









MINT: Multi-modal Chain of Thought in Unified Generative Models for Enhanced Image Generation

Figure 1: Visualization of images generated by MINT. (a) Images with various themes generated by MINT demonstrate its exceptional versatility while exhibiting extraordinary detail quality. (b) Integrated with Multimodal Chain of Thought (MCoT), MINT exhibits remarkable capabilities in understanding and reasoning about text-image relationships, effectively adhering to the interwoven conditions present in intricate imagery.
Unified generative models have demonstrated extraordinary performance in both text and image generation. However, they tend to underperform when generating intricate images with various interwoven conditions, which is hard to solely rely on straightforward text-to-image generation. In response to this challenge, we introduce MINT, an innovative unified generative model, empowered with native multimodal chain of thought (MCoT) for enhanced image generation for the first time. Firstly, we design Mixture of Transformer Experts (MTXpert), an expert-parallel structure that effectively supports both natural language generation (NLG) and visual capabilities, while avoiding potential modality conflicts that could hinder the full potential of each modality. Building on this, we propose an innovative MCoT training paradigm, a step-by-step approach to multimodal thinking, reasoning, and reflection specifically designed to enhance image generation. This paradigm equips MINT with nuanced, element-wise decoupled alignment and a comprehensive understanding of textual and visual components. Furthermore, it fosters advanced multimodal reasoning and self-reflection, enabling the construction of images that are firmly grounded in the logical relationships between these elements. Notably, MINT has been validated to exhibit superior performance across multiple benchmarks for text-to-image (T2I) and image-to-text (I2T) tasks.
统一的生成模型在文本和图像生成领域已展现出卓越的性能。然而,当面对复杂且交织多条件的图像生成任务时,这些模型往往表现欠佳,因为仅依靠简单的文本到图像生成方式难以满足需求。针对这一挑战,我们首次提出了一种创新的统一生成模型——MINT,该模型通过引入原生多模态思维链(MCoT)技术,显著提升了图像生成能力。
首先,我们设计了专家并行结构的混合Transformer专家(MTXpert),这一结构能够有效支持自然语言生成(NLG)和视觉能力,同时避免了模态冲突可能对各模态潜力发挥的阻碍。在此基础上,我们提出了一种创新的MCoT训练范式,这是一种逐步进行多模态思维、推理和反思的方法,专门用于增强图像生成。该范式使MINT具备了细致入微的元素级解耦对齐能力,以及对文本和视觉组件的全面理解。此外,它还促进了高级多模态推理和自我反思,使得生成的图像能够牢固地建立在这些元素之间的逻辑关系之上。
值得注意的是,MINT在多个文本到图像(T2I)和图像到文本(I2T)任务的基准测试中均表现出优异的性能,验证了其卓越的跨模态生成能力。
Introduction
Unified generative models (Kondratyuk et al., 2023; He et al., 2024; Bachmann et al., 2024; Zhou et al., 2024b) have recently demonstrated superior capabilities in understanding and generating multimodal information, e.g., linguistic and visual data. Prior works (Ding et al., 2021; Team, 2024b; Lu et al., 2024; Kondratyuk et al., 2023) employ next-token prediction frameworks that represent all modalities as discrete tokens to capture cross-modal interactions. However, such discrete tokenization approaches do not align with the continuous nature of images and videos, thereby limiting the generative potential.
To address these limitations, recent studies (Zhou et al., 2024b; Xiao et al., 2024; Ma et al., 2024) have explored hybrid generative models that process images as continuous data using diffusion manner and text as discrete data through an autoregressive manner. These models can achieve comparable and even superior performance to diffusion models in image generation tasks. However, as illustrated in Figure 2, when generating intricate images—particularly those with various interwoven conditions, a straightforward text-to-image (T2I) approach often falls short of meeting users’ expectations in a single attempt. This necessitates models with exceptionally strong fine-grained image-text alignment, concept-wise understanding, and reasoning capabilities, which is precisely what we anticipate unified generative models will ultimately achieve, due to their inherent advantage of multimodal information interaction within a single model. Therefore, a natural question arises: Is it feasible to harness the multimodal understanding, reasoning, and generative capabilities of unified generative models to effectively address such intricate and realistic multimodal challenges in a step-by-step manner?

