 Spark调度模式详解
Spark调度模式详解





 本文深入解析了Spark中的两种调度模式:FIFO和FAIR。详细介绍了它们的工作原理、配置方式及如何影响任务执行顺序。通过源码分析,揭示了不同模式下的调度逻辑,帮助读者理解如何优化Spark作业。
本文深入解析了Spark中的两种调度模式:FIFO和FAIR。详细介绍了它们的工作原理、配置方式及如何影响任务执行顺序。通过源码分析,揭示了不同模式下的调度逻辑,帮助读者理解如何优化Spark作业。
Spark 调度模式-FIFO和FAIR
Spark中的调度模式主要有两种:FIFO和FAIR。默认情况下Spark的调度模式是FIFO(先进先出),谁先提交谁先执行,后面的任务需要等待前面的任务执行,后面的任务需要等待前面的任务执行。
而FAIR(公平调度)模式支持在调度池中为任务进行分组,不同的调度池权重不同,任务可以按照权重来决定执行顺序。Spark的调度模式可以通过spark.scheduler.mode进行设置。
对这两种调度模式的具体实现,接下来会根据spark-1.6.0的源码来进行详细的分析。使用哪种调度器由参数 spark.scheduler.mode 来设置,可选的参数有FAIR和FIFO,默认是FIFO。
一、源码入口
在DAGScheluer对job划分好stage并以TaskSet的形式提交给TaskScheduler后,TaskScheduler的实现类会为每个TaskSet创建一个TaskSetMagager对象,并将该对象添加到调度池中:
//目前支持FIFO和FAIR两种调度策略
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
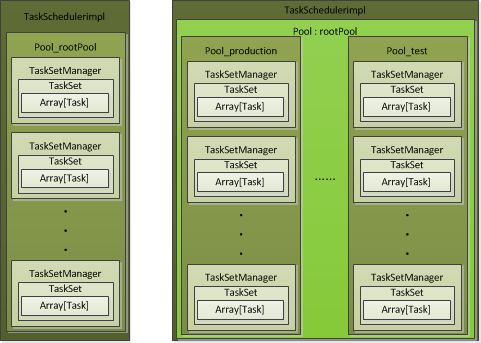
Spark中有两种可调度的实体,Pool和TaskSetManager。Pool是一个调度池,Pool里面还可以有子Pool,Spark中的rootPool即根节点默认是一个无名的Pool。
在上面代码中有一个schedulableBuilder对象,这个对象在TaskSchedulerImpl类中的定义及实现可以参考下面这段源代码:
var schedulableBuilder: SchedulableBuilder = null
...
def initialize(backend: SchedulerBackend) {
this.backend = backend
// temporarily set rootPool name to empty
rootPool = new Pool("", schedulingMode, 0, 0)
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
//rootPool包含了一组TaskSetManager
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
//rootPool包含了一组Pool树,这棵树的叶子节点都是TaskSetManager
new FairSchedulableBuilder(rootPool, conf)
}
}
schedulableBuilder.buildPools() //在FIFO中的实现是空
}
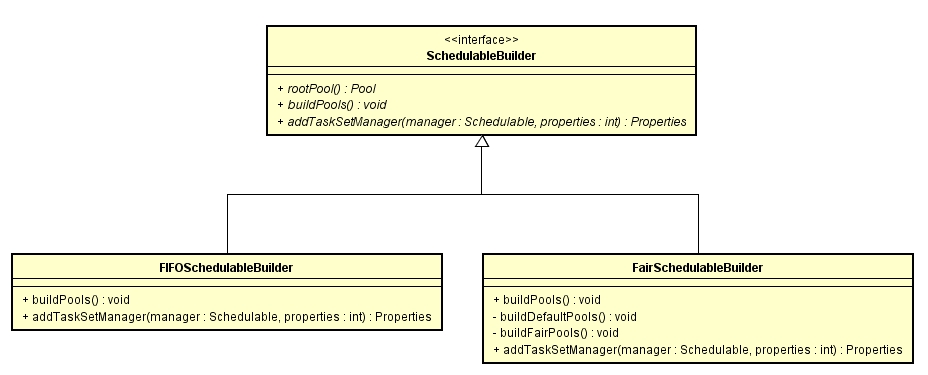
从上面可以看到会根据不同的mode创建不同的调度池,分别为FIFOSchedulableBuilder和FairSchedulableBuilder两种,在最后面调用了schedulableBuilder.buildPools()。
