







想看能不能完整梳理一下收消息过程。从 NIC 收数据开始,到触发软中断,交付数据包到 IP 层再经由路由机制到 TCP 层,最终交付用户进程。会尽力介绍收消息过程中的各种配置信息,以及各种监控数据。知道了收消息的完整过程,了解了各种配置,明白了各种监控数据后才有可能在今后的工作中做优化配置。
所有参考内容会列在这个系列最后一篇文章中。
Ring Buffer 相关的收消息过程大致如下:
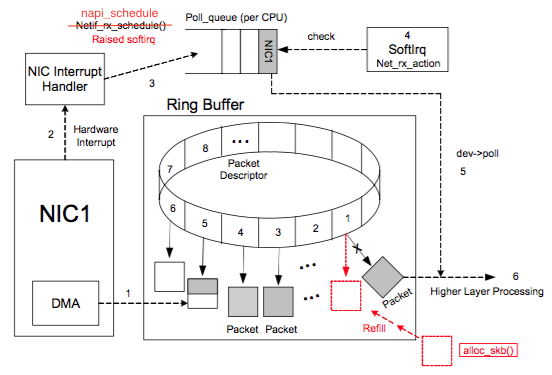 图片来自参考1,对 raise softirq 的函数名做了修改,改为了 napi_schedule
图片来自参考1,对 raise softirq 的函数名做了修改,改为了 napi_schedule
NIC (network interface card) 在系统启动过程中会向系统注册自己的各种信息,系统会分配 Ring Buffer 队列也会分配一块专门的内核内存区域给 NIC 用于存放传输上来的数据包。struct sk_buff 是专门存放各种网络传输数据包的内存接口,在收到数据存放到 NIC 专用内核内存区域后,sk_buff 内有个 data 指针会指向这块内存。Ring Buffer 队列内存放的是一个个 Packet Descriptor ,其有两种状态: ready 和 used 。初始时 Descriptor 是空的,指向一个空的 sk_buff,处在 ready 状态。当有数据时,DMA 负责从 NIC 取数据,并在 Ring Buffer 上按顺序找到下一个 ready 的 Descriptor,将数据存入该 Descriptor 指向的 sk_buff 中,并标记槽为 used。因为是按顺序找 ready 的槽,所以 Ring Buffer 是个 FIFO 的队列。
当 DMA 读完数据之后,NIC 会触发一个 IRQ 让 CPU 去处理收到的数据。因为每次触发 IRQ 后 CPU 都要花费时间去处理 Interrupt Handler,如果 NIC 每收到一个 Packet 都触发一个 IRQ 会导致 CPU 花费大量的时间在处理 Interrupt Handler,处理完后又只能从 Ring Buffer 中拿出一个 Packet,虽然 Interrupt Handler 执行时间很短,但这么做也非常低效,并会给 CPU 带去很多负担。所以目前都是采用一个叫做 New API(NAPI) 的机制,去对 IRQ 做合并以减少 IRQ 次数。
接下来介绍一下 NAPI 是怎么做到 IRQ 合并的。它主要是让 NIC 的 driver 能注册一个 poll 函数,之后 NAPI 的 subsystem 能通过 poll 函数去从 Ring Buffer 中批量拉取收到的数据。主要事件及其顺序如下:
- NIC driver 初始化时向 Kernel 注册
poll函数,用于后续从 Ring Buffer 拉取收到的数据 - driver 注册开启 NAPI,这个机制默认是关闭的,只有支持 NAPI 的 driver 才会去开启
- 收到数据后 NIC 通过 DMA 将数据存到内存
- NIC 触发一个 IRQ,并触发 CPU 开始执行 driver 注册的 Interrupt Handler
- driver 的 Interrupt Handler 通过 napi_schedule 函数触发 softirq (NET_RX_SOFTIRQ) 来唤醒 NAPI subsystem,NET_RX_SOFTIRQ 的 handler 是 net_rx_action 会在另一个线程中被执行,在其中会调用 driver 注册的
poll函数获取收到的 Packet - driver 会禁用当前 NIC 的 IRQ,从而能在
poll完所有数据之前不会再有新的 IRQ - 当所有事情做完之后,NAPI subsystem 会被禁用,并且会重新启用 NIC 的 IRQ
- 回到第三步
从上面的描述可以看出来还缺一些东西,Ring Buffer 上的数据被 poll 走之后是怎么交付上层网络栈继续处理的呢?以及被消耗掉的 sk_buff 是怎么被重新分配重新放入 Ring Buffer 的呢?