近年来,统一的生成模型(Kondratyuk等,2023;He等,2024;Bachmann等,2024;Zhou等,2024b)在理解和生成多模态信息(如语言和视觉数据)方面展现出了卓越的能力。以往的研究(Ding等,2021;Team,2024b;Lu等,2024;Kondratyuk等,2023)采用基于下一词预测的框架,将所有模态表示为离散的token以捕捉跨模态的交互。然而,这种离散化的token表示方法与图像和视频的连续性本质不符,从而限制了生成模型的潜力。
为了解决这些局限性,最近的研究(Zhou等,2024b;Xiao等,2024;Ma等,2024)探索了混合生成模型,这些模型通过扩散方式将图像作为连续数据处理,同时通过自回归方式将文本作为离散数据处理。这些模型在图像生成任务中能够达到甚至超越扩散模型的性能。然而,如图2所示,当生成复杂的图像——尤其是那些包含多种交织条件的图像时,简单的文本到图像(T2I)方法往往无法在单次尝试中满足用户的期望。这要求模型具备极强的细粒度图文对齐能力、概念级理解能力以及推理能力,而这正是我们期待统一的生成模型最终能够实现的,因为它们具有在单一模型内进行多模态信息交互的天然优势。因此,一个自然的问题随之而来:是否可以利用统一的生成模型的多模态理解、推理和生成能力,以逐步的方式有效解决此类复杂且现实的多模态挑战?
In this paper, we introduce MINT, an innovative unified generative model, empowered by multimodal chain of thought (MCoT) for enhanced image generation. MCoT represents step-by-step multimodal thinking and reasoning, akin to the chain of thought (CoT) (Wei et al., 2022b), thereby further unlocking the multimodal potential of unified generative models. To achieve this, as shown in Figure 3, we firstly design the Mixture of Transformer Experts (MTXpert) as the core of MINT, which preserves the natural language processing capabilities of pretrained large language models while seamlessly endowing the model with exceptional visual understanding and generative abilities. Moreover, MTXpert, an expert-parallel design, avoids potential conflicts between different modalities that can occur in a single Transformer model (Liang et al., 2024a; Shi et al., 2024), thereby facilitating a comprehensive interplay and deep alignment between the textual and visual modalities, which is vital for unlocking multimodal thinking and reasoning.
Finally, and most importantly, to activate the inherent MCoT skill set of MINT, we propose an innovative MCOT training paradigm, as illustrated in Figure 3. Generating intricate images—such as those featuring multiple objects, complex spatial relationships, and various attributes that are all interwoven—requires nuanced, element-wise decoupled alignment and a deep understanding of textual and visual components. This process further entails the ability to fully comprehend the semantic connections among these elements and their corresponding text, thereby enabling the construction of images that are firmly grounded in the logical relationships between them. However, straightforward T2I generation is insufficient to effectively address these challenges. To overcome these limitations, we introduce the MCoT training paradigm to equip MINT with native MCoT capabilities. MCoT replaces the straightforward T2I process with step-by-step multimodal thinking, reasoning, and reflection, thereby alleviating the difficulties associated with generating intricate images. All MCoT steps are handled entirely within MINT as shown in Figure 3, where the planning and acting steps explicitly enhance fine-grained alignment between text and images, as well as the decoupling of visual elements. Furthermore, the reflection and correction steps enable the model to self-assess artifacts within the generated image and identify discrepancies between the image and the corresponding caption, which endows MINT with humanlike evaluative capabilities, further refining image details and ultimately improving the quality of image generation.
