







现在,您已经了解了深度学习在医学图像分类问题上的一些前沿应用。
本文将介绍第一课第一周6-10节的内容。主要讲解构建一个分类模型去识别胸片的肿块。以及分类模型将面临的三个挑战:类不平衡挑战、多任务挑战和数据集大小挑战。本节重点解决类不平衡挑战。详细介绍了loss的算法,以及为何要做加权loss。以及在作业中,手把手带你写加权loss.
我们将介绍如何为使用胸部X光片检测多个疾病的医学成像任务构建自己的深度学习模型。
我们将介绍一个胸部X光解释模型的训练过程,并看看在这个过程中你将面临的关键挑战,以及你如何成功地应对这些挑战。
我们先来看看胸部X光片的判读任务。胸部X光片是医学上最常见的诊断成像方法之一,大约一年有20亿个胸部X光片。
胸部X光检查对于发现许多疾病至关重要,包括肺炎和肺癌,这些疾病每年影响着全世界数百万人。
现在,一位接受过胸部X光片解释训练的放射科医生会查看胸部X光片,观察肺部、心脏和其他区域,以寻找可能提示患者是否患有肺炎、肺癌或其他疾病的线索。
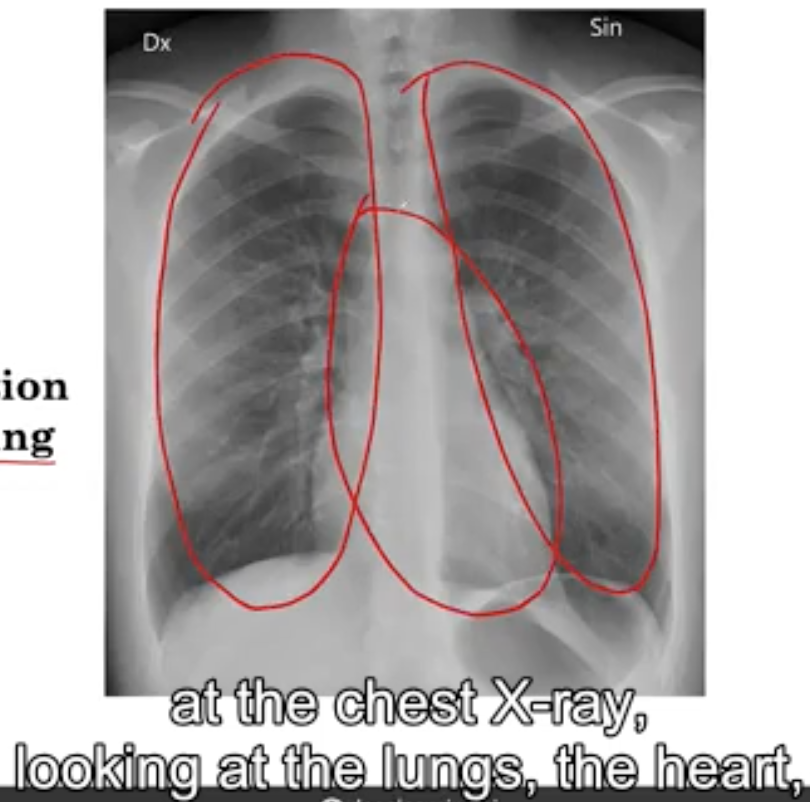
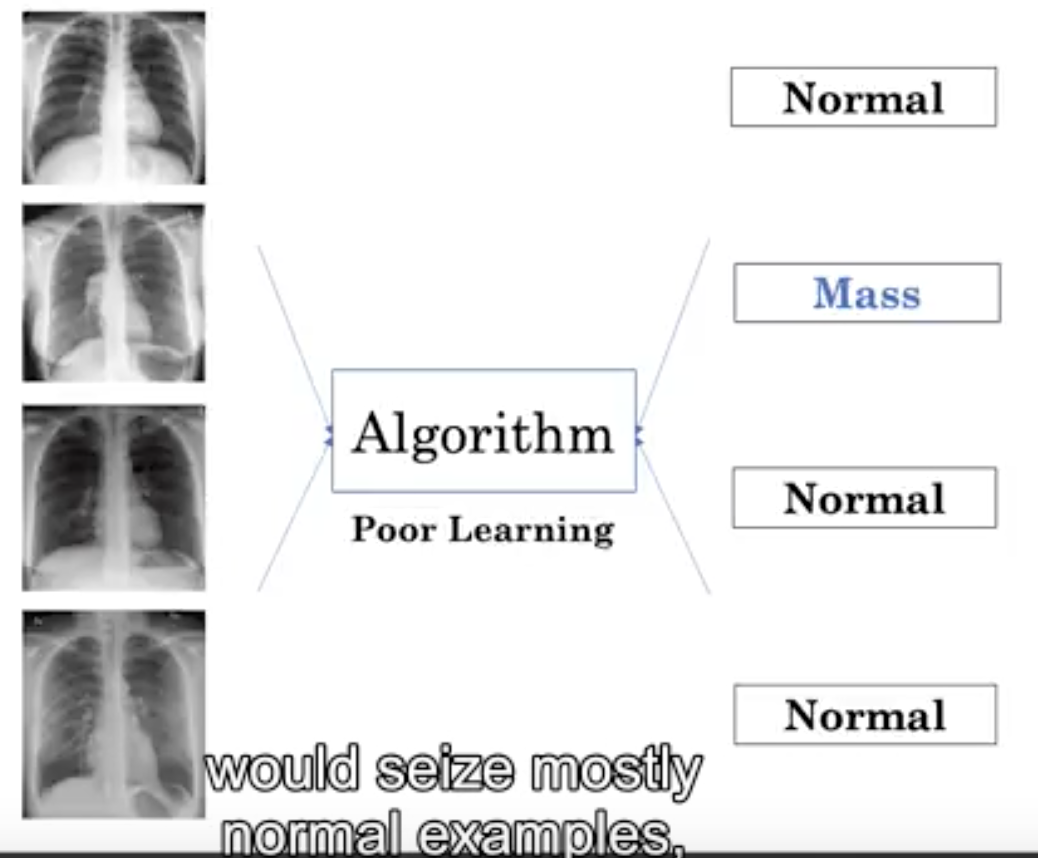
让我们看看一个叫做肿块(Mass)的异常。我不打算首先定义什么是肿块,但让我们看三张包含肿块的胸部X光片和三张正常的胸部X光片。

