







给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
就是找字符串中连续且字符不重复的子串,注意不是子序列,而是字串。例如“abcdafg”的结果为4,“aaaa”的结果为1。
一开始看到这个题目,想到了KMP算法中求取next数组的过程,但KMP中是用到最长前缀后缀的,并不能直接套用。这道题的思路的话,就是遍历一遍字符串,记录每个字符最新的位置pos(也用来判断该字符是否重复),然后同时也记录一个位置begin_pos,begin_pos是从它到遍历的最新位置 i 之间都没有重复字符的位置。这样子当我们遇到一个重复字符的时候,我们就可以用当前位置 i 减去begin_pos,就可以得到不重复字符的字串长度了,再从中得到最长的即可。文字可能稍微有点绕,下面用图简单展示下流程。
设给定的字符串为“abbcabc”,初始条件a、b、c的最新位置都为-1,而begin_pos则为0,最长长度max_len为0。

第一次循环由于a第一次出现,pos['a']为-1,所以begin_pos不变,只修改pos['a']为0。

第二次循环也是只改变了pos['b']的值。

第三次循环发现pos['b']不为-1,则代表b在前面出现过了,需要这个时候将判断 i - begin_pos 与max_len的大小,更新max_len的大小。然后,判断 begin_pos 与 pos['b']+1 的大小,将其更新为其中的最大值,下面出现的某次循环中将会解释为什么需要这个对比。

第四次循环由于pos['c']没有出现过,所以不会更新begin_pos,只是更新了pos['c']。

第五次循环,发现pos['a']出现过了,这个时候,可以看到,这里直接将begin_pos更新为旧的pos['a']+1及第一个b的位置,显然是不对的,因为两个a之间已经出现过重复的b了。这个时候的begin_pos应该还是按照原来的值不变。即此时begin_pos是大于pos['a']+1的,所以我们不需要更新它。

第六次循环,发现pos['b']出现过了,这个时候begin_pos小于pos['b'] + 1,即在begin_pos和i之前(都是开区间)并没有出现重复的字符,则我们直接让begin_pos更新为pos['b']+1就行了。
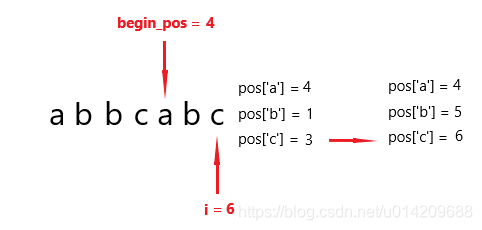
第七次循环和第六次循环是类似了,这里不再赘述了。
好了,循环内的处理已经说完了,通过上面的流程我们也很容易能够理解到begin_pos的作用及更新。
但是,在循环外还需要一个处理,因为对于“abbcabc”中最后的“abc”,循环中是没有判断到这个无重复字符字符串的长度的,而当循环结束时,我们可以看到i=7而begin_pos恰好就在a的位置即begin_pos=4,则显然“abc”的长度就是begin_pos-i=3了,判断然后更新max_len就行了。
下面是完整的代码:
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int pos[256];
int max_len = 0, begin_pos = 0, i = 0;
for (int j = 0; j < 256; ++j)
pos[j] = -1;
for (; i < s.length(); ++i) {
if (pos[s[i]] != -1) {
if (i - begin_pos > max_len) {
max_len = i - begin_pos;
}
begin_pos = begin_pos > pos[s[i]] + 1 ? begin_pos : pos[s[i]] + 1;
}
pos[s[i]] = i;
}
if (i - begin_pos > max_len) {
max_len = i - begin_pos;
}
return max_len;
}
};














 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









