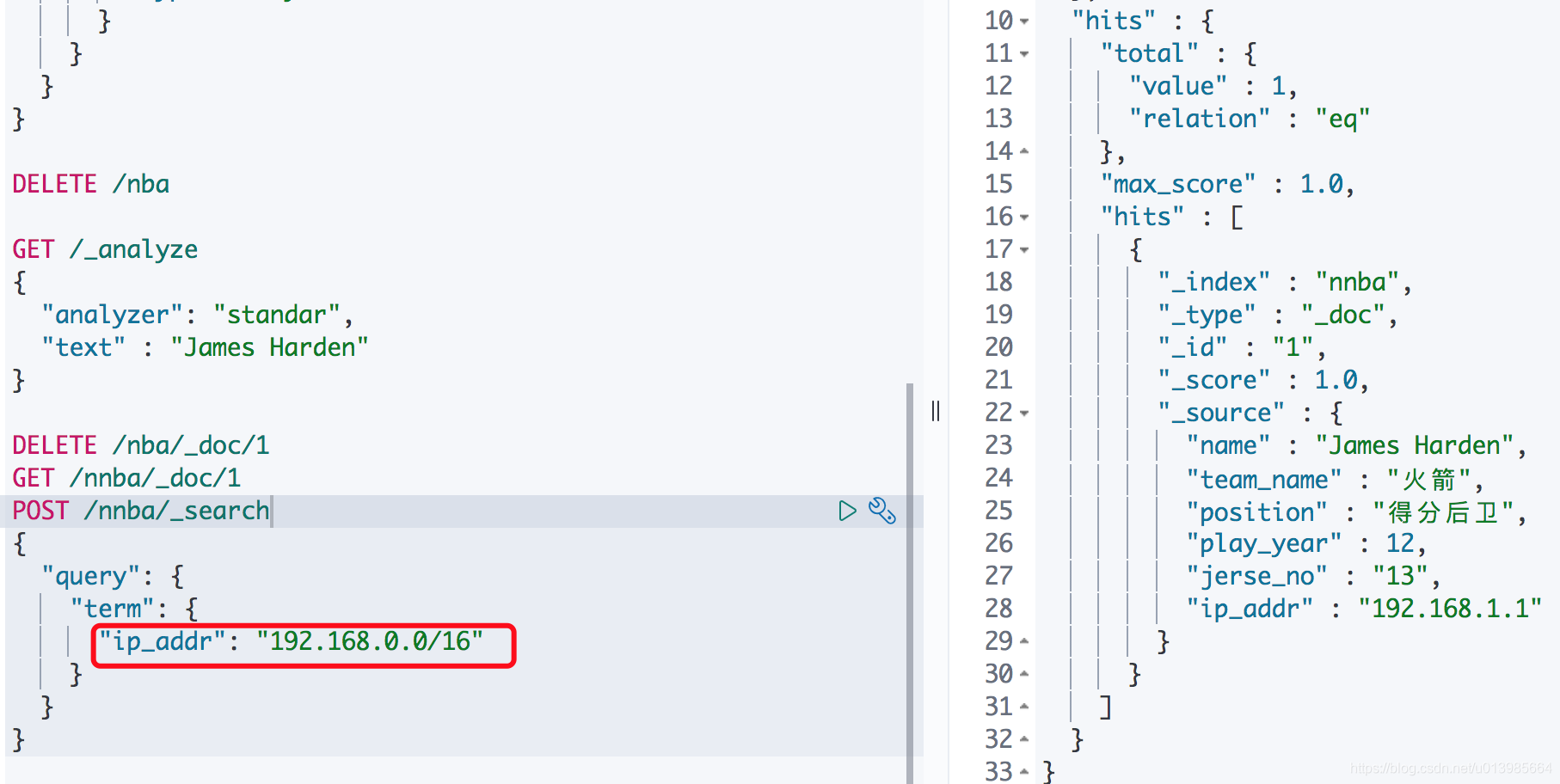
- 这里我们通过
192.168.0.0/16这个条件可以查询到对应的数据。192.168.0.0/16表明是查询192.168.0.0~192.168.255.255这个范围的数据。
- 这里我们插入一条合适的数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









