







转自 贝叶斯分类器(一)
http://blog.csdn.net/zhangph1229/article/details/52106301
机器学习 之 贝叶斯分类器
贝叶斯分类器学习笔记
http://blog.csdn.net/batuwuhanpei/article/details/51910349
判别模型与生成模型
机器学习的目标是得到一个模型使得其产生的行为(label)是我们所想看到的结果。那么我们如何来学习该模型呢?这里基于是否直接对 P(Y|X) 建模有两种策略:
- 第一种是判别式模型,即直接对 P(Y|X) 来进行建模,例如线性回归模型,SVM,决策树等,这些模型都预先制定了模型的格式,所需要的就是通过最优化的方法学到最优参数 Θ 即可;
- 第二种是生成式模型,这种策略并不直接对
P(Y|X)
进行建模,而是先对联合概率分布
P(X,Y)
进行建模,然后依据贝叶斯公式
P(Y|X)=P(X,Y)P(X)间接的得到我们所期望的模型 P(Y|X) ,这种策略最常见的算法就是我们接下来要介绍的贝叶斯分类器算法
贝叶斯分类器适用情况:对数据量大的问题十分适用
0. 基本知识
为了能更好的理解贝叶斯分类器,本节首先讲述有关概率的基础知识,为后面概率的推到打下基础。
- 加法公式
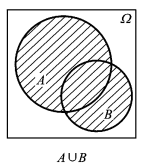
对于任意两个事件 A,B ,有 P(A∪B)=P(A)+P(B)−P(A∩B)
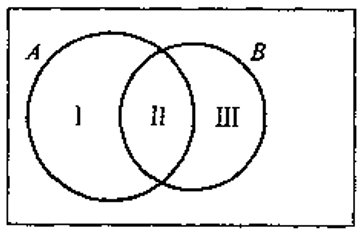
加法公式的示例如图0.1所示,图0.2将 AUB 分成两两不相容的三个事件 I、II、III ,则有,
A∪B=I∪II∪III,
A=I∪II,
B=II∪III,
于是,P(A∪B)=P(I)+P(II)+P(III)=P(A)+P(B)−P(A∩B).
图0.1 两个事件的并事件
图0.2 A∪B 分成两两不相容的三个事件 - 乘法公式与条件概率
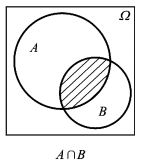
事件 A,B 同时发生的概率是:
P(A∩B)=P(A)P(B|A)=P(B)P(A|B)
公式中的 P(A|B) 是指在事件 B 条件下事件 A 发生的概率,又称作条件概率。
图0.3 两个事件的交事件
- 贝叶斯法则
由 P(A∪B)=P(B|A)P(A)=P(A|B)P(B) 立得, (此处最左边应该是A交B吧)
P(B|A)=P(A|B)P(B)P(A)
在机器学习中我们通常写为:
P(h|D)=P(D|h)P(h)P(D)
用 P(h) 表示在没有训练数据前假设 h 拥有的初始概率。 P(h) 被称为h的先验概率。先验概率反映了关于h是一正确假设的机会的背景知识。
机器学习中,我们关心的是 P(h|D) ,即给定D时h的成立的概率,称为h的后验概率。
- 全概率公式
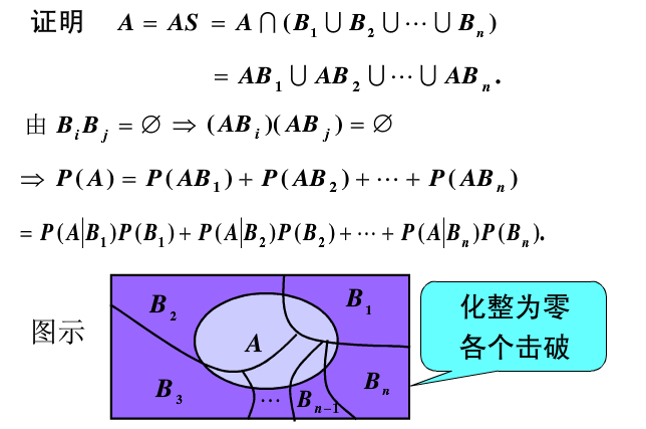
设S是实验E的样本空间, B1,B2,...,Bn 是E的n个两两不相容的时间,且有 B1∪B2∪...∪Bn=S ,也就是说S划分成n个两两不相容的时间: B1,B2,...,Bn.
