









日常一提数据分析和可视化,就想到这个工具操作要多简单易用,图表要多美多炫,然而总是忽略背后的数据支撑。
excel 几十万行数据就卡死崩,谈何数据透视表、可视化?
近千万行的数据,订单提交数据库,sql sever处理要5分多钟,如果频繁入库/取数的话.....
要知道,为了支撑起业务人员的数据分析,以及日常不考虑计算逻辑和技术难度,IT人员也是要花费很大的心血和精力啊(心疼运维人员n秒)。
随着公司业务的发展,数据量变大是必然的事实。那么,数据部门要做分析,业务部门要看报表,要跑数据,要用BI,大数据量(千万级及以上)的分析,性能该如何优化?
这里借某公司的真实案例,来阐述一下方案。
----------------------------------
作为公司的科技部门人员,经常听到业务部门对自己使用的数据库各种吐槽:
竟然存放在mongoDB中啊,震惊(ΩДΩ)。
数据库慢慢熟悉了还好啊,但是现在每天的数据量越来越大,而且还在增加啊,增加大家很开心,然而数据库并不开心啊,简单的查询统计10多分钟还出不来结果,更不用说有稍微复杂点的统计分析了。
我天天找DBA优化啊,然而并没有什么水花。
数据量还在不断增长,到现在都上亿啦,全量查询统计根本出不来结果啊。
... ...
最终业务人员找到科技部门提需求要弄个BI系统给处理下。
对mongodb瞄了一大通,这就是个业务库。那直接对接mongodb自然不行,速度慢不说,mongodb挂了,分析系统也瘫了。自然就想到了使用中间库,emm mysql oracle 倒是有,可以跑调度抽过来,但是速度依旧不快呢,还要花功夫优化,性价比不高。公司有自己的hadoop平台,将数据抽过来再对接倒是可以,但是要花很大精力跑调度,而且这个数据库不能随意给这个业务部门提供,万一玩挂了可就得不偿失。假设有个具备离线数据存储功能的BI工具,岂不美哉。
于是将市面上有离线数据存储功能的BI工具翻了个遍。期望找到个性能好,可以支持大数据量数据分析的BI工具。
Tableau的hyper功能看起来OK,经不起实际使用,数据量过了亿,等了好久数据抽不好,pass;
其他某BI工具有mpp离线存储,看起来很棒,还能横向扩展,不错。抱有最大期望的用,结果数据量一上亿,直接崩了,崩了,pass;
另一个BI工具去看了看,咦,数据是放在vertica里面的......
后来,找到了FineBI的分布式计算引擎方案,拿的『定制的 Alluxio』作为分布式内存存储框架,内存存储有数据安全性的担心,所以持久化层存储用了HDFS。为了数据分析嘛,自然是列式存储的。计算核心则以熟知的Spark,加上自研算法来处理的。使用熟知的zookeeper整合框架,并用于调度通信。
分布式嘛,横向扩展自然不在话下。而列式存储、并行内存计算、计算本地化加上高性能算法,在FineBI中数据展示速度超快。有意思的是其计算本地化的操作,能减少不必要的shuffle,节省数据传输的消耗,提升数据计算速度。
以下记录利用FineBI4.1工具的系统建设过程。
一、需求分析
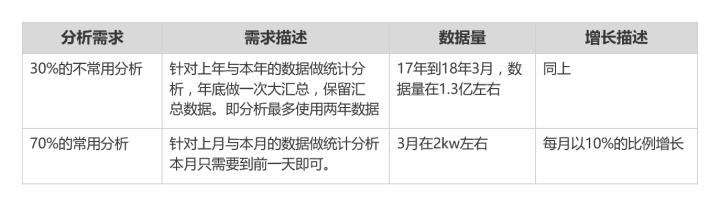
针对以上的需求,可以预估到,18年内,常用分析预计最大数据量会达到4.7kw,不常用分析会达到3亿到4亿(包含淡季),数据总的体量最多会达到100G。后面的情况难以预估,就需要系统可横向扩展节点。
二、方案描述
1.系统架构
根据官方推荐,将FineBI的web应用端与数据存储的分布式引擎放在一个机器上(处于安全考虑,也可以分开。这里不涉及太多部门使用,放一起即可),架构如下所示。
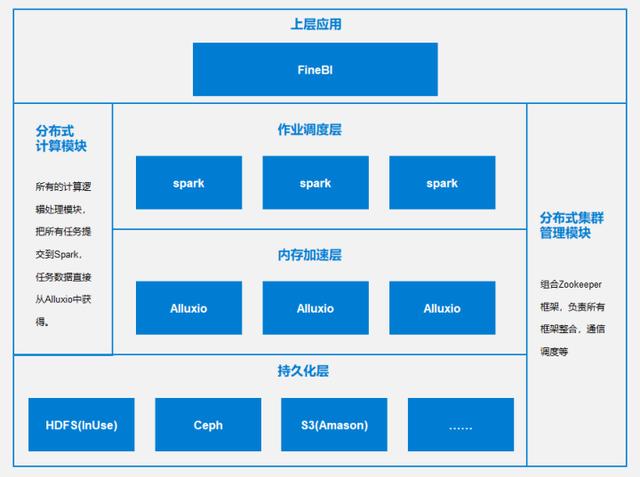