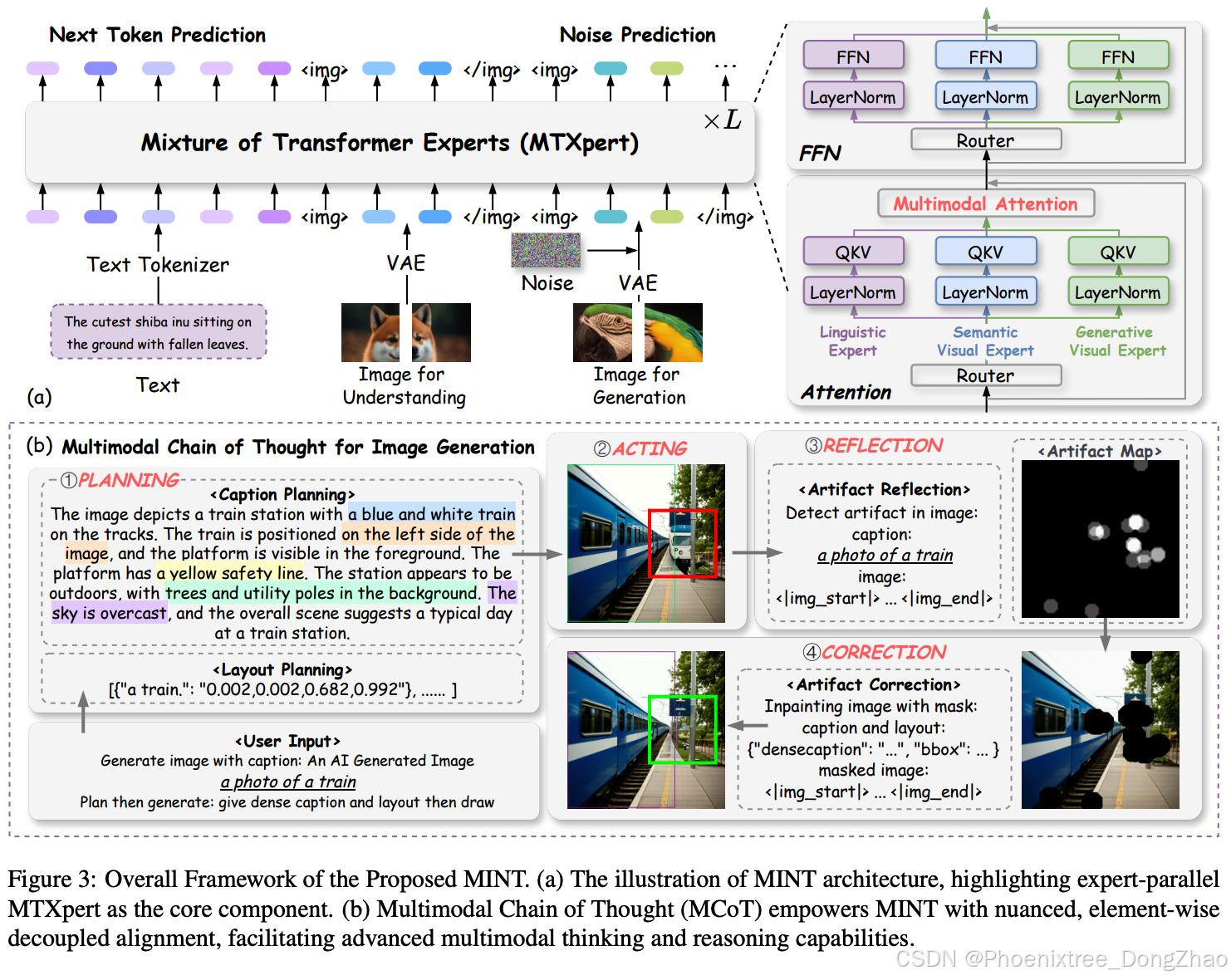
在本文中,我们介绍了一种创新的统一生成模型——MINT,该模型通过多模态思维链(MCoT)赋能,以增强图像生成能力。MCoT代表了逐步的多模态思维和推理过程,类似于思维链(CoT)(Wei等,2022b),从而进一步释放了统一生成模型的多模态潜力。为实现这一目标,如图3所示,我们首先设计了混合Transformer专家(MTXpert)作为MINT的核心,它保留了预训练大语言模型在自然语言处理方面的能力,同时无缝地赋予模型卓越的视觉理解和生成能力。此外,MTXpert采用专家并行设计,避免了单一Transformer模型中可能出现的不同模态之间的冲突(Liang等,2024a;Shi等,2024),从而促进了文本和视觉模态之间的全面交互和深度对齐,这对于解锁多模态思维和推理至关重要。
最后,也是最重要的,为了激活MINT内在的MCoT技能集,我们提出了一种创新的MCoT训练范式,如图3所示。生成复杂的图像——例如包含多个对象、复杂空间关系和交织属性的图像——需要细致入微的元素级解耦对齐以及对文本和视觉组件的深入理解。这一过程还要求模型能够充分理解这些元素及其对应文本之间的语义联系,从而构建出基于这些元素之间逻辑关系的图像。然而,简单的文本到图像(T2I)生成方法不足以有效应对这些挑战。为了克服这些局限性,我们引入了MCoT训练范式,使MINT具备原生MCoT能力。MCoT通过逐步的多模态思维、推理和反思取代了直接的T2I过程,从而缓解了生成复杂图像的困难。如图3所示,所有MCoT步骤均在MINT内部完成,其中规划和执行步骤显着增强了文本与图像之间的细粒度对齐以及视觉元素的解耦。此外,反思和修正步骤使模型能够自我评估生成图像中的瑕疵,并识别图像与对应描述之间的差异,这赋予了MINT类似人类的评估能力,进一步优化了图像细节,最终提升了图像生成的质量。
In general, our contributions can be summarized as follows:
• We introduce MINT, a unified generative model that seamlessly integrates understanding and generation capabilities of both textual and visual data. MINT decouples the model parameters associated with different tasks, specifically text generation, image understanding, and image generation, including feed-forward networks, attention matrices, and layer normalization. Further, it facilitates task-specific