又若A是实验E的任一事件,则有A=AS=A(B1∪B2∪...∪Bn)=AB1∪AB2∪...A∪Bn
其中
这样就将A分成n个两两不相容的事件: AB1,AB2,...,ABn. 设P(B_{i})>0(i=1,2,…,n),就有P(A)=∑i=1nP(ABi)=∑i=1nP(A|Bi)P(Bi)我们称上述公式为全概率公式。
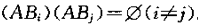
贝叶斯分类器
通过对两种建模策略的描述知道贝叶斯分类器算法的建模策略是第二种,即生成式模型。那么如何来对联合分布 P(x,y) 来建模呢?我依据贝叶斯公式知道 P(x,y)=P(y)P(x|y) ,在这里称 P(y) 为标签 y 的先验概率, P(x|y) 是样本 x 相对于标签 y 的条件概率(似然)。这样就把如何计算 P(x,y) 问题转换为了如何计算标签的先验概率 P(y) 和似然 P(x|y) 。
- 先验分布
P(y)
估计方法:
我们知道先验概率 P(y) 表示的是各个label在样本空间内所占的比例,依据大数定律可以知道当样本空间足够大,样本足够充足的时候,我们可以通过label对应样本出现的频率来对 P(y) 进行估计 - 似然P(X|Y)估计方法:
在这里通常有两种方法来进行估计:
- 一种是类似于先验分布,通过统计频率的方式来计算似然 P(x|y) ,但是这里要涉及到计算各个不同属性的联合概率,当属性值很多且样本量很大的时候,估计会很麻烦;
- 第二种方式是使用极大似然法来进行估计。极大似然法是首先要假定条件概率
P(x|y)
服从某个分布,然后基于样本数据来对概率分布的参数进行估计。但是这种方法的准确性严重依赖于所假设的分布,如果假设的分布符合潜在的真实数据分布,则效果不错,否则效果会很糟糕。在现实应用中,这种假设通常需要一定的经验。
对于极大似然,记标签 y 的条件概率为 P(x|y) ,假设 P(x|y) 有确定的形式且被参数向量 Θ 唯一确定,那么任务就是利用训练集来估计参数。将 P(x|y) 记为 P(x|y;Θ) 。因此对于参数 Θ 进行极大似然估计,就是在 Θ 的取值范围内寻找一组合适的参数使得 P(x|y) 最大,也就是找一组能够使得数据 (x,y) 出现的可能性最大的值。令 Dy 为训练集中标签为 y 的样本集合,假设样本都是独立同分布采样,那么参数 Θ 对于数据集 Dy 的对树似然为L(Θ;y)=logP(Dy|Θ;y)=∑x∈DylogP(x|Θ;y)那么参数 Θ 的极大似然估计 θ^=argmaxL(Θ;y)
1. 贝叶斯决策论
有了第0节的基础概率知识之后,本节开始介绍贝叶斯决策论(Bayesian decision theory)。贝叶斯决策论是概率框架下实施决策的基本方法。
设有N 种可能的类别标记,即
Y=c1,c2,...,cN
,则基于后验概率
P(ci|x)
可获得将样本x分类为
ci
所产生的期望损失(也称条件风险)为:
我们的目的是寻找一个方法使得条件风险最小化。为最小化总体风险,只需在每个样本上选择哪个能是条件风险 R(c|x) 最小化的类别标记,即
若目标是最小化分类错误率,则条件风险为
所以,最小化分类错误率的贝叶斯最优分类器为
通常情况下 P(c|x) 很难直接获得,根据我们已知的条件概率知识对公式1.4进行化简得
在某些情况下,可假定Y中每个假设有相同的先验概率,这样式子1.5可以进一步简化为公式1.6,只需考虑P(x|c)来寻找极大可能假设。
综合以上讨论,当前求最小化分类错误率的问题转化成了求解先验概率P(c)和条件概率(也称似然概率) P(x|c) 的估计问题。对于先验概率P(c)表达了样本空间中各类样本所占的比例,根据大数定理,当训练集包含充足的独立同分布样本时,P(c)可以通过各类样本出现的频率进行估计。整个问题就变成了求解条件概率 P(x|c) 的问题。
应用:
贝叶斯定理的应用:拼写检查
贝叶斯定理的一个应用就是拼写检查。我们定义正确的单词为c,错误的为w,当出现错误的时候,我们需要为用户提供最有可能的正确的单词。因此,这个问题就转化成了计算P(c|w),选取出最大的c。
由贝叶斯定理,我们可以知道:
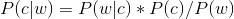