根据用户配置的SchedulingMode决定是生成FIFOSchedulableBuilder还是生成FairSchedulableBuilder类型的schedulableBuilder对象。
在生成schedulableBuilder后,调用其buildPools方法生成调度池。
调度模式由配置参数spark.scheduler.mode(默认值为FIFO)来确定。
两种模式的调度逻辑图如下:
二、FIFOSchedulableBuilder
FIFO的rootPool包含一组TaskSetManager。从上面的类继承图中看出在FIFOSchedulableBuilder中有两个方法:
1、buildPools
实现为空
override def buildPools() {
// nothing
}
所以,对于FIFO模式,获取到schedulableBuilder对象后,在调用buildPools方法后,不做任何操作。
2、addTaskSetManager
该方法将TaskSetManager装载到rootPool中。直接调用的方法是Pool#addSchedulable()。
override def addTaskSetManager(manager: Schedulable, properties: Properties) {
rootPool.addSchedulable(manager)
}
Pool#addSchedulable()方法:
val schedulableQueue = new ConcurrentLinkedQueue[Schedulable]
...
override def addSchedulable(schedulable: Schedulable) {
require(schedulable != null)
schedulableQueue.add(schedulable)
schedulableNameToSchedulable.put(schedulable.name, schedulable)
schedulable.parent = this
}
将该TaskSetManager加入到调度队列schedulableQueue中。
三、FairSchedulableBuilder
FAIR的rootPool中包含一组Pool,在Pool中包含了TaskSetManager。
1、buildPools
override def buildPools() {
var is: Option[InputStream] = None
try {
is = Option {
schedulerAllocFile.map { f =>
new FileInputStream(f)
}.getOrElse {
Utils.getSparkClassLoader.getResourceAsStream(DEFAULT_SCHEDULER_FILE)
}
}
//根据配置文件创建buildFairSchedulerPool
is.foreach { i => buildFairSchedulerPool(i) }
} finally {
is.foreach(_.close())
}
// finally create "default" pool
buildDefaultPool()
}
可以看到FairSchedulableBuilder会读取FAIR的配置文件,默认是在SPARK_HOME/conf/fairscheduler.xml,也可以通过参数spark.scheduler.allocation.file设置用户自定义配置文件。
SPARK_HOME/conf/fairscheduler.xml
<allocations>
