







前言:隐马尔科夫的相关概念就不多说了,就是一个三元组(A,B,Pi),分别表示转移概率,发射概率和初始状态概率。
首先是语料库的训练部分:
#!/usr/bin/python
#-*-coding:utf-8
import sys
import math
import pdb
state_M = 4
word_N = 0
A_dic = {}
B_dic = {}
Count_dic = {}
Pi_dic = {}
word_set = set()
state_list = ['B','M','E','S']
line_num = -1
# 语料库 这里用的是人民日报已经人工分词的语料库
INPUT_DATA = "RenMinData.txt"
# 初始状态概率
PROB_START = "prob_start.py"
# 发射状态概率
PROB_EMIT = "prob_emit.py"
# 转移状态概率
PROB_TRANS = "prob_trans.py"
def init():
global state_M
global word_N
for state in state_list:
A_dic[state] = {}
for state1 in state_list:
A_dic[state][state1] = 0.0
for state in state_list:
Pi_dic[state] = 0.0
B_dic[state] = {}
Count_dic[state] = 0
# 输入词语 输出状态 B代表其实字,M代表中间字,E代表结束字,S代表单字成词
def getList(input_str):
outpout_str = []
if len(input_str) == 1:
outpout_str.append('S')
elif len(input_str) == 2:
outpout_str = ['B','E']
else:
M_num = len(input_str) -2
M_list = ['M'] * M_num
outpout_str.append('B')
outpout_str.extend(M_list)
outpout_str.append('S')
return outpout_str
# 输出模型的三个参数:初始概率+转移概率+发射概率
def Output():
start_fp = open(PROB_START,'w')
emit_fp = open(PROB_EMIT,'w')
trans_fp = open(PROB_TRANS,'w')
print("11111111")
print ("len(word_set) = %s " % (len(word_set)))
for key in Pi_dic:
Pi_dic[key] = Pi_dic[key] * 1.0 / line_num
# start_fp.write(str(start_fp)+str(Pi_dic))
print(start_fp,Pi_dic)
for key in A_dic:
for key1 in A_dic[key]:
A_dic[key][key1] = A_dic[key][key1] / Count_dic[key]
# trans_fp.write(str(trans_fp)+str(A_dic))
print(trans_fp,A_dic)
for key in B_dic:
for word in B_dic[key]:
B_dic[key][word] = B_dic[key][word] / Count_dic[key]
emit_fp.write(str(emit_fp)+str(B_dic))
print(emit_fp,B_dic)
start_fp.close()
emit_fp.close()
trans_fp.close()
def main():
ifp = open(INPUT_DATA,encoding='utf-8')
init()
global word_set
global line_num
for line in ifp:
line_num += 1
if line_num % 10000 == 0:
print (line_num)
line = line.strip()
if not line:
continue
# line = line.decode("utf-8","ignore")
word_list = []
for i in range(len(line)):
if line[i] == " ":continue
word_list.append(line[i])
word_set = word_set | set(word_list)
lineArr = line.split(" ")
line_state = []
for item in lineArr:
# 一句话对应一行连续的状态
line_state.extend(getList(item))
if len(word_list) != len(line_state):
print (sys.stderr,"[line_num = %d][line = %s]" % (line_num, line.encode("utf-8",'ignore')))
else:
for i in range(len(line_state)):
if i == 0:
# 计算转移概率
Pi_dic[line_state[0]] += 1
Count_dic[line_state[0]] += 1
else:
# 计算发射概率
A_dic[line_state[i-1]][line_state[i]] += 1
Count_dic[line_state[i]] += 1
# if not B_dic[line_state[i]].has_key(word_list[i]):
if word_list[i] not in B_dic[line_state[i]]:
B_dic[line_state[i]][word_list[i]] = 0.0
else:
B_dic[line_state[i]][word_list[i]] += 1
Output()
ifp.close()
if __name__ == "__main__":
main()#!/usr/bin/python
#-*-coding:utf-8
import os
import sys
import pdb
def load_model(f_name):
ifp = open(f_name, 'rb')
return eval(ifp.read())
prob_start = load_model("prob_start.py")
prob_trans = load_model("prob_trans.py")
prob_emit = load_model("prob_emit.py")
def viterbi(obs, states, start_p, trans_p, emit_p):
V = [{}] #tabular
path = {}
for y in states: #init
V[0][y] = start_p[y] * emit_p[y].get(obs[0],0)
path[y] = [y]
for t in range(1,len(obs)):
V.append({})
newpath = {}
for y in states:
(prob,state ) = max([(V[t-1][y0] * trans_p[y0].get(y,0) * emit_p[y].get(obs[t],0) ,y0) for y0 in states if V[t-1][y0]>0])
V[t][y] =prob
newpath[y] = path[state] + [y]
path = newpath
(prob, state) = max([(V[len(obs) - 1][y], y) for y in states])
return (prob, path[state])
def cut(sentence):
#pdb.set_trace()
prob, pos_list = viterbi(sentence,('B','M','E','S'), prob_start, prob_trans, prob_emit)
return (prob,pos_list)
if __name__ == "__main__":
test_str = u"长春市长春节讲话。"
prob,pos_list = cut(test_str)
print (test_str)
print (pos_list)
test_str = u"他说的确实在理."
prob,pos_list = cut(test_str)
print (test_str)
print (pos_list)
test_str = u"毛主席万岁。"
prob,pos_list = cut(test_str)
print (test_str)
print (pos_list)
test_str = u"我有一台电脑。"
prob,pos_list = cut(test_str)
print (test_str)
print (pos_list)
test_str = u"我不喜欢你。"
prob, pos_list = cut(test_str)
print(test_str)
print(pos_list)
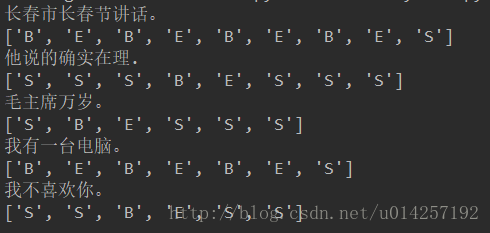














 769
769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