这两个工作都在 poll 中完成,上面说过 poll 是个 driver 实现的函数,所以每个 driver 实现可能都不相同。但 poll 的工作基本是一致的就是:
- 从 Ring Buffer 中将收到的 sk_buff 读取出来
- 对 sk_buff 做一些基本检查,可能会涉及到将几个 sk_buff 合并因为可能同一个 Frame 被分散放在多个 sk_buff 中
- 将 sk_buff 交付上层网络栈处理
- 清理 sk_buff,清理 Ring Buffer 上的 Descriptor 将其指向新分配的 sk_buff 并将状态设置为 ready
- 更新一些统计数据,比如收到了多少 packet,一共多少字节等
如果拿 intel igb 这个网卡的实现来看,其 poll 函数在这里:linux/drivers/net/ethernet/intel/igb/igb_main.c - Elixir - Free Electrons
首先是看到有 tx.ring 和 rx.ring,说明收发消息都会走到这里。发消息先不管,先看收消息,收消息走的是 igb_clean_rx_irq。收完消息后执行 napi_complete_done 退出 polling 模式,并开启 NIC 的 IRQ。从而我们知道大部分工作是在 igb_clean_rx_irq 中完成的,其实现大致上还是比较清晰的,就是上面描述的几步。里面有个 while 循环通过 buget 控制,从而在 Packet 特别多的时候不要让 CPU 在这里无穷循环下去,要让别的事情也能够被执行。循环内做的事情如下:
- 先批量清理已经读出来的 sk_buff 并分配新的 buffer 从而避免每次读一个 sk_buff 就清理一个,很低效
- 找到 Ring Buffer 上下一个需要被读取的 Descriptor ,并检查描述符状态是否正常
- 根据 Descriptor 找到 sk_buff 读出来
- 检查是否是 End of packet,是的话说明 sk_buff 内有 Frame 的全部内容,不是的话说明 Frame 数据比 sk_buff 大,需要再读一个 sk_buff,将两个 sk_buff 数据合并起来
- 通过 Frame 的 Header 检查 Frame 数据完整性,是否正确之类的
- 记录 sk_buff 的长度,读了多少数据
- 设置 Hash、checksum、timestamp、VLAN id 等信息,这些信息是硬件提供的。
- 通过 napi_gro_receive 将 sk_buff 交付上层网络栈
- 更新一堆统计数据
- 回到 1,如果没数据或者 budget 不够就退出循环
看到 budget 会影响到 CPU 执行 poll 的时间,budget 越大当数据包特别多的时候可以提高 CPU 利用率并减少数据包的延迟。但是 CPU 时间都花在这里会影响别的任务的执行。
| budget 默认 300,可以调整 sysctl -w net.core.netdev_budget=600 |
napi_gro_receive会涉及到 GRO 机制,稍后再说,大致上就是会对多个数据包做聚合,napi_gro_receive 最终是将处理好的 sk_buff 通过调用 netif_receive_skb,将数据包送至上层网络栈。执行完 GRO 之后,基本可以认为数据包正式离开 Ring Buffer,进入下一个阶段了。在记录下一阶段的处理之前,补充一下收消息阶段 Ring Buffer 相关的更多细节。
Generic Receive Offloading(GRO)
GRO 是 Large receive offload 的一个实现。网络上大部分 MTU 都是 1500 字节,开启 Jumbo Frame 后能到 9000 字节,如果发送的数据超过 MTU 就需要切割成多个数据包。LRO 就是在收到多个数据包的时候将同一个 Flow 的多个数据包按照一定的规则合并起来交给上层处理,这样就能减少上层需要处理的数据包数量。
很多 LRO 机制是在 NIC 上实现的,没有实现 LRO 的 NIC 就少了上述合并数据包的能力。而 GRO 是 LRO 在软件上的实现,从而能让所有 NIC 都支持这个功能。
napi_gro_receive 就是在收到数据包的时候合并多个数据包用的,如果收到的数据包需要被合并,napi_gro_receive 会很快返回。当合并完成后会调用 napi_skb_finish ,将因为数据包合并而不再用到的数据结构释放。最终会调用到 netif_receive_skb 将数据包交到上层网络栈继续处理。netif_receive_skb 上面说过,就是数据包从 Ring Buffer 出来后到上层网络栈的入口。
可以通过 ethtool 查看和设置 GRO:
| 查看 GRO ethtool -k eth0 | grep generic-receive-offload generic-receive-offload: on 设置开启 GRO ethtool -K eth0 gro on |
多 CPU 下的 Ring Buffer 处理 (Receive Side Scaling)
NIC 收到数据的时候产生的 IRQ 只可能被一个 CPU 处理,从而只有一个 CPU 会执行 napi_schedule 来触发 softirq,触发的这个 softirq 的 handler 也还是会在这个产生 softIRQ 的 CPU 上执行。所以 driver 的 poll 函数也是在最开始处理 NIC 发出 IRQ 的那个 CPU 上执行。于是一个 Ring Buffer 上同一个时刻只有一个 CPU 在拉取数据。