<pool name="production">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>2</minShare>
</pool>
<pool name="test">
<schedulingMode>FIFO</schedulingMode>
<weight>2</weight>
<minShare>3</minShare>
</pool>
</allocations>
参数含义:
- name: 该调度池的名称,可根据该参数使用指定pool,入sc.setLocalProperty(“spark.scheduler.pool”, “test”)
- weight: 该调度池的权重,各调度池根据该参数分配系统资源。每个调度池得到的资源数为weight / sum(weight),weight为2的分配到的资源为weight为1的两倍。
- minShare: 该调度池需要的最小资源数(CPU核数)。fair调度器首先会尝试为每个调度池分配最少minShare资源,然后剩余资源才会按照weight大小继续分配。
- schedulingMode: 该调度池内的调度模式。
2、buildFairSchedulerPool
从上面的配置文件可以看到,每一个调度池有一个name属性指定名字,然后在该pool中可以设置其schedulingMode(可为空,默认为FIFO), weight(可为空,默认值是1), 以及minShare(可为空,默认值是0)参数。然后使用这些参数生成一个Pool对象,把该pool对象放入rootPool中。入下所示:
val pool = new Pool(poolName, schedulingMode, minShare, weight)
rootPool.addSchedulable(pool)
3、buildDefaultPool
如果如果配置文件中没有设置一个name为default的pool,系统才会自动生成一个使用默认参数生成的pool对象。各项参数的默认值在buildFairSchedulerPool中有提到。
4、addTaskSetManager
这一段逻辑中是把配置文件中的pool,或者default pool放入rootPool中,然后把TaskSetManager存入rootPool对应的子pool。
override def addTaskSetManager(manager: Schedulable, properties: Properties) {
var poolName = DEFAULT_POOL_NAME
var parentPool = rootPool.getSchedulableByName(poolName)
if (properties != null) {
poolName = properties.getProperty(FAIR_SCHEDULER_PROPERTIES, DEFAULT_POOL_NAME)
parentPool = rootPool.getSchedulableByName(poolName)
if (parentPool == null) {
// we will create a new pool that user has configured in app
// instead of being defined in xml file
parentPool = new Pool(poolName, DEFAULT_SCHEDULING_MODE,
DEFAULT_MINIMUM_SHARE, DEFAULT_WEIGHT)
rootPool.addSchedulable(parentPool)
