







《A Correlated Topic Model Using Word Embeddings》
Abstract
传统的主题模型能够通过用逻辑正态分布代替先验的Dirichlet来捕捉潜在主题之间的相关结构。word embeddings 已经被证明能够捕捉语义规律,因此语义相关性和词之间的联系可以直接在词向量空间中计算(例如余弦值)得到。本文提出了一个新的使用词嵌入的主题模型。该模型能够利用词嵌入中包含的字级别的关联信息,并在连续的字嵌入空间中对主题相关性进行建模。在模型中,文档中的单词被替换为有意义的词嵌入,主题在词嵌入上被建模为多元高斯分布,并在连续的高斯主题中学习主题相关性。我们使用带有数据增强的Gibbs采样进行计算。我们在20NewsGroup和Reuters-21578两个数据集上定性和定量地评估我们的实验。实验结果表明了模型的有效性。
1 Introduction
传统的主题模型,比如概率潜在语义分析Probabilistic Latent Semantic Analysis (PLSA) [Hofmann, 1999] 和潜在的Dirichlet分布(LDA) [Blei et al., 2003] ,都被证明是一种强大的无监督文档收集和统计分析工具。这些模型 [Zhu et al., 2012],[Zhu et al., 2012] 都遵循词袋假设(bag-of-word),将每一个文档建模为潜在主题的混合,这些潜在主题是单词的多项分布。
传统模型的局限在于不能之间建模话题之间的相关性,比如,一个有关汽车的文档更可能与摩托车有关而与政治无关。实际上,在大多数文本语料库中,我们期望相关的潜在主题。为了解决这一局限性,相关主题模型Correlated Topic Model(CTM) [Blei and Lafferty, 2006a] 用逻辑正态分布取代了Dirichlet,这使得主题之间有协方差结构。
如今,自然语言处理技术——词嵌入Word embeddings [Bengio et al., 2003], [Mikolov and Dean, 2013] 的快速发展,为我们提供了在连续语义空间中对主题和主题相关性建模的可能性。词嵌入也被称为词向量和词的分布式表示,是词实值的连续向量能够有效地捕捉语言中的语义规律。具有相似语义和语法属性的词,在向量空间中往往会被投影在相近区域。通过使用连续词嵌入代替LDA中原始离散的词类型,Gaussian-LDA [Das et al., 2015] 已经证明,词嵌入中的附加语义可以被合并到主题模型中,并且能够进一步增强性能。
相关主题模型的主要目标是对主题之间的关联进行建模和发现。现在我们知道词嵌入能够捕捉语言中的语义规律,单词之间的相关性能够通过词向量之间的欧几里得距离或者余弦值直接计算得到。而且,语义相关的词在空间上彼此接近,应该更有可能被归入同一个主题。由于高斯分布描绘了连续空间中心性的概念,因此很自然地将主题建模为空间中的词嵌入的高斯分布。因此,本文的动机是在词嵌入空间中对主题进行建模,利用已知的词层面的相关信息,进一步提高话题层面的相关发现。
在本文中,我们提出了高斯主题相关性模型(CGTM)来建模词嵌入空间中的主题和主题相关性。更具体地说,首先借助外部大型非结构化文本语料库来学习单词嵌入,以获得额外的单次级关联信息;其次,在词嵌入的向量空间中,我们建立主题和主题相关的模型,以利用词嵌入中有用的语义信息,其中每个主题表示为词嵌入上的高斯分布,在这些高斯主题中学习主题相关性;第三,我们为CGTM开发了一个Gibbs抽样算法。
为了验证模型的有效性,我们在20NewsGroup和Reuters-21578数据集上评估我们的模型,这两个都是在文本挖掘领域实验中著名的数据集。实验表明,相比于基线模型,我们的模型能发现更加合理的主题和主题之间的关联。
2 Related Works
相关性是许多文本语料库的一个固有属性,例如[Blei and Lafferty, 2006b]探讨了主题的时间演变,[Mei et al., 2008] 分析了主题之间的位置相关性。但是,由于使用了Dirichlet先验,传统的主题模型不能直接对主题相关性进行建模。CTM [Blei and Lafferty, 2006a] 提出使用逻辑正态分布来建模主题比例的变化,从而学习主题的协方差结构。
词嵌入可以通过低维实值向量来捕捉单词的语义 [Mikolov and Dean, 2013] ,比如向量运算
vector(′king′)−vector(′man′)+vector(′woman′)=vector(′queen′)