架构图难以理解的话,可以看看灵魂画手的杰作~
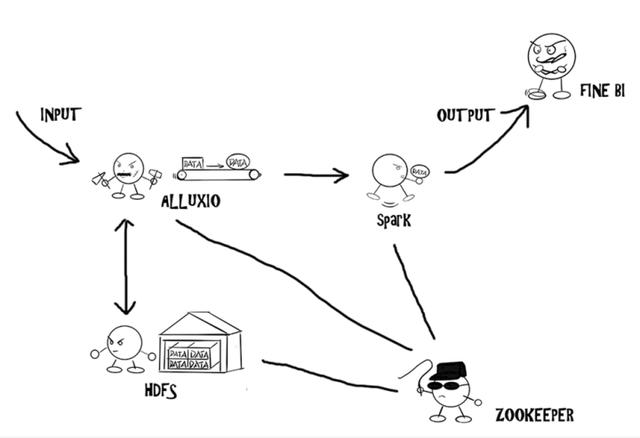
结合分布式引擎说明的技术原理,将各个机器再细分化各个组件的作用。
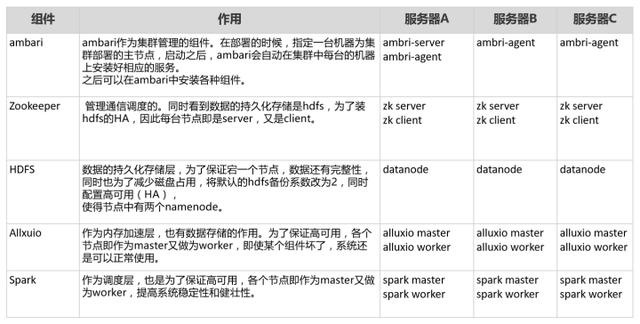
以上,将系统架构规划完成,即可具体完成系统。
2.完成从MongoDB取数
在使用BI工具对接MongoDB的时候,使用MongoDB的BI连接器。
感兴趣可以看:MongoDB Download Center
方案原理:mongodb是非结构的数据库,而要想BI来连接,通过建模的方式取表,拆表,建模来分析。通过MONGODB CONNECTOR FOR BI连接器的方式,使用mysql的JDBC驱动来获取数据。
实现过程:
第一步:安装MONGODB CONNECTOR FOR BI
从官网选择版本:MongoDB Download Center
第二步:生成DRDL文件
mongodrdl是生成该文件的主命令。通过添加monogdb的相关参数来获取其中的表生成drdl文件。从官方文档上我们可以找到生成DRDL文件命令的范式:
mongodrdl是生成该文件的主命令。通过添加monogdb的相关参数来获取其中的表生成drdl文件。从官方文档上我们可以找到生成DRDL文件命令的范式:
1 mongodrdl --host myhost.example.net:27017
2 --username dbUser
3 --password myPassword
4 --db reports
5 --authenticationDatabase admin
6 --out schema.drdl 范式说明:
- --host 是mongodb的ip+端口号,通常可为127.0.0.1:27017
- --username 是mongodb的用户,需具备相关的数据权限
- --password 是username的密码
- --db 是要生成DRDL的数据库实例名
- --authenticationDatabase 是指定创建用户的数据库。即username创建时被指定到的数据库名。
- --out 是DRDL输出文件定义。值使用.drdl的文件即可。
第三步:启动连接器,连接上monogdb
启动连接器的主命令服务是mongosqld,由于mongodb开启用户认证了(auth=true)。从官方文档上可知,连接器的启动需要使用-auth参数,再使用auth参数的情况下,mysql驱动来取数就需要SSLl加密认证。
所以第一步需要配置mongosqld的SSL认证;才能启动连接器来取数!!!!!!!!!!这一步神坑,也是踩了多少坑,才找到的解决办法。
此处认证关系是FineBi端的mysql连接与mongosqld的连接之间的SSL认证。在认证时,只需要配置单向SSL的认证即可(mongosqld认证FineBI的连接)。
(1)生成SSL认证文件
SSL认证文件通常采用openSSL来生成,先看看是否安装了openSSL;执行命令:
rpm -qa|grep -i openssl
如安装了会返回信息,未安装需要自行安装OpenSSL。
采用以下命令来生成证书:(由于是测试,就直接自己生成证书,密钥)
openssl req -newkey rsa:2048 -new -x509 -days 365 -nodes -out mongodb-cert.crt -keyout mongodb-cert.key命令返回会让填写一些值,在后面填写即可。