logInfo("Created pool %s, schedulingMode: %s, minShare: %d, weight: %d".format(
poolName, DEFAULT_SCHEDULING_MODE, DEFAULT_MINIMUM_SHARE, DEFAULT_WEIGHT))
}
}
parentPool.addSchedulable(manager)
logInfo("Added task set " + manager.name + " tasks to pool " + poolName)
}
5、FAIR调度池使用方法
在Spark-1.6.1官方文档中写道:
如果不加设置,jobs会提交到default调度池中。由于调度池的使用是Thread级别的,只能通过具体的SparkContext来设置local属性(即无法在配置文件中通过参数spark.scheduler.pool来设置,因为配置文件中的参数会被加载到SparkConf对象中)。所以需要使用指定调度池的话,需要在具体代码中通过SparkContext对象sc来按照如下方法进行设置:
sc.setLocalProperty("spark.scheduler.pool", "test")
设置该参数后,在该thread中提交的所有job都会提交到test Pool中。
如果接下来不再需要使用到该test调度池,
sc.setLocalProperty("spark.scheduler.pool", null)
四、FIFO和FAIR的调度顺序
这里必须提到的一个类是上面提到的Pool,在这个类中实现了不同调度模式的调度算法。
var taskSetSchedulingAlgorithm: SchedulingAlgorithm = {
schedulingMode match {
case SchedulingMode.FAIR =>
new FairSchedulingAlgorithm()
case SchedulingMode.FIFO =>
new FIFOSchedulingAlgorithm()
}
}
FIFO模式的算法类是FIFOSchedulingAlgorithm,FAIR模式的算法实现类是FairSchedulingAlgorithm。
接下来的两节中comparator方法传入参数Schedulable类型是一个trait,具体实现主要有两个:1,Pool;2,TaskSetManager。与最前面那个调度模式的逻辑图相对应。
private[spark] trait SchedulingAlgorithm {
def comparator(s1: Schedulable, s2: Schedulable): Boolean
}
其实现类为FIFOSchedulingAlgorithm、FairSchedulingAlgorithm
1、FIFO模式的调度算法FIFOSchedulingAlgorithm
在这个类里面,主要逻辑是一个comparator方法。
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val priority1 = s1.priority //实际上是Job ID
val priority2 = s2.priority
var res = math.signum(priority1 - priority2)
if (res == 0) { //如果Job ID相同,就比较Stage ID
val stageId1 = s1.stageId
val stageId2 = s2.stageId
res = math.signum(stageId1 - stageId2)
}
if (res < 0) {
