









概述:
ConcurrentHashMap结构分析:
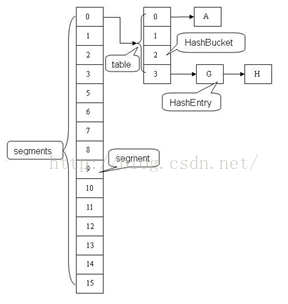
成员信息
final Segment<K,V>[] segments; transient volatile int count;//table内元素的数量
//修改次数
transient int modCount;
//临界值
transient int threshold;
//存放链表头结点的数组,相当于Hashtable中的哈希数组
transient volatile HashEntry<K,V>[] table;
//加载因子
final float loadFactor;static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
......
}构造函数:
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
//寻找小于2的n次方
segmentShift = 32 - sshift;
segmentMask = ssize - 1;
this.segments = Segment.newArray(ssize);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = 1;
while (cap < c)
cap <<= 1;
for (int i = 0; i < this.segments.length; ++i)
this.segments[i] = new Segment<K,V>(cap, loadFactor);
}Put方法
public V put(K key, V value) {
if (value == null)//说明不支持值为null的,但是支持键为null的,后面会说到原因
throw new NullPointerException();
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false);
} private static int hash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}重新计算key的hashcode的哈希值,这里在哈希的目的是减少哈希冲突,是使每个元素都能够均匀的分布在不同的段上,从而提高容器的存取效率。
segmentShift默认28,segmentMask默认15,将计算到的哈希值无符号右移28位,即让高四位进行运算。
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash(); //扩容
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value); //-------1-----------------
count = c; // write-volatile //-----------3--------------
}
return oldValue;
} finally {
unlock();
}
}Put方法一执行,首先就会先加锁,然后接着判断是否需要扩容,然后定位到待插入元素的链表头,接着循环判断是否存在key键相同的,若有存在的便将旧值保存起来,用新值覆盖旧值。如果没找到,将旧值置为null,创建一个新的节点,放到链表的头部。然后更新count的值。
get方法
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}V get(Object key, int hash) {
if (count != 0) { // read-volatile //--------------2------------------
HashEntry<K,V> e = getFirst(hash); //--------------4------------------
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}这里的思路也很简单:首先判断count是否为0,如果为0说明不存在,直接返回null。若存在则定位到链表头部位,遍历链表,如果找到键相同的,那么就返回对应的值,没找到返回null。
1、为什么判断count?
transient volatile int count;2、if (v != null)是什么意思?
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
remove方法:
public V remove(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
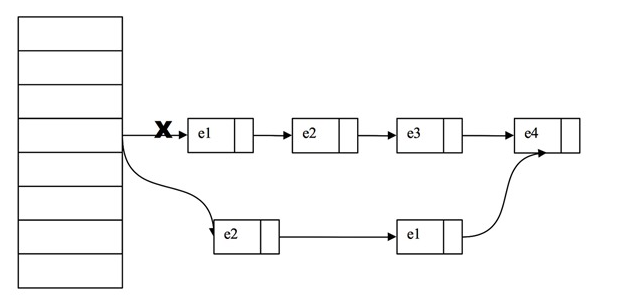
}我们定位到链表的头结点以后,遍历找寻key,如果没有对应的键,那么就返回null,如果发现了,我们要把待删节点之前的数据节点,逐个拷贝出来(因为前面说过,next是不可变的,所以只能在表头操作),从前往后拷贝,拷贝第1个节点,放到待删节点的前1个节点,依次类推,可能还有点模糊,我们看下面的图:
Size方法
public int size() {
final Segment<K,V>[] segments = this.segments;
long sum = 0;
long check = 0;
int[] mc = new int[segments.length];
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) {
check = 0;
sum = 0;
int mcsum = 0;
for (int i = 0; i < segments.length; ++i) {
sum += segments[i].count;
mcsum += mc[i] = segments[i].modCount;
}
if (mcsum != 0) {
for (int i = 0; i < segments.length; ++i) {
check += segments[i].count;
if (mc[i] != segments[i].modCount) {
check = -1; // force retry
break;
}
}
}
if (check == sum)
break;
}
if (check != sum) { // Resort to locking all segments
sum = 0;
for (int i = 0; i < segments.length; ++i)
segments[i].lock();
for (int i = 0; i < segments.length; ++i)
sum += segments[i].count;
for (int i = 0; i < segments.length; ++i)
segments[i].unlock();
}
if (sum > Integer.MAX_VALUE)
return Integer.MAX_VALUE;
else
return (int)sum;
}size方法首先不是锁定全段,首先进行遍历,对段上的数据进行遍历,期间用到了modCount,并且将每个段的修改次数都写进了一个新数组,然后累加所有的和,接下来在第二次遍历时,判断第一次得到的修改次数和第二次的是否一样,如果完全一样而且累加和都相等,说明在求取size的过程中没有其他任何线程对其进行修改;相反如果在求取size的过程中,另一个线程修改了数据,就会造成第一个遍历的和第二次遍历得到的修改次数不一样,那么此时会在这样判断一次,也就是整体的在循环一次,因为RETRIES_BEFORE_LOCK默认是2。完成后如果还不能无法避免其他线程在修改,那么此时锁定所有的段,,然后对其进行求取size,最后释放所有段的锁。
迭代器的那些事:
小结
ConcurrentHashMap是HashMap的线程安全升级版,是Hashtable的改进版。但是不能完全替代Hashtable,因为在某些必须保证一致性的前提下,我们会选择Hashtable。
ConcurrentHashMap的键可以为null,值却不能为null,这和以前我们见到的HashMap都不一样(HashMap是键值都可为null,Hashtable是键值都不可为null),那么究竟是为什么呢?我们刚才在上面的get代码快中发现,如果get的key存在,但是value却为null,则需要重新加锁后重读,所以值为null是有特殊用处的。
ConcurrentHashMap和Hashtable:Hashtable利用synchronized锁住整张表,当Hashtable的数量增大到一定程度时,迭代时就会锁住整张表,就造成了性能和效率的下降,而ConcurrentHashMap则使用分段锁,每次只用锁住一个段,不影响其他的段进行操作。
ConcurrentHashMap在读取的时候不用加锁,所以也造成了弱一致性。而Hashtable无论任何情况都会加锁,所以也成就了强一致性。














 1397
1397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