一般情况下,文件会生成到你所使用的linux用户的要根目录下:比如我用的root用户,就到/root下面查找。
再使用以下命令,将key合到.pem的文件里。
cat mongodb-cert.key mongodb-cert.crt > mongodb.pem将该文件移动/etc/ssl下面用于验证使用:
mv mongodb.pem /etc/ssl(2)启动连接器&SSL
再来看官方文档,从所有的参数命令里面,找一找需要的参数;得出以下的范式,在bin目录下启动即可。
mongosqld --auth
--sslMode
--sslPEMKeyFile
--sslAllowInvalidCertificates
--defaultAuthSource
--mongo-uri
--mongo-username
--mongo-password
--mongo-authenticationSource
--schema说明:
- --auth 是开启用户认证的参数,默认值是true
- --sslMode是开启SSL的标识,如开启可以选择值为“requireSSL”
- --sslPEMKeyFile是SSL认证文件,一般为.pem结尾的文件;单向认证的时候。
- --sslAllowInvalidCertificates
- --defaultAuthSource是mongosqld使用username指向mongodb的有权限的库,默认值是admin
- --mongo-uri是mongodb的host,一般为ip+端口号
- --mongo-usrname是drdl生成的用户名
- --mongo-password是drdl生成的密码
- --mongo-authenticationSource指定用户的创建库
- --schema是要连接的drdl文件。
注:一般还是要用nohup 的命令来生成,保证shell断掉,连接器依然可用。
第四步:启动FineBI连接到连接器上
启动FineBI,打开FineBI>数据配置>数据连接:添加数据连接选择mysql,配置如下:
连接名:mongodb
URL:jdbc:mysql://127.0.0.1:3307/test?ssl-key=/etc/ssl/mongodb.pem
用户名:
密码:
注:URL:jdbc:mysql://ip+3307/dbname?ssl-key=xx.pem,后面ssl-key是ssl参数点击测试连接即可。
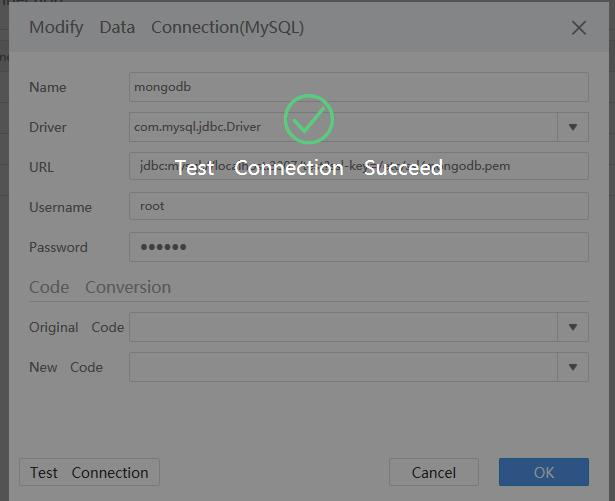
过程坑点:mongodb的BI连接器神坑,官网文档不多,踩过了几脚坑。
(1)mongosqld按ssl认证开启成功,打印也不错,但是BI连接的时候,还是抛错1043 SQLSTATE: 08S01 (ER_HANDSHAKE_ERROR):this server only allows SSL xxxxx该抛错是mysql抛出来的,握手不良的错误。按道理SSL已经开启了,不应该是这样。后来查了mysql的文档,mysql5.5以上的版本才支持SSL;更换新的driver驱动,使用的是5.1.44完全没问题的。
(2)BI连接的时候抛错 handshake error: ERROR 1043 (08S01): error performing authentication: unable to authenticate conversation 0: unable to authenticate using mechanism "SCRAM-SHA-1": (AuthenticationFailed) Authentication failed.
