







好久没写博客了。过去的一年很忙,公司对保密要求也很严格,绝大多数的技术成果都无法公开,有些还是个人的得意之作,不得不说是件非常遗憾的事儿。最近想改进先前开发的轮廓变形技术,需要对一维数据进行平滑,以得到更加理想的平滑轮廓,联想到以前介绍加权最小二乘变形的文章,对原程序做了点儿改动进行了实验,效果还挺满意。下面给大家分享一下。
原始的加权最小二乘滤波是用于处理二维图像的,且目的是为了滤除微弱边缘,保留较强边缘,因而给较强的梯度更大的权重,而给较小的梯度较大的权重。现在我们的目标变成了降低较强的干扰,而让曲线更加平滑,那我们反过来,给较小的梯度较小的权重,而给较大的梯度以较大的权重就好了。我们将权重函数改为:,其中
为x方向的导数。
下面上源代码:
function OUT = wlsFilter_1d(IN, lambda, alpha, L, smallNum)
if(~exist('L', 'var')),
L = log(IN+eps);
end
if(~exist('lambda', 'var')),
lambda = 1;
end
if(~exist('alpha', 'var')),
alpha = 1.0;
end
if(~exist('smallNum', 'var')),
smallNum=0.1;
end
k = length(IN);
dx = diff(L, 1, 1);
dx = lambda*(abs(dx)+smallNum).^alpha;
dx = padarray(dx, [1 0], 'post');
dx = dx(:);
% Construct a five-point spatially inhomogeneous Laplacian matrix
A = spdiags(dx,-1,k,k);
e = dx;
w = padarray(dx, 1, 'pre'); w = w(1:end-1);
D = 1+(e+w);
A = spdiags(D, 0, k, k)-A- A';
% Solve
OUT = A\IN(:);
OUT = reshape(OUT, k, 1);测试程序为:
close all;clc;
x=0:0.02:10;
x=reshape(x,length(x),1);
noise=zeros(size(x));
bgIdx=30;
endIdx=60;
noise(bgIdx:endIdx)=3*randn(endIdx-bgIdx+1,1);
y=0.2*x.^2+2*x+noise;
y1=0.2*x.^2+2*x;
figure,plot(x,y,'r-');
ylim([-5,50]);
%%
alpha=0.5;
lambda=100;
smallNum=0.1;
tic;
y2 = wlsFilter_1d(y,lambda,alpha,y/max(y(:)),smallNum);
toc;
t=toc-tic;
figure,plot(x,y2,'r-');
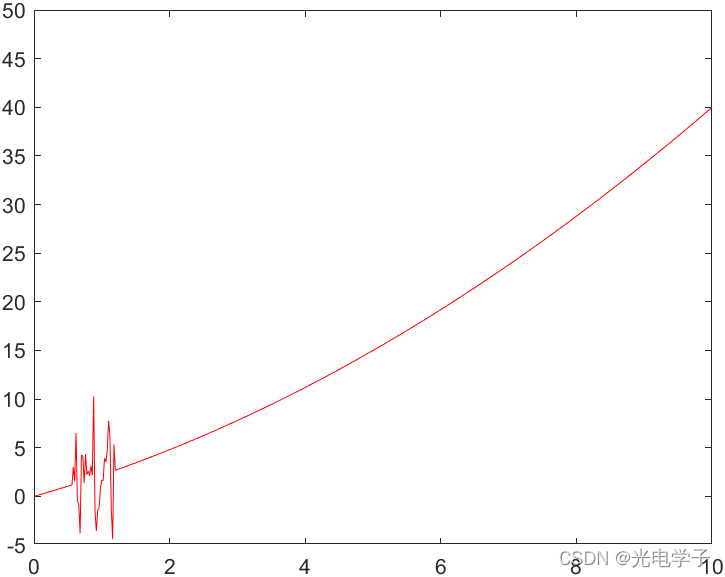
ylim([-5,50]);滤波前函数曲线(懒得加标注了):
滤波后:
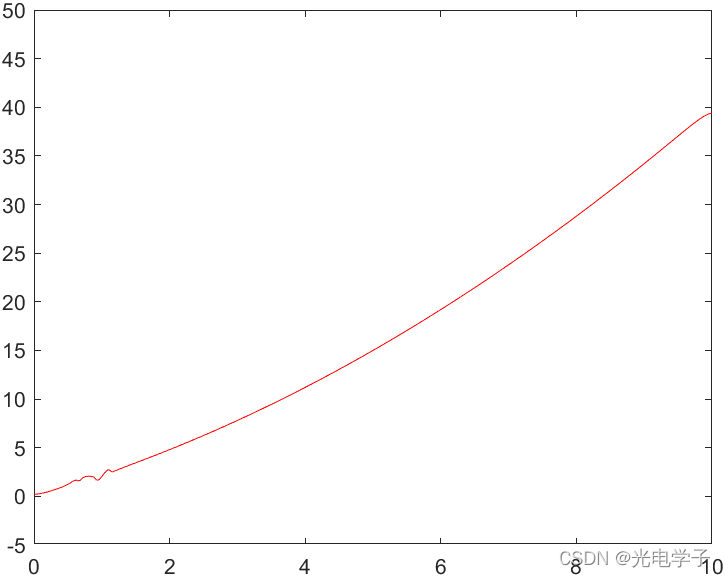
可以看出,曲线的平滑比较理想,异常数据带来的干扰几乎被抹平,而正常数据滤波前后的变化很小。
下面给出C++的实现(使用了Eigen库,因为仅作为示例程序,异常处理没怎么弄),
#include <vector>
#include <Eigen/Eigen>
#include <random>
#include <algorithm>
using namespace std;
using namespace Eigen;
using namespace cvflann;
typedef Eigen::SparseMatrix<double> SpMat;
typedef Eigen::Triplet<double> T;
int wlsFilter_1d(vector<double> &vecInput, vector<double> & vecOutput, vector<double> &vecL, double lambda, double alpha, double smallNum)