所以,你大概知道什么是肿块了吗?肿块被定义为病变或换句话说,在胸部X光片上看到的直径大于3厘米的组织损伤。让我们看看如何训练我们的算法来识别 mass。
Training, prediction, and loss
我们有胸部X光片的图像,想通过一个算法去识别它们是否含有肿块。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cRYcn4hk-1625826753176)(https://files.mdnice.com/user/15745/e18d5f92-f859-401a-8869-76a61893b145.png)]
这个算法可以有不同的名字。您可能听说过深度学习算法或模型、神经网络或卷积神经网络等术语。
该算法以分数的形式生成输出,分数是图像包含肿块的概率。
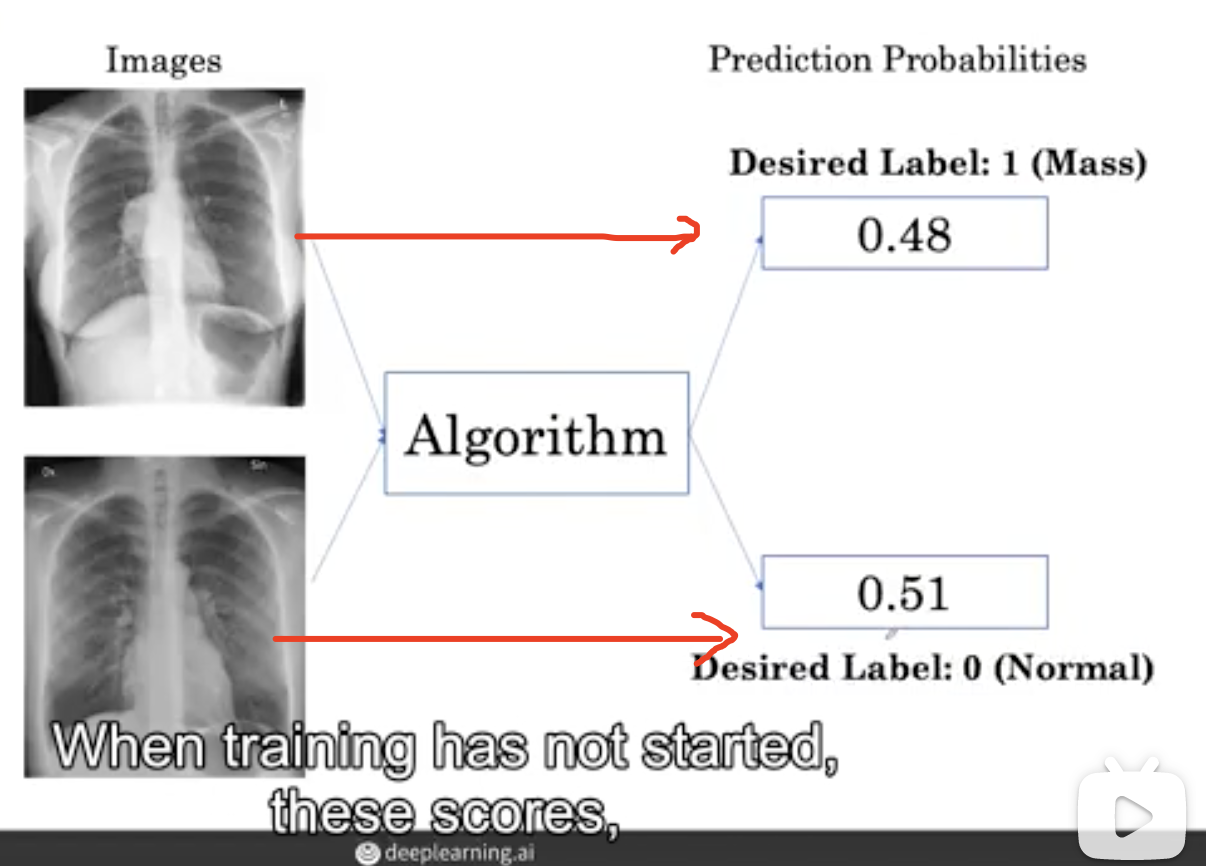
上图中第一幅图像实际上有肿块,但算法输出的肿块的概率为0.48,而下面那个正常的图像肿块的概率被输出为0.51。
因此,当训练还没有开始,这些分数,这些概率输出将不符合期望的标签。因此,我们要去训练它。
假设 mass 的期望标签是1,normal的标签是0。您可以看到0.48与1相距甚远,而0.51与期望的0标签相差甚远。