该抛错的意思,使用“SCRAM-SHA-1”的认证方式,没有认证成功。SCRAM-SHA-1是指用户名密码的方式,这里看是不是用户名/密码错误,注意mongosqld启动时的使用的用户名/密码
(3)一定要开启SSL认证啊!!!
(4)期间有设计器无故死掉的情况,发现是由于内存不足导致。记得空闲内存要足够!!
三.系统效果
1.数据更新
(1) 单个表先全量抽取,之后每天对单表依据时间戳,做增量增加。其中有错误数据做增量删除即可。
(2)有些内部使用的实时性较高的表,设定每2小时更新一次,从上午9点到下午6点。直接从业务库抽取其实是有风险的,当时数据库压力大,抽取比较慢,因此这部分仅作为非重点用户需求场景。
2.数据展示速度
做了一个简单的依据时间的group by,时间在1s之内,翻页速度也很快。
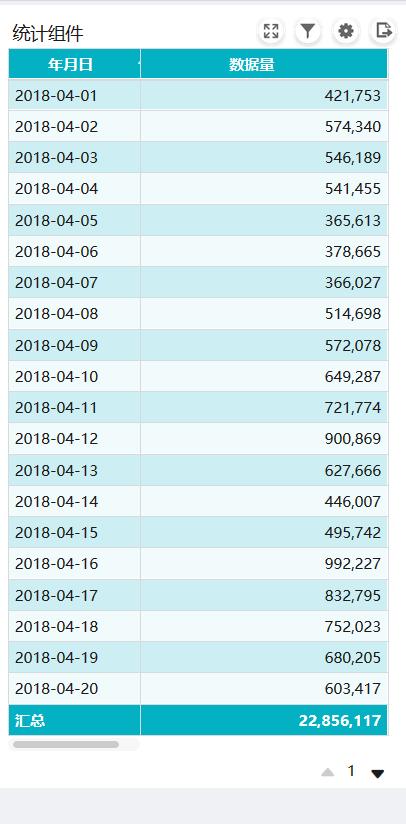
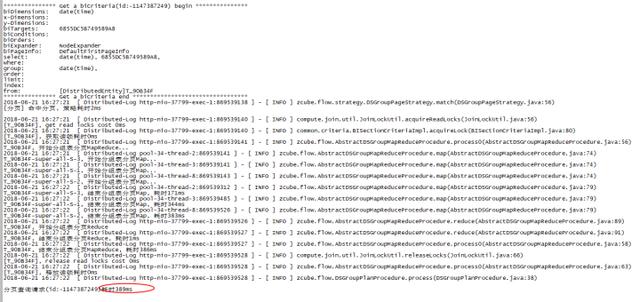
至此,对接mongodb完成,一个用户可以随便玩的系统就好了。即使偶尔mongodb发疯修整,有离线数据在,也不担心业务部门来嚷嚷了。而且速度超快,体验很棒~
最后
如果你也在寻求一个高性能展示分析、数据分析的BI工具的话,不妨尝试下FineBI。















 1137
1137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









