







 本文探讨了主成分分析(PCA)和解释性因子分析(EFA)在市场研究中的应用。PCA用于从大量相关变量中提取不相关的主成分,数据探索显示存在latest/trendy/fun, serious/leader/perform, bargain/rebuy/value三类。因子分析旨在发现变量的潜在结构,3因子方案解释了57%的方差。文章还涉及因子数量确定、旋转方法和可视化技巧。"
121357024,10941275,Pandas数据清洗:缺失值、重复值和异常值处理,"['Python', '数据分析', '数据预处理']
本文探讨了主成分分析(PCA)和解释性因子分析(EFA)在市场研究中的应用。PCA用于从大量相关变量中提取不相关的主成分,数据探索显示存在latest/trendy/fun, serious/leader/perform, bargain/rebuy/value三类。因子分析旨在发现变量的潜在结构,3因子方案解释了57%的方差。文章还涉及因子数量确定、旋转方法和可视化技巧。"
121357024,10941275,Pandas数据清洗:缺失值、重复值和异常值处理,"['Python', '数据分析', '数据预处理']
主成分分析和因子分析
#包载入
library(corrplot)
library(psych)
library(GPArotation)
library(nFactors)
library(gplots)
library(RColorBrewer)主成分分析
主成分分析(PCA)是对针对大量相关变量提取获得很少的一组不相关的变量,这些无关变量也成为主成分变量。
数据探索
#本部分引入消费者品牌感知的问卷数据集作为数据
pca <- read.csv("http://r-marketing.r-forge.r-project.org/data/rintro-chapter8.csv")
summary(pca)
#可以看到,该数据除了一个字符变量外,其他都是1~10的数字变量
head(pca)
library(corrplot)
#检查两两变量之间的相关关系
corrplot(cor(pca[,1:9]), order = "FPC")
#"FPC" for the first principal component order.
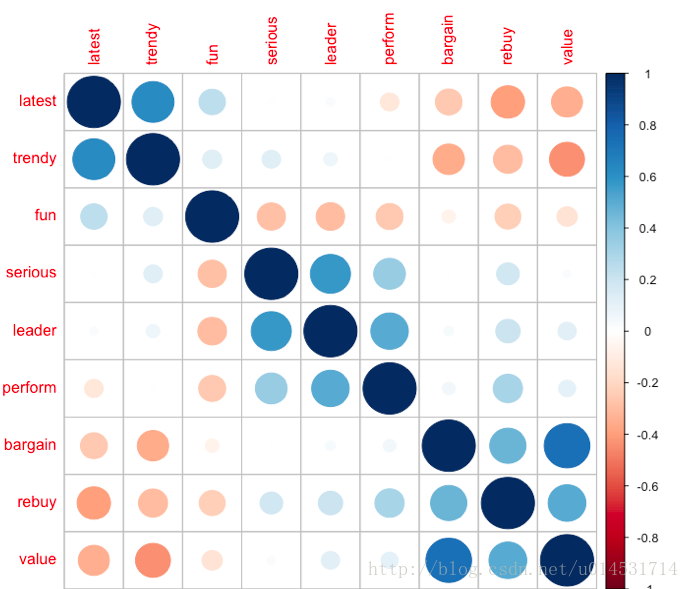
可以大致发现聚成了三个类别,分别是latest/trendy/fun,serious/leader/perform,bargain/rebuy/value三类,而这也是接下来的分析所要验证的。
提取主成分
#数据表度化
pca.sc <- pca
pca.sc[,1:9] <- scale(pca.sc[,1:9])
#提取主成分
pca.pc <- prcomp(pca.sc[,1:9])
summary(pca.pc)
#判断成分数量
plot(pca.pc, type = "l")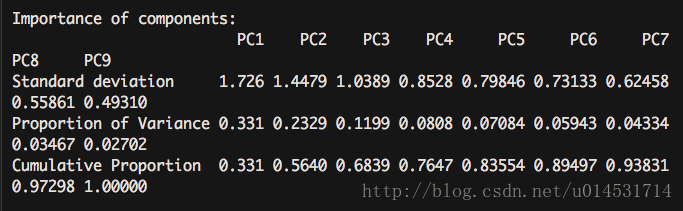
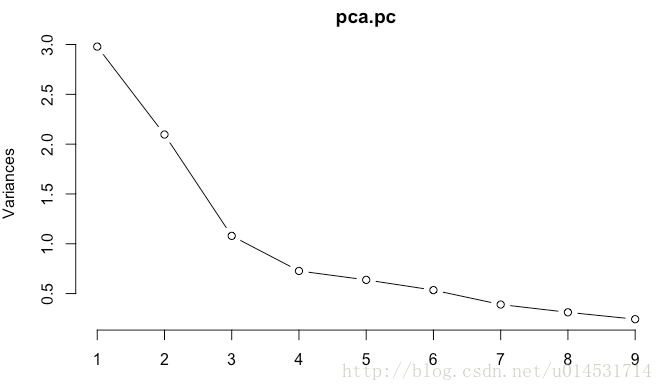
对于主成分数量,scree图可看到在3类之后,每个主成分解释的方差增值减少。
主成分得分获取
#psych包也有不错的PCA分析输出
library(psych)
fa.parallel(pca.sc[,1:9],fa =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6702
6702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