我们可以通过计算一个损失函数来测量这个误差。
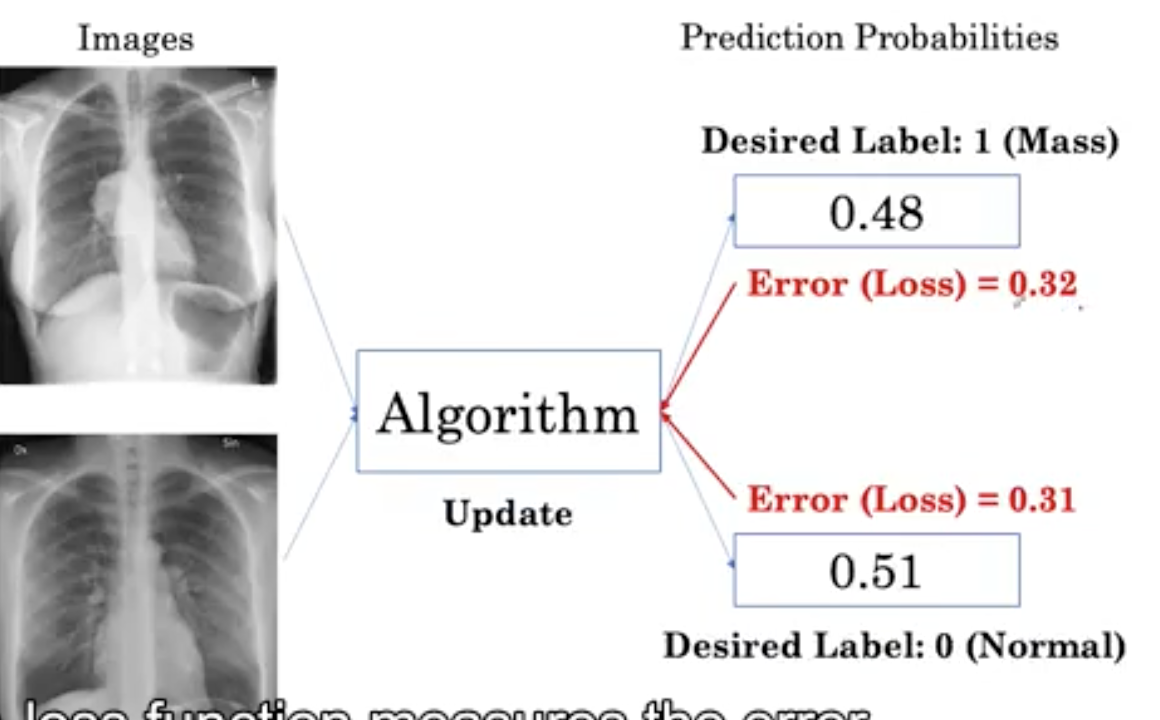
损失函数测量我们的输出概率和期望的标签之间的误差。第一幅图像的误差为0.32, 第二幅为0.31。损失值的计算之后会讲。
当我们算法迭代几次后,一组新的图像和期望的标签被呈现给该算法,因为它学会随着时间的推移产生更接近所需标签的分数。
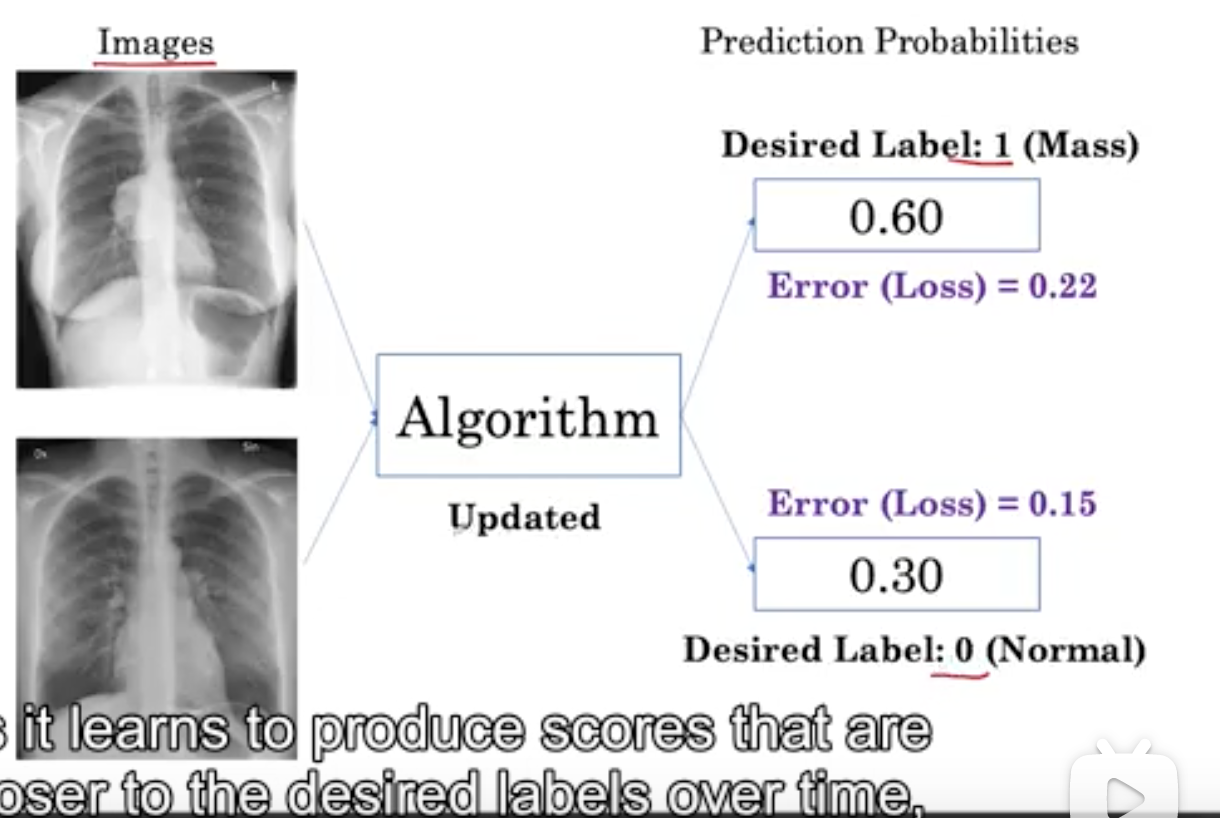
这里,第一幅图像的概率增加到了0.6,越来越接近1, 第二幅图像的概率降到了0.3, 越来越接近0。loss值也越来越小。
三个挑战
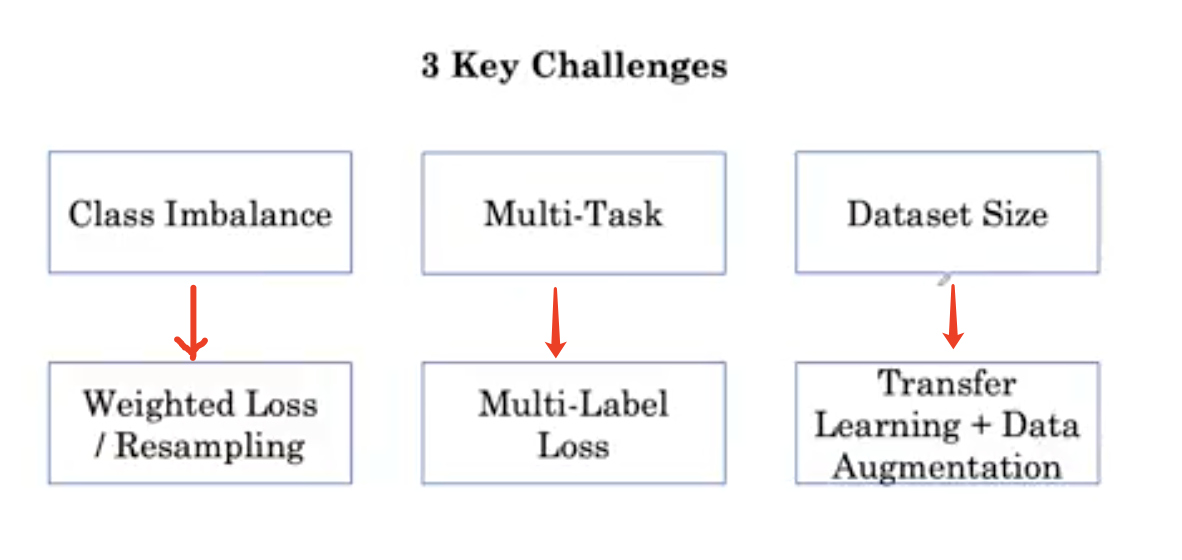
我们将讨论医学图像训练算法的三个关键挑战:类不平衡挑战、多任务挑战和数据集大小挑战。对于每一个挑战,我们将介绍一到两种应对方法。
- 类别不平衡:可以使用加权的 loss weighted loss, 或者是均衡采样(resampling)
- 多任务: 多标签loss
- 数据集大小: 迁移学习 + 数据增强
类别不平衡
我们更详细的来讨论一下类别不平衡。在医学数据集中,非疾病和疾病的例子并不相同。
这反映了现实世界中疾病的流行率或频率,在这里我们看到正常人的例子比肿块的例子多得多,特别是当我们观察健康人群的X光时。在一个医学数据集中,你可能会看到正常例子是肿瘤例子的100倍。