{
int number = vecInput.size();
if (vecL.size() != number || number < 2) return -1;
vector<double> vecDx(number + 1);
vecDx[0] = 0;
vecDx[number] = 0;
for (int i = 1; i < number; i++)
{
vecDx[i] = lambda * (pow(abs(vecL[i] - vecL[i - 1]) + smallNum, alpha));
}
vector<Eigen::Triplet<double>> tripletList(3 * number - 2);
for (int i = 0; i < number; i++)
{
tripletList[i] = T(i, i, 1 + vecDx[i] + vecDx[i + 1]);
}
for (int i = 1; i < number; i++)
{
tripletList[number + i - 1] = T(i, i - 1, -vecDx[i]);
}
for (int i = 1; i < number; i++)
{
tripletList[2 * number + i - 2] = T(i - 1, i, -vecDx[i]);
}
SpMat A(number, number);
A.setFromTriplets(tripletList.begin(), tripletList.end());
Eigen::VectorXd b(number);
for (int i = 0; i < number; i++)
{
b(i) = vecInput[i];
}
// Solving:
Eigen::SimplicialCholesky<SpMat> solver(A);
//SimplicialLLT<SpMat> solver(A);
Eigen::VectorXd x = solver.solve(b);
for (int i = 0; i < number; i++)
{
vecOutput.push_back(x[i]);
}
return 0;
}
int main()
{
vector<double> x;
double temp = 0;
double step = 0.02;
while (temp < 10)
{
x.push_back(temp);
temp += step;
}
vector<double> y(x.size());
int bgIdx = 30;
int endIdx = 60;
for (int i = 0; i < x.size(); i++)
{
y[i] = 0.2*x[i] * x[i] + 2 * x[i];
}
for (int i = bgIdx; i < endIdx; i++)
{
y[i] += 3 * rand_double(1.0, -1.0);
}
double ymax = *max_element(y.begin(), y.end());
vector<double> vecL(x.size());
for (int i = 0; i < vecL.size(); i++)
{
vecL[i] = y[i] / ymax;
}
double alpha = 0.5;
double lambda = 100;
double smallNum = 0.1;
vector<double> yfilt;
int ret = wlsFilter_1d(y, yfilt, vecL, lambda, alpha, smallNum);
return 0;
} 耗时不到1ms(有波动,基本不超3ms):
而使用matlab的话,耗时约26ms:
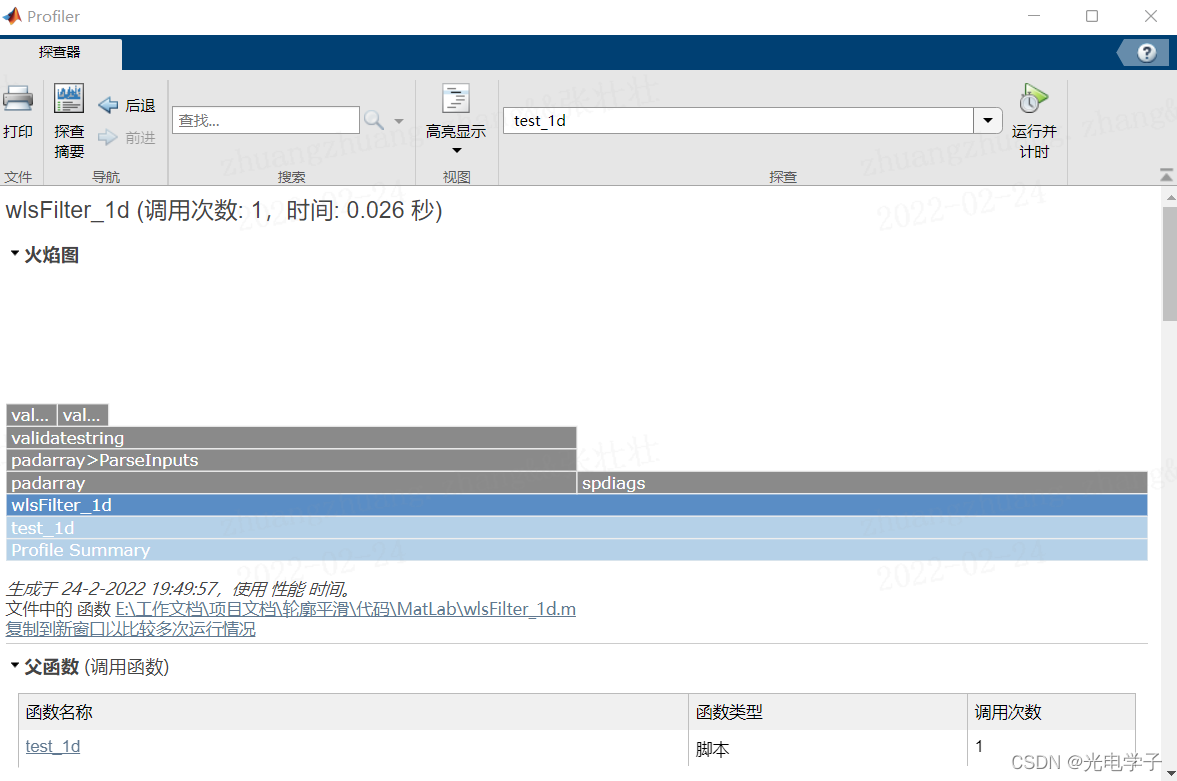
可见,基于Eigen库的C++程序执行效率的确远高于MatLab程序。
引入更高阶的导数的做法与之类似,这里就不介绍了。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