true
} else {
false
}
}
如果有两个调度任务s1和s2,首先获得两个任务的priority,在FIFO中该优先级实际上是Job ID。首先比较两个任务的Job ID,如果priority1比priority2小,那么返回true,表示s1的优先级比s2的高。我们知道Job ID是顺序生成的,先生成的Job ID比较小,所以先提交的job肯定比后提交的job先执行。但是如果是同一个job的不同任务,接下来就比较各自的Stage ID,类似于比较Job ID,Stage ID小的优先级高。
2、FAIR模式的调度算法FairSchedulingAlgorithm
这个类中的comparator方法源代码如下:
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val minShare1 = s1.minShare //在这里share理解成份额,即每个调度池要求的最少cpu核数
val minShare2 = s2.minShare
val runningTasks1 = s1.runningTasks // 该Pool或者TaskSetManager中正在运行的任务数
val runningTasks2 = s2.runningTasks
val s1Needy = runningTasks1 < minShare1 // 如果正在运行任务数比该调度池最小cpu核数要小
val s2Needy = runningTasks2 < minShare2
val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0).toDouble
val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0).toDouble
val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
var compare: Int = 0
if (s1Needy && !s2Needy) {
return true
} else if (!s1Needy && s2Needy) {
return false
} else if (s1Needy && s2Needy) {
compare = minShareRatio1.compareTo(minShareRatio2)
} else {
compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
}
if (compare < 0) {
true
} else if (compare > 0) {
false
} else {
s1.name < s2.name
}
}
minShare对应fairscheduler.xml配置文件中的minShare属性。
- 如果s1所在Pool或者TaskSetManager中运行状态的task数量比minShare小,s2所在Pool或者TaskSetManager中运行状态的task数量比minShare大,那么s1会优先调度。反之,s2优先调度。
- 如果s1和s2所在Pool或者TaskSetManager中运行状态的task数量都比各自minShare小,那么minShareRatio小的优先被调度。minShareRatio是运行状态task数与minShare的比值,即相对来说minShare使用较少的先被调度。
- 如果minShareRatio相同,那么最后比较各自Pool的名字。
五、 Demo
package spark
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}