损失函数的计算
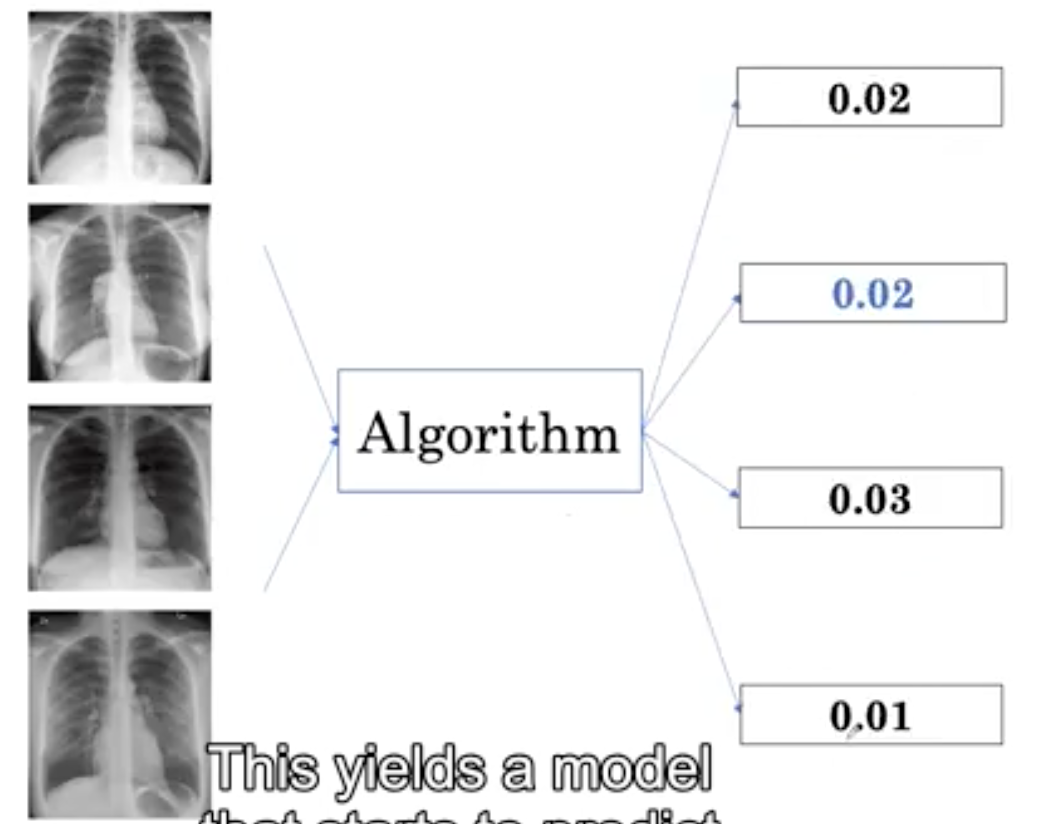
继续上边的类别不平衡的例子,这就给算法学习带来了一个问题,即大多数情况下算法都会抓住正常的例子。如图,刚开始model为每个人预测一个非常低的患病概率,并且不能确定一个例子什么地方有疾病。
让我们看看如何将这个问题追溯到我们用来训练算法的损失函数。我们还将了解如何在数据不平衡的情况下修改这个损失函数。
这个损失叫做二进制交叉熵损失,它衡量的是一个分类模型的性能,它的输出在0到1之间,让我们看一个例子,看看这个损失函数是如何计算的。
关于交叉熵损失函数,我们之前也介绍过,欢迎阅读
这里我们有一个胸部x光片的例子,其中包含一个肿块,算法输出的概率为0.2。这里的0.2是根据算法Y等于1的概率,这个例子是肿块的概率。现在,我们可以用损失函数来计算这个例子中的loss。

如图所示, l o s s = − l o g 0.2 = 0.7 loss = -log0.2 = 0.7 loss=−log0.2=0.7

上图中,label=0,所以是一个阴性例子。我们计算loss使用 y=0 那一行的公式。网络输出的概率是0.7,但是我们要计算的y=0的概率,为1-0.7=0.3, 因此