从上面描述能看出来分配给 Ring Buffer 的空间是有限的,当收到的数据包速率大于单个 CPU 处理速度的时候 Ring Buffer 可能被占满,占满之后再来的新数据包会被自动丢弃。而现在机器都是有多个 CPU,同时只有一个 CPU 去处理 Ring Buffer 数据会很低效,这个时候就产生了叫做 Receive Side Scaling(RSS) 或者叫做 multiqueue 的机制来处理这个问题。WIKI 对 RSS 的介绍挺好的,简洁干练可以看看: Network interface controller - Wikipedia
简单说就是现在支持 RSS 的网卡内部会有多个 Ring Buffer,NIC 收到 Frame 的时候能通过 Hash Function 来决定 Frame 该放在哪个 Ring Buffer 上,触发的 IRQ 也可以通过操作系统或者手动配置 IRQ affinity 将 IRQ 分配到多个 CPU 上。这样 IRQ 能被不同的 CPU 处理,从而做到 Ring Buffer 上的数据也能被不同的 CPU 处理,从而提高数据的并行处理能力。
RSS 除了会影响到 NIC 将 IRQ 发到哪个 CPU 之外,不会影响别的逻辑了。收消息过程跟之前描述的是一样的。
如果支持 RSS 的话,NIC 会为每个队列分配一个 IRQ,通过 /proc/interrupts 能进行查看。你可以通过配置 IRQ affinity 指定 IRQ 由哪个 CPU 来处理中断。先通过 /proc/interrupts 找到 IRQ 号之后,将希望绑定的 CPU 号写入 /proc/irq/IRQ_NUMBER/smp_affinity,写入的是 16 进制的 bit mask。比如看到队列 rx_0 对应的中断号是 41 那就执行:
| echo 6 > /proc/irq/41/smp_affinity 6 表示的是 CPU2 和 CPU1 |
0 号 CPU 的掩码是 0x1 (0001),1 号 CPU 掩码是 0x2 (0010),2 号 CPU 掩码是 0x4 (0100),3 号 CPU 掩码是 0x8 (1000) 依此类推。
另外需要注意的是设置 smp_affinity 的话不能开启 irqbalance 或者需要为 irqbalance 设置 –banirq 列表,将设置了 smp_affinity 的 IRQ 排除。不然 irqbalance 机制运作时会忽略你设置的 IRQ affinity 配置。
Receive Packet Steering(RPS) 是在 NIC 不支持 RSS 时候在软件中实现 RSS 类似功能的机制。其好处就是对 NIC 没有要求,任何 NIC 都能支持 RPS,但缺点是 NIC 收到数据后 DMA 将数据存入的还是一个 Ring Buffer,NIC 触发 IRQ 还是发到一个 CPU,还是由这一个 CPU 调用 driver 的 poll 来将 Ring Buffer 的数据取出来。RPS 是在单个 CPU 将数据从 Ring Buffer 取出来之后才开始起作用,它会为每个 Packet 计算 Hash 之后将 Packet 发到对应 CPU 的 backlog 中,并通过 Inter-processor Interrupt(IPI) 告知目标 CPU 来处理 backlog。后续 Packet 的处理流程就由这个目标 CPU 来完成。从而实现将负载分到多个 CPU 的目的。
RPS 默认是关闭的,当机器有多个 CPU 并且通过 softirqs 的统计 /proc/softirqs 发现 NET_RX 在 CPU 上分布不均匀或者发现网卡不支持 mutiqueue 时,就可以考虑开启 RPS。开启 RPS 需要调整 /sys/class/net/DEVICE_NAME/queues/QUEUE/rps_cpus 的值。比如执行:
| echo f > /sys/class/net/eth0/queues/rx-0/rps_cpus |
表示的含义是处理网卡 eth0 的 rx-0 队列的 CPU 数设置为 f 。即设置有 15 个 CPU 来处理 rx-0 这个队列的数据,如果你的 CPU 数没有这么多就会默认使用所有 CPU 。甚至有人为了方便都是直接将 echo fff > /sys/class/net/eth0/queues/rx-0/rps_cpus 写到脚本里,这样基本能覆盖所有类型的机器,不管机器 CPU 数有多少,都能覆盖到。从而就能让这个脚本在任意机器都能执行。
注意:如果 NIC 不支持 mutiqueue,RPS 不是完全不用思考就能打开的,因为其开启之后会加重所有 CPU 的负担,在一些场景下比如 CPU 密集型应用上并不一定能带来好处。所以得测试一下。
Receive Flow Steering(RFS) 一般和 RPS 配合一起工作。RPS 是将收到的 packet 发配到不同的 CPU 以实现负载均衡,但是可能同一个 Flow 的数据包正在被 CPU1 处理,但下一个数据包被发到 CPU2,会降低 CPU cache hit 比率并且会让数据包要从 CPU1 发到 CPU2 上。RFS 就是保证同一个 flow 的 packet 都会被路由到正在处理当前 Flow 数据的 CPU,从而提高 CPU cache 比率。这篇文章 把 RFS 机制介绍的挺好的。基本上就是收到数据后根据数据的一些信息做个 Hash 在这个 table 的 entry 中找到当前正在处理这个 flow 的 CPU 信息,从而将数据发给这个正在处理该 Flow 数据的 CPU 上,从而做到提高 CPU cache hit 率,避免数据在不同 CPU 之间拷贝。当然还有很多细节,请看上面链接。