。词嵌入的概念首先由神经概率语言模型(NPLM)[Bengio et al., 2003] 引入自然语言处理。由于其有效性和广泛的应用领域,词嵌入已经获得了很大的关注和发展 [Mikolov et al., 2013], [Pennington et al., 2014], [Morin and Bengio, 2005], [Collobert and Weston, 2008], [Mnih and Hinton, 2009], [Huang et al., 2012] 。
由于词嵌入带有额外的语义信息,许多研究者试图将其纳入到主题模型中以提高性能 [Das et al., 2015], [Li et al., 2016], [Liu et al., 2015], [Li et al., 2017] 。 [Liu et al., 2015] 等人提出了一种结合词嵌入和主题模型的主题词嵌入TWE,从而实现每个词的局部嵌入。[Das et al., 2015] 使用高斯分布来模拟词语嵌入空间中的主题。
上述模型要么不能直接模拟主题之间的相关性,要么无法利用单词级的语义和相关性。我们提出利用词嵌入的单词级语义和相关性来帮助学习主题级的相关性。
3 Learning Word Embeddings
我们通过语义规律来学习词嵌入,并进行话题发现。不同于传统的one-hot representation,分布式表示将每个单词编码为唯一的实值向量。通过将词映射到这个向量空间中,词嵌入能够克服one-hot representation的一些缺点,例如维数灾难,语义缺乏等。
在本文中,我们使用基于word2vec [Mikolov and Dean, 2013] 模型的单词分布式表示方法来训练词向量。在word2vec的学习过程中,具有相似含义的单词在向量空间中逐渐向附近区域聚合。在这个模型中,向量形式的词被用作softmax分类器的输入,基于特定上下文窗口词预测目标词。
在学习了词嵌入后,给定一个词
wdn
,其表示在第
dth
文档中第
nth
词,我们可以通过将其替换为相关的单词嵌入来丰富该词。下面一部分我们将介绍如何在生成过程中使用这种丰富性来为主题和主题相关性建模。
4 Generative Process
训练好的词向量为我们提供了有用的附加语义,这有助于我们在向量空间中发现合理的主题和主题相关性。但是,现在每个文档都是连续的单词嵌入序列,而不是一个分离的单词类型序列。因此传统的主题模型不再适用。受到[Hu et al., 2012] 和 [Das et al., 2015] 的启发,由于词嵌入是位于基于语义和句法的空间中的,我们认为他们是从多个高斯分布中提取出来的。因此,每个主题的特点是向量空间中的多元高斯分布。选择高斯分布可以通过观察词嵌入之间的欧几里得距离与其语义相似性一致而得到证明。
CGTM的模型如图1所示。
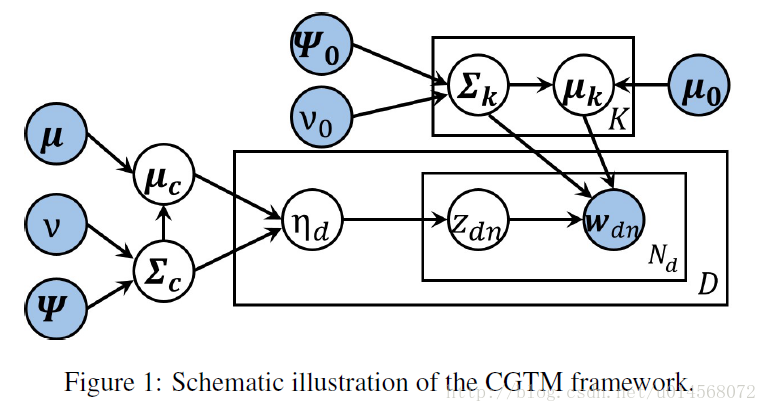
有
K
个主题,每个主题由向量空间中的单词嵌入的多元高斯分布表示。
注意,粗体字的变量表示他们是向量或者矩阵,例如
- ∑c∼W−1(Ψ,v)
- μc∼N(μ,1τc∑c)
- 对于每一个高斯主题
k=1,2,...,K
:
(a) 主题方差 ∑k∼W−1(Ψ0,v0) 。
(b) 主题均值 μk∼N(μ0,1τ∑k) - 对于每一篇文档
d=1,2,...,D
:
(a) ηd∼N(μc,∑c) 。
(b) 对于每一个单词下标 n=1,2,...,Nd :
i. 一个主题 zdn∼Multinomial(f(ηd))
ii. 一个单词 wdn∼N(μzdn,∑zdn)
其中
τ
和
τc
是常数,
f(η)
是逻辑变换:
主题参数使用以下共轭先验:高斯分布 N 计算平均值,逆Wishart分布 W−1 计算协方差。但是,逻辑正态分布和多项式分布之间仍然会存在一个非共轭问题,我们将在下一节使用数据增强技术来解决这个问题。
5 Parameter Inference
变量是由词嵌入组成的文档,我们的目标是推断每个主题的后验高斯分布、每个词的主题分配和主题相关性。给定文档
D
和相应的词嵌入
5.1 采样主题分配
5.2 更新高斯主题
5.3 采样逻辑正态参数
5.4 更新主题相关性
给定 {ηd}Dd=1 ,逻辑正态参数














 1159
1159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