processing using global self-attention over the entire input sequence, resulting in superior performance in multimodal tasks and demonstrating the potential for expansion to any-to-any tasks.
• We propose the MCoT training paradigm to activate the native MCoT capabilities of unified generative models for the first time, thereby revealing previously untapped potential within large-scale text-image pre-training and demonstrating its effectiveness in enhancing performance for intricate and realistic multimodal challenges, such as intricate image generation.
• MINT demonstrates an enhanced ability in multimodal thinking and reasoning, enabling it to effectively break down complex problems and achieve exceptional performance, which is validated across a series of multimodal benchmarks, including GenEval, MS-COCO, VQA-v2, MME, and MMBench.
总的来说,我们的贡献可以总结如下:
• 我们提出了MINT,这是一种统一生成模型,能够无缝集成文本和视觉数据的理解和生成能力。MINT将不同任务(包括文本生成、图像理解和图像生成)相关的模型参数(如前馈网络、注意力矩阵和层归一化)解耦,并通过全局自注意力机制对输入序列进行任务特定的处理,从而在多模态任务中表现出色,并展示了扩展到任意任务之间的潜力。
• 我们首次提出了MCoT训练范式,以激活统一生成模型的原生MCoT能力,从而揭示了大规模文本-图像预训练中尚未开发的潜力,并证明了其在增强复杂且现实的多模态挑战(如复杂图像生成)性能方面的有效性。
• MINT在多模态思维和推理方面展现出增强的能力,使其能够有效分解复杂问题并取得卓越性能,这一能力在GenEval、MS-COCO、VQA-v2、MME和MMBench等一系列多模态基准测试中得到了验证。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