RFS 默认是关闭的,必须主动配置才能生效。正常来说开启了 RPS 都要再开启 RFS,以获取更好的性能。这篇文章也有说该怎么去开启 RFS 以及推荐的配置值。一个是要配置 rps_sock_flow_entries
| sysctl -w net.core.rps_sock_flow_entries=32768 |
这个值依赖于系统期望的活跃连接数,注意是同一时间活跃的连接数,这个连接数正常来说会大大小于系统能承载的最大连接数,因为大部分连接不会同时活跃。该值建议是 32768,能覆盖大多数情况,每个活跃连接会分配一个 entry。除了这个之外还要配置 rps_flow_cnt,这个值是每个队列负责的 flow 最大数量,如果只有一个队列,则 rps_flow_cnt 一般是跟 rps_sock_flow_entries 的值一致,但是有多个队列的时候 rps_flow_cnt 值就是 rps_sock_flow_entries / N, N 是队列数量。
| echo 2048 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt |
Accelerated Receive Flow Steering (aRFS) 类似 RFS 只是由硬件协助完成这个工作。aRFS 对于 RFS 就和 RSS 对于 RPS 一样,就是把 CPU 的工作挪到了硬件来做,从而不用浪费 CPU 时间,直接由 NIC 完成 Hash 值计算并将数据发到目标 CPU,所以快一点。NIC 必须暴露出来一个 ndo_rx_flow_steer 的函数用来实现 aRFS。
adaptive RX/TX IRQ coalescing
有的 NIC 支持这个功能,用来动态的将 IRQ 进行合并,以做到在数据包少的时候减少数据包的延迟,在数据包多的时候提高吞吐量。查看方法:
| ethtool -c eth1 Coalesce parameters for eth1: Adaptive RX: off TX: off stats-block-usecs: 0 ..... |
开启 RX 队列的 adaptive coalescing 执行:
| ethtool -C eth0 adaptive-rx on |
并且有四个值需要设置:rx-usecs、rx-frames、rx-usecs-irq、rx-frames-irq,具体含义等需要用到的时候查吧。
Ring Buffer 相关监控及配置
收到数据包统计
| ethtool -S eh0 NIC statistics: rx_packets: 792819304215 tx_packets: 778772164692 rx_bytes: 172322607593396 tx_bytes: 201132602650411 rx_broadcast: 15118616 tx_broadcast: 2755615 rx_multicast: 0 tx_multicast: 10 |
RX 就是收到数据,TX 是发出数据。还会展示 NIC 每个队列收发消息情况。其中比较关键的是带有 drop 字样的统计和 fifo_errors 的统计 :
| tx_dropped: 0 rx_queue_0_drops: 93 rx_queue_1_drops: 874 .... rx_fifo_errors: 2142 tx_fifo_errors: 0 |
看到发送队列和接收队列 drop 的数据包数量显示在这里。并且所有 queue_drops 加起来等于 rx_fifo_errors。所以总体上能通过 rx_fifo_errors 看到 Ring Buffer 上是否有丢包。如果有的话一方面是看是否需要调整一下每个队列数据的分配,或者是否要加大 Ring Buffer 的大小。
/proc/net/dev是另一个数据包相关统计,不过这个统计比较难看:
| cat /proc/net/dev Inter-| Receive | Transmit face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed lo: 14472296365706 10519818839 0 0 0 0 0 0 14472296365706 10519818839 0 0 0 0 0 0 eth1: 164650683906345 785024598362 0 0 2142 0 0 0 183711288087530 704887351967 0 0 0 0 0 0 |
调整 Ring Buffer 队列数量
| ethtool -l eth0 Channel parameters for eth0: Pre-set maximums: RX: 0 TX: 0 Other: 1 Combined: 8 Current hardware settings: RX: 0 TX: 0 Other: 1 Combined: 8 |
看的是 Combined 这一栏是队列数量。Combined 按说明写的是多功能队列,猜想是能用作 RX 队列也能当做 TX 队列,但数量一共是 8 个?