/**
* spark的fair任务调度;
*/
object sparkSqlDemo {
case class Person(name:String,age:Int,city:String)
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
def main(args: Array[String]): Unit = {
val s = System.currentTimeMillis()
val conf = new SparkConf().setAppName("sparksql")
conf.set("spark.scheduler.mode","FAIR")
conf.set("spark.driver.allowMultipleContexts","true")
val sc = new SparkContext(conf)
sc.setLocalProperty("spark.scheduler.pool", "production")
val context = new SQLContext(sc)
val peopleRDD = sc.textFile("hdfs://master:9000/jason/test.txt")
.map(_.split(" "))
.filter(x=> !x.isEmpty)
.map(x => Person(x(0), x(1).toInt,x(2)))
import context.implicits._
val df = peopleRDD.toDF
df.createOrReplaceTempView("people")
val query_df = context.sql("select * from people")
println("第一个执行完了")
query_df.show()
val count_query = context.sql("select count(1) from people")
println("第二个执行完了")
count_query.show()
val test_1 = context.sql("select sum(age) from people")
println("第三个执行完了")
test_1.show()
val test_2 = context.sql("select avg(age) from people")
println("第四个执行完了")
test_2.show()
val test_3 = context.sql("select min(age),max(age),avg(age) from people")
println("第五个执行完了")
test_3.show()
val e = System.currentTimeMillis()
println("总共用时:" + (e-s))
}
}
然后我们提交这个任务,会在yarn上面看到如下的:
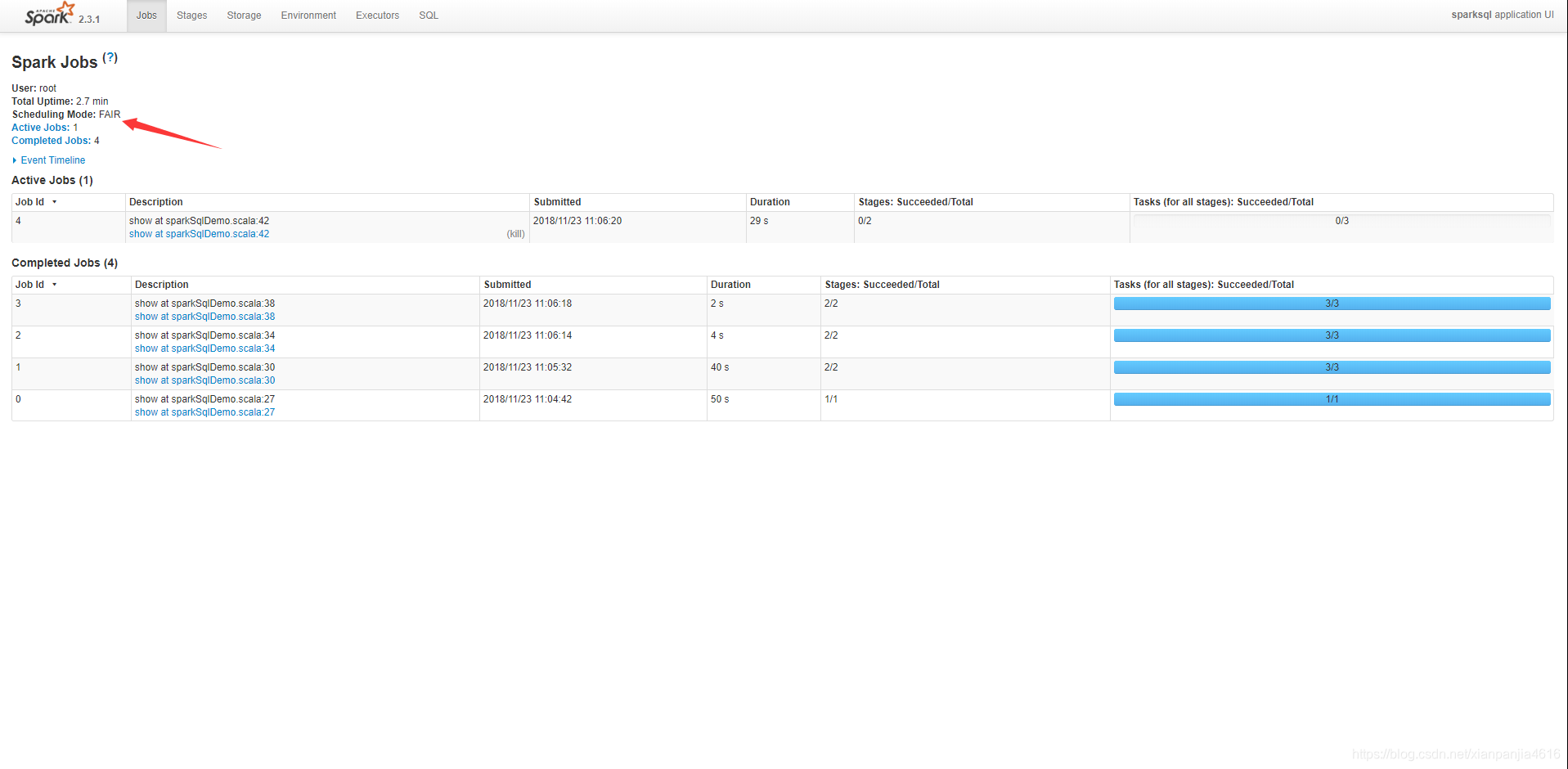
从这张图可以看到scheduling Mode是FAIR,这就说明spark的使用的是公平调度,然后点击stages,会看到下面的情况:
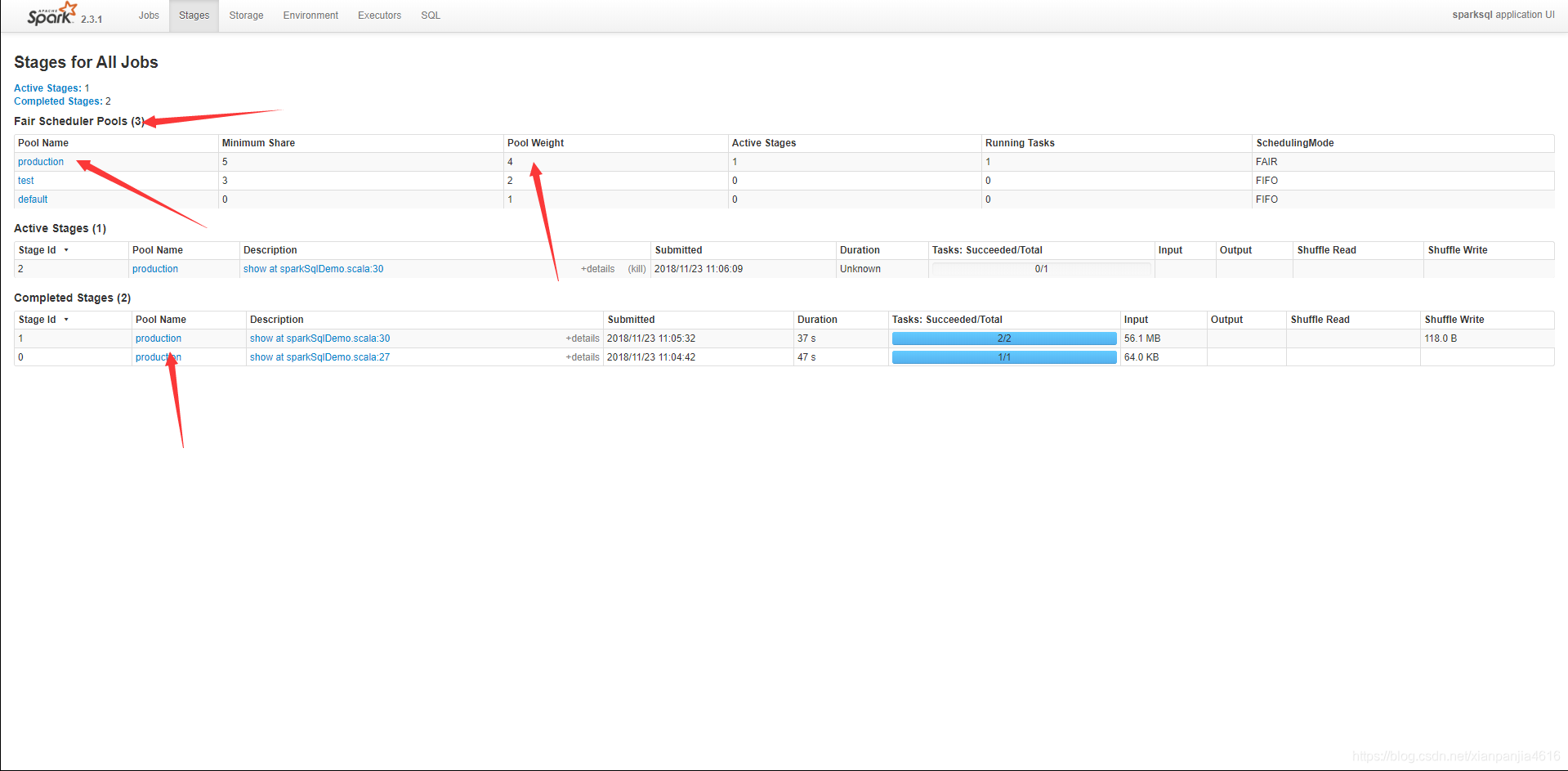
从这图可以看到我们刚才那个配置文件里面的pool,包括权重等配置.可以看到下面的stage都是运行在我们配置的调度池里面
参考资料:

















 3606
3606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









