







统计一个文本中,出现次数最多的单词:单词全部小写,单词与单词之间以空格间隔
1.利用字典 key为单词 value为单词出现的次数
def mostString():
dict = {}
fr = open('preprocessing.txt')
k = 0
n = 0
for line in fr.readlines():
for s in line.strip().split(' '):
if s not in dict.keys():
dict[s] = 0
else:
dict[s] = dict[s] + 1
if dict[s]>=n:
k = s
n = dict[s]
#print(dict)
print(k)代码如上,利用一个字典来保存所有字典,value来保存每个单词的次数,当字典中没有该单词时,执行新增操作;若已经有该单词则执行更新操作,最后返回次数最多的单词即可。空间复杂度N 时间复杂度平均为N
2.字典树解法
字典树,又称为单词查找树,Tire数,是一种树形结构,它是一种哈希树的变种。
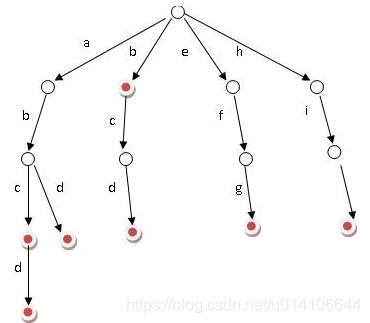
基本性质如下:
- 根节点不包含字符,除根节点外的每一个子节点都包含一个字符
- 从根节点到某一节点。路径上经过的字符连接起来,就是该节点对应的字符串
- 每个节点的所有子节点包含的字符都不相同
典型应用是用于统计,排序和保存大量的字符串(不仅限于字符串),经常被搜索引擎系统用于文本词频统计。
利用字符串的公共前缀来减少查询时间,最大限度的减少无谓的字符串比较,查询效率比哈希树高。
如果文本中的单词数量很多,并且大部分单词前缀都相同,那么利用第一种字典方式来保存所有单词,则会浪费许多空间,此时可以利用字典树来保存单词,充分利用最大公共前缀。
构造字典树节点:
class TrieNode:
def __init__(self, var=None, parent=None, num=0):
self.num = num
self.isEnd = False
self.son = {}
self.var = var
self.parent = parentnum 该字符在某种前缀中出现的次数
isEnd true标识某个单词以该字符结尾
var 该节点保存的字符
son 该节点所有叶子节点
parent 指向父节点的指针
1.构造函数:
root = None
def __init__(self):
self.root = TrieNode()2.在字典树中插入一个单词:
def insert(self, str):
if len(str)<=0:
return
node = self.root
for c in str:
if c not in node.son.keys():
node.son[c] = TrieNode(c, node, 1)
else:
node.son[c].num += 1
node = node.son[c]
node.isEnd = True遍历单词的每个字符,找到从根节点开始的一条路径来保存所有字符,若字符不存在则新建一个节点,若已经存在则更新计数,最后将单词最后一个字符指示变量isEnd置为true
2.在字典树中查询一个单词是否存在
def has(self, str):
if len(str)==0:
return False
node = self.root
for c in str:
if c not in node.son.keys():
return False
else:
node = node.son[c]
return node.isEnd从字典树的根节点开始,依次匹配单词的每个字符,若最终存在某条路径包含该单词所有字符,则观察最后一个字符的指示变量
3.计算以某个字符为前缀的所有单词总数
def countPrefix(self, prefix):
if len(prefix)==0:
return -1
node = self.root
for c in prefix:
if c not in node.son.keys():
return 0
else:
node = node.son[c]
return node.num找到该字符串的最后一个字符位置,返回计数值即可。
4.遍历字典树
def preOrder(self, node):
if node != None:
print (list(node.son.keys()))
for child in node.son.keys():
self.preOrder(node.son[child])5.计算出现次数最多的单词
def mostString(self):
max = [0]
r = [TrieNode()]
self.helper(self.root, max, r)
x = r[0]
print(x)
s = []
while x!=None:
s.append(x.var)
x = x.parent
s.reverse()
return s
def helper(self, node, max, r):
if node != None:
print (node.num, node.isEnd)
if node.isEnd and node.num >= max[0]:
r[0] = node
max[0] = node.num
print('r value ', max, r[0].var)
for child in node.son.keys():
self.helper(node.son[child], max, r)如上所示,遍历每一个节点,找到那些指示变量isEnd==true并且计数值最大的节点,从该节点沿parent指针回溯到根节点,然后倒序输出即可。
def mostString2():
dict = {}
t = Trie()
fr = open('preprocessing.txt')
for line in fr.readlines():
for s in line.strip().split(' '):
print(s)
t.insert(s)
#print(t.preOrder(t.root))
#print(t)
#t.preOrder(t.root)
#print(k)
print(t.has('chen'))
print(t.has('chendsfdsfsd'))
print(t.countPrefix('chen'))
print(t.mostString())问题:
1.python中是否支持对象数组,本来想利用对象数组来保存某节点的孩子节点集合的
2.python中参数传递问题,为求最大值,函数传递时使用max=[0] r=[TrieNode()],很别扭

max=0属于不可变对象可以理解,但是r=TrieNode() r应该是可变对象吧,但是这里好像也是不可改变的
测试一下:
def canchange(r):
r = TrieNode(2)
print('func inner ',r.var)
def mostString2():
dict = {}
t = Trie()
fr = open('preprocessing.txt')
for line in fr.readlines():
for s in line.strip().split(' '):
print(s)
t.insert(s)
#print(t.preOrder(t.root))
#print(t)
#t.preOrder(t.root)
#print(k)
print(t.has('chen'))
print(t.has('chendsfdsfsd'))
print(t.countPrefix('chen'))
print(t.mostString())
r = TrieNode(1)
print('before',r.var)
canchange(r)
print('after',r.var)
可知对象指针是不可变对象,函数传递属于值传递,好奇怪!
参考地址:














 1362
1362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