如果不支持 mutiqueue 的话上面执行下来会是:
| Channel parameters for eth0: Cannot get device channel parameters : Operation not supported |
看到上面 Ring Buffer 数量有 maximums 和 current settings,所以能自己设置 Ring Buffer 数量,但最大不能超过 maximus 值:
| sudo ethtool -L eth0 combined 8 |
如果支持对特定类型 RX 或 TX 设置队列数量的话可以执行:
| sudo ethtool -L eth0 rx 8 |
需要注意的是,ethtool 的设置操作可能都要重启一下才能生效。
调整 Ring Buffer 队列大小
先查看当前 Ring Buffer 大小:
| ethtool -g eth0 Ring parameters for eth0: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096 Current hardware settings: RX: 512 RX Mini: 0 RX Jumbo: 0 TX: 512 |
看到 RX 和 TX 最大是 4096,当前值为 512。队列越大丢包的可能越小,但数据延迟会增加
设置 RX 队列大小:
| ethtool -G eth0 rx 4096 |
调整 Ring Buffer 队列的权重
NIC 如果支持 mutiqueue 的话 NIC 会根据一个 Hash 函数对收到的数据包进行分发。能调整不同队列的权重,用于分配数据。
| ethtool -x eth0 RX flow hash indirection table for eth0 with 8 RX ring(s): 0: 0 0 0 0 0 0 0 0 8: 0 0 0 0 0 0 0 0 16: 1 1 1 1 1 1 1 1 ...... 64: 4 4 4 4 4 4 4 4 72: 4 4 4 4 4 4 4 4 80: 5 5 5 5 5 5 5 5 ...... 120: 7 7 7 7 7 7 7 7 |
我的 NIC 一共有 8 个队列,一个有 128 个不同的 Hash 值,上面就是列出了每个 Hash 值对应的队列是什么。最左侧 0 8 16 是为了能让你快速的找到某个具体的 Hash 值。比如 Hash 值是 76 的话我们能立即找到 72 那一行:”72: 4 4 4 4 4 4 4 4”,从左到右第一个是 72 数第 5 个就是 76 这个 Hash 值对应的队列是 4 。
| ethtool -X eth0 weight 6 2 8 5 10 7 1 5 |
设置 8 个队列的权重。加起来不能超过 128 。128 是 indirection table 大小,每个 NIC 可能不一样。
更改 Ring Buffer Hash Field
分配数据包的时候是按照数据包内的某个字段来进行的,这个字段能进行调整。
| ethtool -n eth0 rx-flow-hash tcp4 TCP over IPV4 flows use these fields for computing Hash flow key: IP SA IP DA L4 bytes 0 & 1 [TCP/UDP src port] L4 bytes 2 & 3 [TCP/UDP dst port] |
查看 tcp4 的 Hash 字段。
也可以设置 Hash 字段:
| ethtool -N eth0 rx-flow-hash udp4 sdfn |
sdfn 需要查看 ethtool 看其含义,还有很多别的配置值。
softirq 数统计
通过 /proc/softirqs 能看到每个 CPU 上 softirq 数量统计:
| cat /proc/softirqs CPU0 CPU1 HI: 1 0 TIMER: 1650579324 3521734270 NET_TX: 10282064 10655064 NET_RX: 3618725935 2446 BLOCK: 0 0 BLOCK_IOPOLL: 0 0 TASKLET: 47013 41496 SCHED: 1706483540 1003457088 HRTIMER: 1698047 11604871 RCU: 4218377992 3049934909 |
看到 NET_RX 就是收消息时候触发的 softirq,一般看这个统计是为了看看 softirq 在每个 CPU 上分布是否均匀,不均匀的话可能就需要做一些调整。比如上面看到 CPU0 和 CPU1 两个差距很大,原因是这个机器的 NIC 不支持 RSS,没有多个 Ring Buffer。开启 RPS 后就均匀多了。
IRQ 统计
/proc/interrupts 能看到每个 CPU 的 IRQ 统计。一般就是看看 NIC 有没有支持 multiqueue 以及 NAPI 的 IRQ 合并机制是否生效。看看 IRQ 是不是增长的很快。
















 1678
1678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