l o s s = − l o g ( 1 − 0.7 ) = 0.52 loss=-log(1-0.7)=0.52 loss=−log(1−0.7)=0.52
我们已经学会了如何计算一个例子的loss,让我们来看看它是如何应用到一堆例子中的。

这里我们有六个正常的例子和两个肿块(mass)的例子。 注意这里的P2、P3、P4是患者id,当训练还没有开始时,假设算法对所有的例子产生了0.5的输出概率,然后可以计算每个例子的损失。
对于一个normal的例子,我们将使用log(1-0.5),结果是0.3。对于一个mass例子,我们将使用log0.5,也是0.3。
我们计算总的loss
loss = 2 mass * 0.3 + 6 noraml * 0.3
所以请注意,大部分对损失的贡献是来自 normal 的例子,而不是来自 mass 的例子。
因此,该算法在不增加 mass 样本的相对权重的前提下,对更新后的样本进行优化以得到正常样本。实际上,这并不能产生很好的分类器。这就是类别不平衡的问题。
解决类不平衡问题的方法是修改损失函数,对正常类和 mass 类进行不同的加权。Wp是我们分配给 mass 例子的权重,Wn指正常例子的权重。
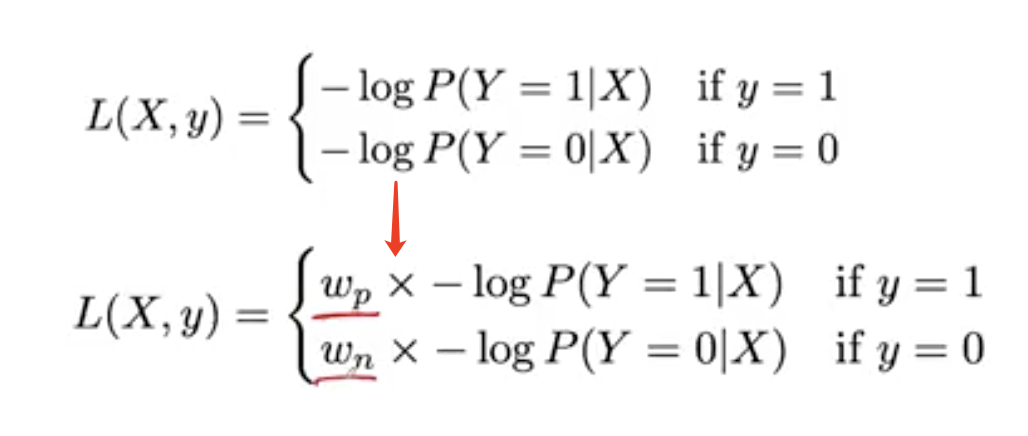

