







1. 在进行mapreduce编程时其Hadoop内置的数据类型不能满足需求时,或针对用例优化自定义 数据类型可能执行的更好.
因此可以通过实现org.apache.hadoop.io.Writable接口定义自定义的Writable类型,使其作为mapreduce计算的value类型。
2. 通过查看源码中org.apache.hadoop.io.Writable接口明确具体实现的实例。
public class MyWritable implements Writable {
// Some data
private int counter;
private long timestamp;
public void write(DataOutput out) throws IOException {
out.writeInt(counter);
out.writeLong(timestamp);
}
public void readFields(DataInput in) throws IOException {
counter = in.readInt();
timestamp = in.readLong();
}
public static MyWritable read(DataInput in) throws IOException {
MyWritable w = new MyWritable();
w.readFields(in);
return w;
}
}3.1 如果要添加一个自定义的构造函数用于自定义的Writable类一定要保持默认的空构造函数。
3.2 如果使用TextOutputFormat序列化自定义Writable类型的实例。要确保用于自定义的Writable数据类型有一个有意义的toString()实现。
3.3 在读取输入数据时,Hadoop课重复使用Writable类的一个实例。在readFileds()方法里面填充字段时,不应该依赖与该对象的现 有状态。
4. 下面通过一个具体的《自定义类型处理手机上网日志》实例来感受一下自定义的Writable类型。
4.1 数据文件名为:HTTP_20130313143750.dat(可从网上下载)。
4.2 数据样本:1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
4.3 数据结构类型:
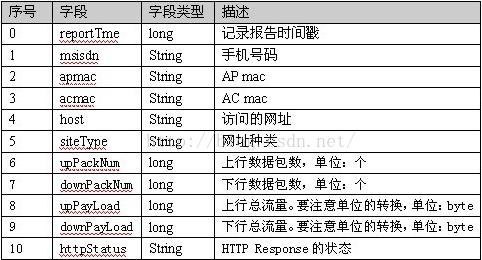
4.4 我们主要提取的是手机号、上行数据包、下行数据包、上行总流量、下行总流量。 (无论是发送请求还是返回请求都会产生数据包和流量)
5.Mapreduce程序的具体实现。
5.1自定义数据处理类型。
public class DataWritable implements Writable {
// upload
private int upPackNum;
private int upPayLoad;
// downLoad
private int downPackNum;
private int downPayLoad;
public DataWritable() {
}
public void set(int upPackNum, int upPayLoad, int downPackNum,
int downPayLoad) {
this.upPackNum = upPackNum;
this.upPayLoad = upPayLoad;
this.downPackNum = downPackNum;
this.downPayLoad = downPayLoad;
}
public int getUpPackNum() {
return upPackNum;
}
public int getUpPayLoad() {
return upPayLoad;
}
public int getDownPackNum() {
return downPackNum;
}
public int getDownPayLoad() {
return downPayLoad;
}
@Override
public void readFields(DataInput in) throws IOException {
this.upPackNum = in.readInt();
this.upPayLoad = in.readInt();
this.downPackNum = in.readInt();
this.downPayLoad = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(upPackNum);
out.writeInt(upPayLoad);
out.writeInt(downPackNum);
out.writeInt(downPayLoad);
}
@Override
public String toString() {
return upPackNum + "\t" + upPayLoad //
+ "\t" + downPackNum + //
"\t" + downPayLoad;
}
}static class DataTotalMapper extends
Mapper<LongWritable, Text, Text, DataWritable> {
private Text mapOutputKey = new Text();
private DataWritable dataWritable = new DataWritable();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String lineValue = value.toString();
// split
String[] strs = lineValue.split("\t");
// get data
String phoneNum = strs[1];
int upPackNum = Integer.valueOf(strs[6]);
int downPackNum = Integer.valueOf(strs[7]);
int upPayLoad = Integer.valueOf(strs[8]);
int downPayLoad = Integer.valueOf(strs[9]);
// set map output key / value
if (phoneNum.length() == 11)//确保处理的都是手机数据
mapOutputKey.set(phoneNum);
dataWritable.set(upPackNum, upPayLoad, downPackNum, downPayLoad);
context.write(mapOutputKey, dataWritable);
}
}static class DataTotalReducer extends
Reducer<Text, DataWritable, Text, DataWritable> {
private DataWritable dataWritable = new DataWritable();
public void reduce(Text key, Iterable<DataWritable> values,
Context context) throws IOException, InterruptedException {
int upPackNum = 0;
int downPackNum = 0;
int upPayLoad = 0;
int downPayLoad = 0;
for (DataWritable data : values) {
upPackNum += data.getUpPackNum();
downPackNum += data.getDownPackNum();
upPayLoad += data.getUpPayLoad();
downPayLoad += data.getDownPayLoad();
}
dataWritable.set(upPackNum, upPayLoad, downPackNum, downPayLoad);
context.write(key, dataWritable);
}
}public class DataTotalPhone {
static final String INPUT_PATH = "hdfs://192.168.56.171:9000/DataPhone/HTTP_20130313143750.dat";
static final String OUT_PATH = "hdfs://192.168.56.171:9000/DataPhone/out";
public static void main(String[] args) throws ClassNotFoundException,
IOException, InterruptedException {
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
final Path outPath = new Path(OUT_PATH);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
}
// create job
Job job = new Job(conf, DataTotalPhone.class.getSimpleName());
// set job
job.setJarByClass(DataTotalMapper.class);
// 1)input
Path inputDir = new Path(args[0]);
FileInputFormat.addInputPath(job, inputDir);
// 2)map
job.setMapperClass(DataTotalMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DataWritable.class);
// 3)reduce
job.setReducerClass(DataTotalReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DataWritable.class);
// 4)output
Path outputDir = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outputDir);
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0 : 1;
}
}














 5859
5859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