由于对于所有备选的c来说,对应的都是同样的w,所以P(w)是固定的,我们只要最大化分子就行。
P(c)可以通过在语料库中找出现频率最高的单词来计算,而P(w|c)则可以通过计算正确与错误单词的相似程度来算,也即两个单词的编辑距离。所以,我们只需要比较所有拼写相近的词在文本库的出现频率,挑出最大的就行。
2. 极大似然估计
极大似然轨迹源自于频率学派,他们认为参数虽然未知,但却是客观存在的规定值,因此,可以通过优化似然函数等准则确定参数数值。本节使用极大似然估计对条件概率进行估计。
令
Dc
表示训练集D中第c类样本组成的集合,假设这些样本是独立同分布的,则参数
θ
(
θ
是唯一确定条件概率
P(x|c)
的参数向量)对数据集
Dc
的似然函数是
对2.1求对数似然函数
因此求得 θ 的极大似然估计 θ^ 为
使用极大似然估计方法估计参数虽然简单,但是其结果的准确性严重依赖于每个问题所假设的概率分布形式是否符合潜在的真实数据分布,可能会产生误导性的结果。
3. 朴素贝叶斯分类器
从前面的介绍可知,使用贝叶斯公式来估计后验概率最大的困难是难以从现有的训练样本中准确的估计出条件概率 P(x|c) 的概率分布。朴素贝叶斯分类器为了避开这个障碍,朴素贝叶斯方法对条件概率分布作了条件独立性的假设。具体地,条件独立性假设是
公式3.2就是著名的朴素贝叶斯的表达式。
下面对先验概率P(c)和条件概率 P(xi|c) 进行极大似然估计求得后验概率。
令 Dc 表示训练集D中第c类样本组成的集合,先验概率的似然估计为
对于离散属性而言,令 Dc,xi 表示 Dc 中在第i个属性上取值为 xi 的样本组成的集合,则条件概率 P(x|c) 的似然估计为
而对于连输属性需要考虑其密度函数。
朴素贝叶斯分类算法主要分成如下三步:
- 计算先验概率P(c)和条件概率P(x|c)
- 计算后验概率 P(c|x)=P(c)∏di=1P(xi|c)
- 确定实例x的类 h∗(x)=argmaxc∈YP(c)∏di=1P(xi|c)
拉普拉斯平滑:使用极大似然估计可能会出现所要估计的概率值为0的情况,这样会影响到后验概率的结果,最终使得推荐分类产生偏差。使用贝叶斯估计而已解决这一问题。具体地,条件概率的贝叶斯估计是
当 λ=1 时称为拉普拉斯平滑(Laplace smoothing)。
同样先验概率的贝叶斯轨迹为
显然,拉普拉斯平滑修正了因训练集样本不充分造成的概率为0的问题,并且在训练集变大时,估计值也逐渐趋向于实际的概率值。
4. 半朴素贝叶斯分类器
在现实任务中朴素贝叶斯的假设条件(属性条件独立)往往不成立,因此,在评估实际问题时朴素贝叶斯方法往往失去了部分精度,所以人们尝试对属性的独立性进行一定程度的放松,由此产生了半朴素贝叶斯分类器的学习方法。
半朴素贝叶斯分类器的基本思想是适当考虑一部分属性之间的相互依赖关系,从而既不需要完全联合概率计算,又不至于彻底忽略了比较强的属性依赖关系。
独立依赖估计是半朴素贝叶斯分类器最常用的一种策略,也就是假设每个属性在类别之 外最多依赖于一个 其他属性,即
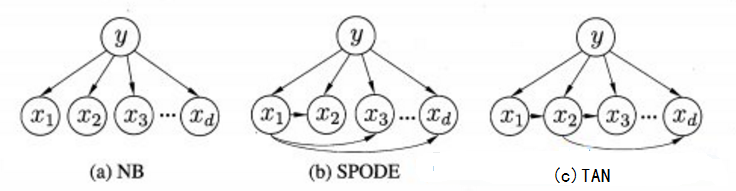
图4.1 属性依赖关系(图片来源于[1])
- SPODE(Super-Parent ODE)(超父独依赖估计):该方法假设所有属性都依赖于同一个属性,该属性被称为超父属性,如图4.1(b)所示 x1 是超父属性。
- TAN(Tree Augmented naive Bayes):该方法是在最大权生成树的基础上,首先通过计算两两属性之间的条件信息求出各个边的权值,然后构建完全图的最大带权生成树,最后加入类别y,增加从y到每个属性的有向边。如图4.1(c)所示为TAN属性的依赖关系。
参考文献
[1]: 周志华. 《机器学习》[M]. 清华大学出版社, 2016.
[2]: 李航. 《统计学习方法》[M].清华大学出版社,2013.
[3]: Tom M Michele. 《机器学习》[M].机械工业出版社,2003.















 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