这里。我们的 W p = 6 / 8 W_p=6/8 Wp=6/8 W n = 2 / 8 W_n=2/8 Wn=2/8
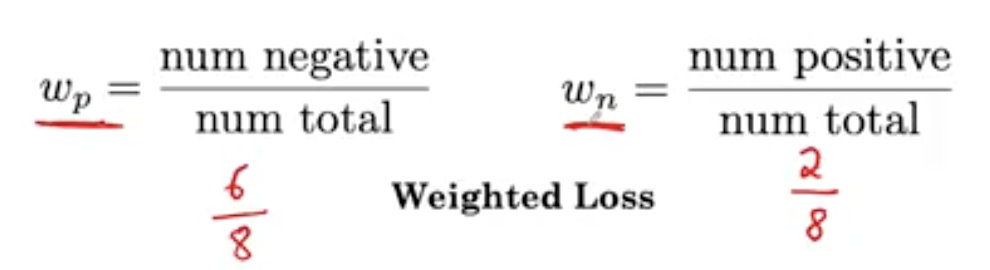
数量越多的类别权重越低,数量越少的样本权重越高。
然后,你可以看到,如果你把 2 个 mass 例子中的总损耗加起来,我们得到0.45,6个正常的例子的总loss也是0.45。
从正类和负类得到的损失贡献是相同的。因此,这是一个使用权重修改损失的想法,在这种方法中称为加权损失,以解决类不平衡问题。
学到这里,我们应该完成第二次作业
本周作业解读 加权loss
作业文件:AI4M_C1_W1_lecture_ex_02
- 首先,我们认为的构造y_true, y_pred_1, y_pred_2.分别表示标签,model1的输出,model2的输出
y_true = np.array(
[[1],
[1],
[1],
[0]])
print(f"y_true: \n{y_true}")
# Make model predictions that are always 0.9 for all examples
y_pred_1 = 0.9 * np.ones(y_true.shape)
print(f"y_pred_1: \n{y_pred_1}")
print()
y_pred_2 = 0.1 * np.ones(y_true.shape)
print(f"y_pred_2: \n{y_pred_2}")
y_true:
[[1]
[1]
[1]
[0]]
y_pred_1:
[[0.9]
[0.9]
[0.9]
[0.9]]
y_pred_2:
[[0.1]
[0.1]
[0.1]
[0.1]]
- 我们来计算两个model的loss
loss_reg_1 = -1 * np.sum(y_true * np.log(y_pred_1)) + \
-1 * np.sum((1 - y_true) * np.log(1 - y_pred_1))
注意: 从上面图中的公式如何转到这里的公式的。喜欢研究的同学可以深入探讨一下。头疼的同学,可以直接调用这个的公式。
+ When the model 1 always predicts 0.9, the regular loss is 2.6187
- When the model 2 always predicts 0.1, the regular loss is 7.0131
我们这里遇到了类别不平衡,例子中有3个阳性,1个阴性。当预测值始终为0.1时比始终为0.9,损失函数会产生更大的loss值(model2的结果),因为数据是不平衡的。
当类不平衡具有更多正标签时,正则损失函数意味着预测值高达0.9的模型比预测值低达0.1的模型表现更好
- 设置类别权重
因此,为了解决这个问题,我们需要给不同的类别不同的权重。
w
p
=
1
/
4
w_p = 1/4
wp=1/4
w
n
=
3
/
4
w_n = 3/4
wn=3/4
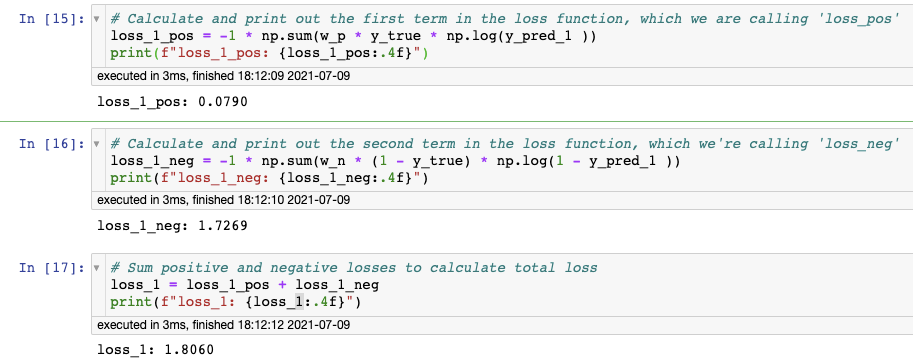

由图可见,两个model的loss一样,由于您使用了加权损失,因此无论模型始终预测 0.9 还是始终预测 0.1,计算出的损失都相同。
是不是很神奇。虽然加权损失很简单,初学者都听过。但是仔细去了解其中的原理,亲自实践,你会掌握的更牢靠。
思考:我们这里只计算了一个类别的loss, 当有多个类别时应该怎么计算呢?
感兴趣的朋友,自行查看代码,这里及不介绍了~~
欢迎继续阅读下一次内容~~
文章持续更新,可以关注微信公众号【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持已实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连
















 3827
3827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











